







 本文围绕Linux文件系统展开,介绍了VFS中inode和dentry的概念。inode包含文件元数据,有磁盘、内存和VFS三种形式;dentry用于路径名查找。还阐述了struct inode的字段、链表,inode_operations结构体及相关函数,以及inode cache的机制、初始化和查看方法,以提升文件系统性能。
本文围绕Linux文件系统展开,介绍了VFS中inode和dentry的概念。inode包含文件元数据,有磁盘、内存和VFS三种形式;dentry用于路径名查找。还阐述了struct inode的字段、链表,inode_operations结构体及相关函数,以及inode cache的机制、初始化和查看方法,以提升文件系统性能。
文章目录
前言
这篇文章介绍了VFS - struct file:Linux文件系统 struct file 结构体解析
接下来介绍VFS - struct inode:
在Linux内核的虚拟文件系统(VFS)中,一个dentry(目录项)通常包含一个指向inode的指针。inode是文件系统中的对象,例如常规文件、目录、FIFO(命名管道)等。inode可以存在于磁盘上(用于块设备文件系统)或内存中(用于伪文件系统)。当需要时,磁盘上的inode会被复制到内存中,并且对inode的更改会被写回磁盘。一个inode可以被多个dentry指向(例如,硬链接就是这样)。
要查找一个inode,VFS需要调用父目录inode的lookup()方法。这个方法由inode所在的具体文件系统实现安装。一旦VFS获取到所需的dentry(从而获取到inode),我们就可以执行诸如使用open()打开文件或使用stat()查看inode数据等常见操作。stat()操作相对简单:一旦VFS获得了dentry,它会查看inode数据并将其中的一部分返回给用户空间。
总体而言,VFS通过抽象底层细节并提供对inode和dentry的通用操作,为不同类型的文件系统提供了统一的接口。这样做可以方便地与文件系统进行交互。
下图描述结构体之间的关联:
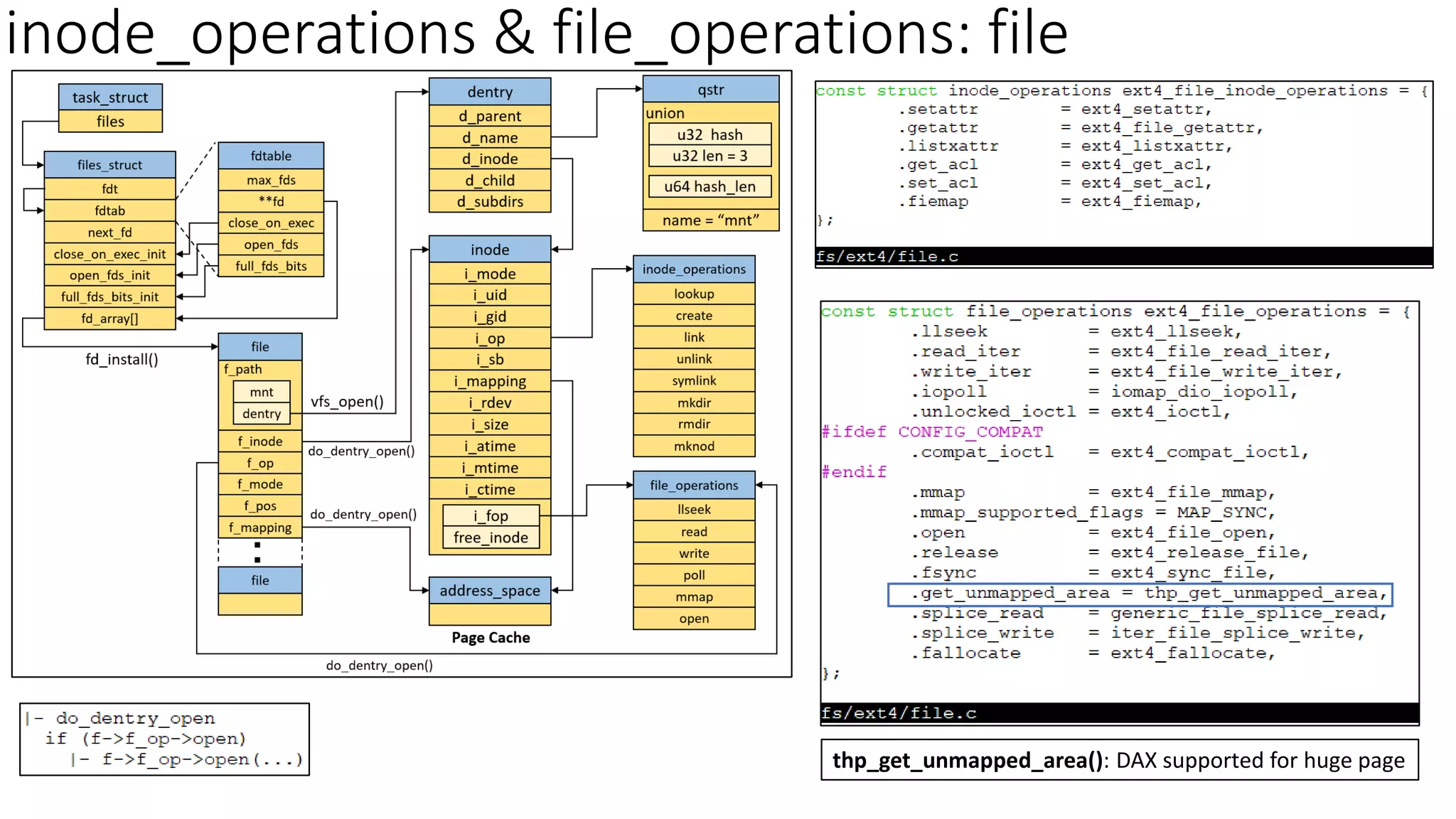
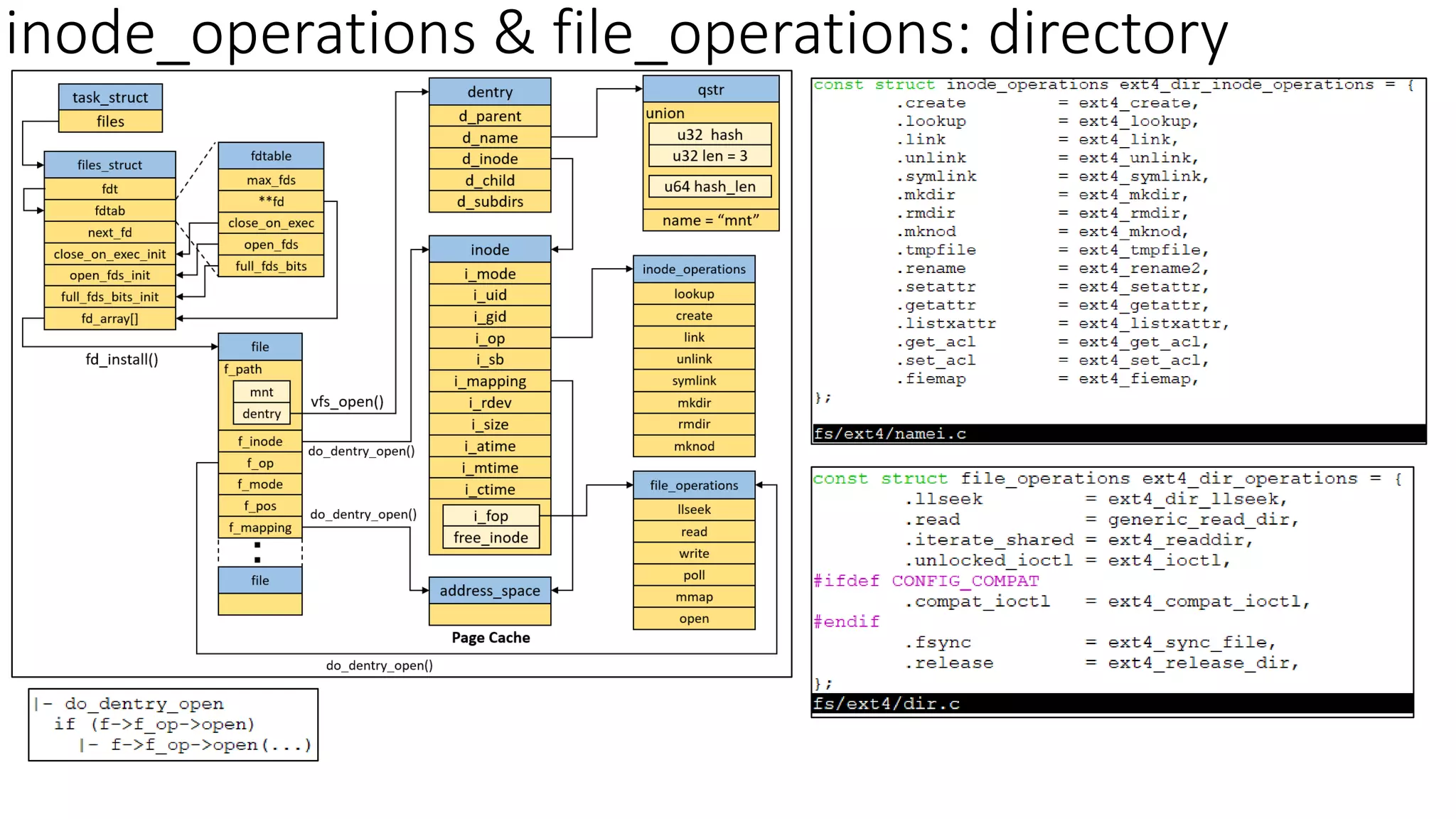
一、inode 简介
1.1 VFS与具体文件系统inode
inode包含了文件系统各种对象(文件、目录、块设备文件、字符设备文件等)的元数据。每个文件和目录在文件系统中都有一个唯一的索引节点号(Inode number),用于标识和引用该文件或目录。索引节点号在文件系统中是唯一的,通过它可以准确地找到对应的索引节点。
根据inode号查找文件的过程:
根目录下的各个目录项 --> 文件名 --> inode编号 --> inode结构体信息 --> inode元数据
--> 文件的实际数据内容
索引节点存储了与文件或目录相关的元数据信息,包括文件类型、权限、所有者、大小、时间戳等。这些元数据信息描述了文件的属性和特征。
inode的成员通常分为下面两类:
(1) 描述文件状态的元数据。例如,文件类型、权限、所有者、大小、时间戳等。
(2) 保存实际文件内容的数据段(或指向数据的指针),通常是指向数据的指针。当文件内容是符号链接的时候,并且大小不超过60字节,inode直接保存文件的数据段,不需要数据块。避免更多的磁盘访问来获取数据,从而增加了查找时间。
对于基于磁盘的文件系统,inode存在于磁盘上,其形式取决于文件系统的类型。在打开该对象进行访问时,其inode被读入内存。在打开对象时,还根据文件系统类型和对象类型设置inode操作表和file操作表。
内存中inode有一部分是各种文件系统共有的,通常称为VFS inode,即索引节点对象。
之后对VFS inode的任何修改都将写回磁盘更新磁盘的索引节点。
一个索引节点代表了文件系统的一个文件,在文件创建时创建文件删除时销毁,但是索引节点对象(VFS inode)仅在当文件被访问时,才在内存中创建,且无论有多少个副本访问这个文件,inode只存在一份,VFS inode也只存在一份。
索引节点占用磁盘空间,VFS inode占用内存空间。
VFS inode是各种具体文件系统的inode对象的抽象,对于具体的文件系统,另外有两种形式的inode,一种是内存inode,另一种是磁盘inode。两者之间相互转换,用在不同的场合下。
因此有三种inode:
(1)磁盘上具体的文件系统的inode。
(2)内存中具体的文件系统的inode,具体的文件系统的索引节点对象,需要包括VFS inode。
(3)VFS inode,索引节点对象。
比如ext4文件系统:
磁盘上ext4文件系统的inode:
// linux-5.4.18/fs/ext4/ext4.h
/*
* Constants relative to the data blocks
*/
#define EXT4_NDIR_BLOCKS 12
#define EXT4_IND_BLOCK EXT4_NDIR_BLOCKS
#define EXT4_DIND_BLOCK (EXT4_IND_BLOCK + 1)
#define EXT4_TIND_BLOCK (EXT4_DIND_BLOCK + 1)
#define EXT4_N_BLOCKS (EXT4_TIND_BLOCK + 1)
/*
* Structure of an inode on the disk
*/
struct ext4_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size_lo; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Inode Change time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks_lo; /* Blocks count */
__le32 i_flags; /* File flags */
......
__le32 i_block[EXT4_N_BLOCKS];/* Pointers to blocks */
}
其中i_block是指向文件数据块的指针,保存了文件数据块的地址。
inode在某一些情况下是能够将数据存储在inode本身中。这叫做Inlining。这种存储方法具有节省空间的优点,因为不需要数据块。它还通过避免更多的磁盘访问来获取数据,从而增加了查找时间。
像ext4这样的一些文件系统有一个名为inline_data的选项。启用后,它允许操作系统以这种方式存储数据。由于大小限制,内联只适用于非常小的文件。如果大小不超过60字节,Ext2和更高版本通常会以这种方式存储软链接信息。
EXT4_N_BLOCKS = 15
i_block的大小 = 4 * 15 = 60
内存中ext4文件系统的inode:
/*
* fourth extended file system inode data in memory
*/
struct ext4_inode_info {
......
struct inode vfs_inode;
......
}
inode描述了Linux VFS层使用的inode对象。对于具体的文件系统,需要定义自己的索引节点对象,定义时以VFS inode作为一个域。
VFS inode:
/*
* Keep mostly read-only and often accessed (especially for
* the RCU path lookup and 'stat' data) fields at the beginning
* of the 'struct inode'
*/
struct inode {
......
}
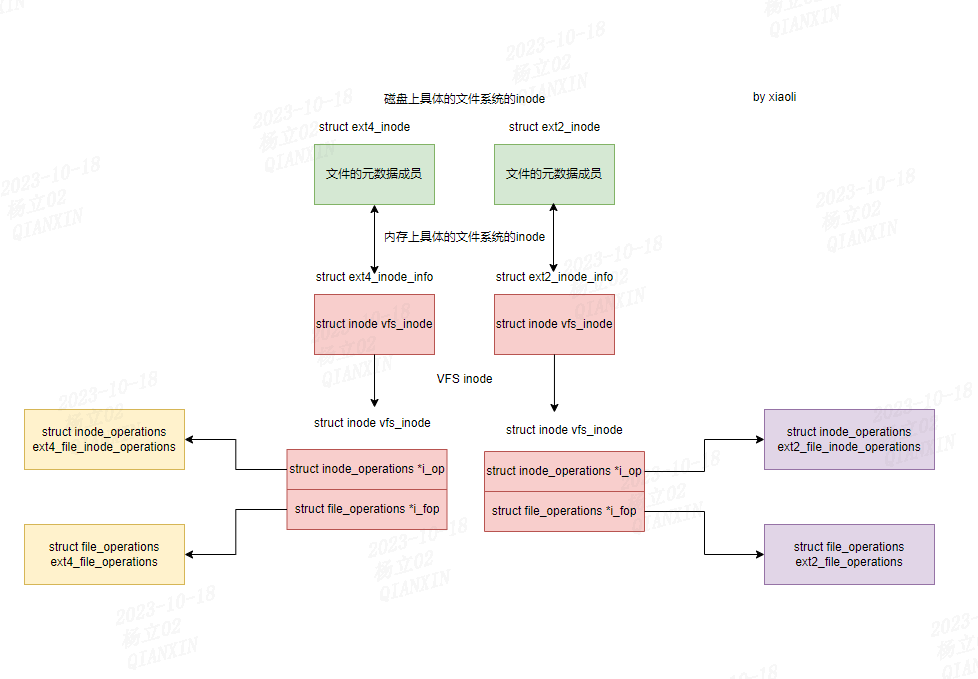
如下图所示:
const struct file_operations ext4_file_operations = {
.llseek = ext4_llseek,
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
.unlocked_ioctl = ext4_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = ext4_compat_ioctl,
#endif
.mmap = ext4_file_mmap,
.mmap_supported_flags = MAP_SYNC,
.open = ext4_file_open,
.release = ext4_release_file,
.fsync = ext4_sync_file,
.get_unmapped_area = thp_get_unmapped_area,
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.fallocate = ext4_fallocate,
};
const struct inode_operations ext4_file_inode_operations = {
.setattr = ext4_setattr,
.getattr = ext4_file_getattr,
.listxattr = ext4_listxattr,
.get_acl = ext4_get_acl,
.set_acl = ext4_set_acl,
.fiemap = ext4_fiemap,
};
从上文中我们可以知道 ,struct ext4_inode_info结构体是ext4文件系统在内存中inode的表示,该格式是在 vfs inode 之上进行扩展的:
/*
* fourth extended file system inode data in memory
*/
struct ext4_inode_info {
......
struct inode vfs_inode;
......
}
struct inode vfs_inode结构体是struct ext4_inode_info结构体的一个成员,因此我们可以通过struct inode vfs_inode来获取struct ext4_inode_info,借助于container_of宏(用于从结构体的成员指针获取整个结构体的指针。):
static inline struct ext4_inode_info *EXT4_I(struct inode *inode)
{
return container_of(inode, struct ext4_inode_info, vfs_inode);
}
分配 inode 的时候,其实分配的是 ext4_inode_info 结构体,包含了 vfs inode,然后对外给出去 vfs_inode 字段的地址即可。VFS 层拿 inode 的地址使用,底下文件系统强转类型后,取外层的 inode 地址使用。
static const struct super_operations ext4_sops = {
.alloc_inode = ext4_alloc_inode,
......
}
// linux-5.4.18/fs/ext4/super.c
static struct kmem_cache *ext4_inode_cachep;
/*
* Called inside transaction, so use GFP_NOFS
*/
static struct inode *ext4_alloc_inode(struct super_block *sb)
{
struct ext4_inode_info *ei;
//使用slub分配器分配struct ext4_inode_info结构体
ei = kmem_cache_alloc(ext4_inode_cachep, GFP_NOFS);
if (!ei)
return NULL;
......
//struct ext4_inode_info 结构体初始化
......
//返回 struct inode 索引节点对象指针
return &ei->vfs_inode;
}
static int __init init_inodecache(void)
{
ext4_inode_cachep = kmem_cache_create_usercopy("ext4_inode_cache",
sizeof(struct ext4_inode_info), 0,
(SLAB_RECLAIM_ACCOUNT|SLAB_MEM_SPREAD|
SLAB_ACCOUNT),
offsetof(struct ext4_inode_info, i_data),
sizeof_field(struct ext4_inode_info, i_data),
init_once);
if (ext4_inode_cachep == NULL)
return -ENOMEM;
return 0;
}
inode 的内存由具体的文件系统(比如ext4)分配,vfs inode 结构体内嵌在不同的文件系统的 inode 之中。不同的层次用不同的地址,ext4 文件系统用 ext4_inode_info 的结构体的地址,vfs 层用 ext4_inode_info.vfs_inode 字段的地址。
所有文件系统共性的东西抽象到 vfs inode ,不同文件系统差异的东西放在各自的 inode 结构体中。
1.2 总结
索引节点对象(struct inode)代表着一个具体的文件。索引节点对象在Linux内核中表示所有内核操作文件或目录所需的信息。对于类Unix风格的文件系统,这些信息直接从磁盘上的inode读取。然而,对于没有使用inode的文件系统,文件系统需要从磁盘的其他位置获取所需的信息。
在传统的Unix文件系统中,磁盘上的inode包含有关文件或目录的元数据,如大小、所有权、权限、时间戳以及指向存储文件实际内容的数据块的指针。内核操作文件或目录所需的信息可以直接从磁盘索引节点直接读入。
Linux内核中的inode对象反映了这个结构,并保存了内存中磁盘上inode的表示。
比如,对于ext4文件系统,内核操作文件或目录所需的信息时,索引节点对象struct inode直接从磁盘上的inode - struct ext4_inode(Structure of an inode on the disk) 中读取。
当访问或修改文件或目录时,内核与inode对象交互以执行必要的操作。inode对象跟踪文件的各种属性和状态,包括大小、时间戳、链接计数、所有权和其他相关信息。后续会将修改的内容写回磁盘更新磁盘的索引节点。
值得注意的是,并非所有的Linux文件系统都必须使用inode。一些现代文件系统,如Btrfs或ZFS,使用不同的数据结构来表示文件和目录。然而,inode对象的概念仍然是Linux内核文件管理系统的基本组成部分,为跨不同文件系统访问和操作文件提供了统一的接口。
二、dentry 简介
VFS实现了open()、stat()、chmod()等系统调用。这些系统调用中传递的路径名参数被VFS用于通过目录项缓存(也称为dentry缓存或dcache)进行搜索。这提供了一种非常快速的查找机制,将路径名(文件名)转换为特定的dentry。Dentries存在于RAM中,从不保存到磁盘:它们仅存在于性能优化的目的。
目录项缓存旨在提供对整个文件空间的视图。由于大多数计算机无法同时将所有的dentry都放入RAM中,因此缓存中可能会缺少一部分数据。为了将路径名解析为dentry,VFS可能需要在路径上创建dentry,并加载相应的inode。这是通过查找inode来完成的。
当VFS遇到一个路径名时,它首先会查看目录项缓存,看是否存在所需的dentry。如果存在,它可以直接使用该dentry并加载相应的inode。但是,如果目录项缓存中没有所需的dentry,VFS需要进行一系列的操作来解析路径名。
首先,VFS会从根目录开始,通过调用父目录inode的lookup()方法来查找下一个目录项。这个过程会递归地进行,直到找到路径名中的最后一个目录项。
在这个过程中,VFS会创建新的dentry,并将其插入到目录项缓存中,以便以后再次使用。然后,VFS会加载与新创建的dentry对应的inode,并将其与dentry关联起来。
通过递归查找和创建dentry,VFS最终能够将路径名解析为一个特定的dentry,并加载相应的inode。
需要注意的是,目录项缓存是一个动态的结构,它会根据系统的需求进行调整和更新。当系统资源有限时,VFS可能会根据某种策略选择要保留在缓存中的dentry,以提高整体性能。
总结起来,VFS通过目录项缓存提供了一个快速的查找机制,将路径名转换为特定的dentry,并通过查找inode来加载相应的文件。这样可以提高文件系统操作的效率。
三、struct inode
3.1 字段说明
/*
* Keep mostly read-only and often accessed (especially for
* the RCU path lookup and 'stat' data) fields at the beginning
* of the 'struct inode'
*/
struct inode {
umode_t i_mode;
unsigned short i_opflags;
kuid_t i_uid;
kgid_t i_gid;
unsigned int i_flags;
#ifdef CONFIG_FS_POSIX_ACL
struct posix_acl *i_acl;
struct posix_acl *i_default_acl;
#endif
const struct inode_operations *i_op;
struct super_block *i_sb;
struct address_space *i_mapping;
#ifdef CONFIG_SECURITY
void *i_security;
#endif
/* Stat data, not accessed from path walking */
unsigned long i_ino;
/*
* Filesystems may only read i_nlink directly. They shall use the
* following functions for modification:
*
* (set|clear|inc|drop)_nlink
* inode_(inc|dec)_link_count
*/
union {
const unsigned int i_nlink;
unsigned int __i_nlink;
};
dev_t i_rdev;
loff_t i_size;
struct timespec64 i_atime;
struct timespec64 i_mtime;
struct timespec64 i_ctime;
spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */
unsigned short i_bytes;
u8 i_blkbits;
u8 i_write_hint;
blkcnt_t i_blocks;
#ifdef __NEED_I_SIZE_ORDERED
seqcount_t i_size_seqcount;
#endif
/* Misc */
unsigned long i_state;
struct rw_semaphore i_rwsem;
unsigned long dirtied_when; /* jiffies of first dirtying */
unsigned long dirtied_time_when;
struct hlist_node i_hash;
struct list_head i_io_list; /* backing dev IO list */
#ifdef CONFIG_CGROUP_WRITEBACK
struct bdi_writeback *i_wb; /* the associated cgroup wb */
/* foreign inode detection, see wbc_detach_inode() */
int i_wb_frn_winner;
u16 i_wb_frn_avg_time;
u16 i_wb_frn_history;
#endif
struct list_head i_lru; /* inode LRU list */
struct list_head i_sb_list;
struct list_head i_wb_list; /* backing dev writeback list */
union {
struct hlist_head i_dentry;
struct rcu_head i_rcu;
};
atomic64_t i_version;
atomic_t i_count;
atomic_t i_dio_count;
atomic_t i_writecount;
#if defined(CONFIG_IMA) || defined(CONFIG_FILE_LOCKING)
atomic_t i_readcount; /* struct files open RO */
#endif
union {
const struct file_operations *i_fop; /* former ->i_op->default_file_ops */
void (*free_inode)(struct inode *);
};
struct file_lock_context *i_flctx;
struct address_space i_data;
struct list_head i_devices;
union {
struct pipe_inode_info *i_pipe;
struct block_device *i_bdev;
struct cdev *i_cdev;
char *i_link;
unsigned i_dir_seq;
};
__u32 i_generation;
#ifdef CONFIG_FSNOTIFY
__u32 i_fsnotify_mask; /* all events this inode cares about */
struct fsnotify_mark_connector __rcu *i_fsnotify_marks;
#endif
#ifdef CONFIG_FS_ENCRYPTION
struct fscrypt_info *i_crypt_info;
#endif
#ifdef CONFIG_FS_VERITY
struct fsverity_info *i_verity_info;
#endif
void *i_private; /* fs or device private pointer */
} __randomize_layout;
i_mode:该字段表示文件的访问权限和类型。它包括读取、写入和执行权限的信息,以及条目是否为常规文件、目录、符号链接等。
i_opflags:该字段包含提供有关索引节点及其操作的附加信息的标志。
i_uid和i_gid:这些字段分别存储文件所有者的用户ID(UID)和组ID(GID)。
i_flags:该字段存储与索引节点关联的各种标志,例如是否为不可变的、仅追加的或大文件。
i_acl和i_default_acl:这些字段是指向与文件关联的POSIX访问控制列表(ACL)的指针。ACL提供了超出传统Unix权限的细粒度访问控制。
Linux中的ACL(Access Control List)是一种扩展文件权限模型,允许更精细地控制文件和目录的访问权限。ACL可以为文件或目录添加额外的访问规则,以授权特定用户或用户组具有特定的权限。
i_op:该字段是指向类型为struct inode_operations的结构的指针,该结构包含可在索引节点上执行的各种操作的函数指针。
i_sb:该字段是指向与索引节点关联的超级块的指针。超级块表示文件系统实例,并包含有关文件系统的信息,例如其类型、块大小和挂载设备。
i_mapping:该字段是指向与索引节点关联的地址空间对象的指针。地址空间管理文件数据与磁盘块之间的映射。是用于描述页高速缓存中的页面的一个文件对应一个address_space,一个address_space与一个偏移量能够确定一个也高速缓存中的页面。i_mapping通常指向i_data,不过两者是有区别的,i_mapping表示应该向谁请求页面,i_data表示被该inode读写的页面。
i_security:该字段是指向与索引节点关联的与安全相关的信息的指针。它由安全模块用于存储附加的安全属性。
i_ino:该字段存储索引节点号,这是文件系统内唯一的标识符。每个VFS inode(对给定的文件系统)都由一个唯一的编号标识,保存在i_ino中。
i_nlink:指向索引节点的硬链接数。文件系统应直接读取此字段,但使用特定的函数进行修改。
i_rdev:如果索引节点表示特殊文件(例如字符设备或块设备),则该字段存储与文件关联的设备号。在inode表示设备文件时,则需要i_rdev。它表示与哪个设备进行通信。要注意,i_rdev只是一
个数字,不是数据结构!但这个数字包含的信息,即足以找到有关目标设备、我们感兴趣的所有信息。对块设备,最终会找到struct block_device的一个实例。
如果inode表示设备特殊文件,那么i_rdev之后的匿名联合就包含了指向设备专用数据结构的指针。
i_size:文件的大小(以字节为单位)。
i_atime、i_mtime、t_ctime分别存储了最后访问文件的时间、最后修改文件的时间、最后修改inode的时间。修改文件着修改与inode相关的数据段内容。修改inode意味着修改inode结构自身(或文件的某个属性),这导致了i_ctime的改变。
i_lock:此自旋锁用于保护索引节点的各个字段,例如i_blocks、i_bytes和i_size,以免并发修改。
i_bytes:以512字节(2^9)的块为单位,文件最后一个块的字节数。
i_blkbits:以bit为单位的块的大小。
i_write_hint:对底层存储层关于索引节点访问模式的提示。它提供有关文件是主要读取还是写入的信息。
i_blocks:分配给文件的磁盘块数,文件使用块的数目。是文件系统的特征,不属于文件自身。在许多文件系统创建时,会选择一个块长度,作为在硬件介质上分配存储空间的最小单位。因此,按块计算的文件长度,也可以根据文件的字节长度和文件系统块长度计算得出。实际上没有这样做,为方便起见,该信息也归入到inode结构。
i_state:该字段存储与索引节点关联的各种状态标志,例如它是否为脏位或被引用。
i_rwsem:此读写信号量用于同步对索引节点的访问,允许同时进行多个读取或单个写入。
dirtied_when和dirtied_time_when:这些字段记录索引节点首次被标记为脏位的时间。
i_hash:此字段用于将索引节点链接到索引节点哈希表。
i_io_list:此字段用于将索引节点链接到当前正在进行I/O操作的索引节点列表。
i_lru:此字段用于将索引节点链接到最近最少使用(LRU)列表,用于缓存管理。使用LRU(最近最少使用)策略来替换最不常用的inode对象,以确保缓存中存储的是最常访问的inode。
i_sb_list:此字段用于将索引节点链接到与特定超级块相关的索引节点列表。
i_wb_list:此字段用于将索引节点链接到当前正在进行写回操作的索引节点列表。
i_dentry:引用这个inode的dentry链表的表头,一个inode会有多个dentry,i_dentry是这个链表的表头。
i_version:此原子变量用于实现文件版本控制,允许跟踪文件的更改。
i_count、i_dio_count、i_writecount、i_readcount:这些原子变量用于对索引节点进行引用计数,并跟踪特定类型的引用,如直接I/O引用。i_count是一个使用计数器,指定访问该inode结构的进程数目。例如,进程通过fork复制自身时,inode会由不同进程同时使用。
i_fop:该字段要么是与文件类型关联的默认文件操作(struct file_operations)结构的指针,要么是与文件系统特定的文件操作结构的指针。
i_flctx:该字段用于存储文件锁定上下文。
i_data:该字段是表示索引节点数据地址空间的地址空间对象。它用于将文件的数据块映射到磁盘块。每个inode都有一个地址空间。该结构用来建立缓存数据和后备存储器数据之间的映射关系。缓存的结构是内存页(page cache),缓存的数据就是文件内容。
i_devices:该字段用于将索引节点链接到设备列表。
i_pipe、i_bdev、i_cdev、i_link、i_dir_seq:这些字段用于特定类型的文件,如管道、块设备、字符设备或符号链接。
i_bdev用于块设备,i_pipe包含了用于实现管道的inode的相关信息,而i_cdev用于字符设备。
由于一个inode一次只能表示一种类型的设备,所以将i_pipe、i_bdev和i_cdev放置在联合中是安全
的。i_devices也与设备文件的处理有关联:利用该成员作为链表元素,使得块设备或字符设备可以维护一个inode的链表,每个inode表示一个设备文件,通过设备文件可以访问对应的设备。尽管在很多情况下每个设备一个设备文件就足够了,但还有很多种可能性。例如chroot造成的环境,其中一个给定的块设备或字符设备可以通过多个设备文件,因而需要多个inode。
i_generation:该字段存储索引节点的生成编号。它通常用于NFS(网络文件系统)以检测过期的文件句柄。
i_fsnotify_mask和i_fsnotify_marks:这些字段用于文件系统通知(fsnotify),用于跟踪注册的通知事件和相关的标记。
i_crypt_info:此字段用于存储与文件加密相关的信息。
i_verity_info:此字段用于存储与文件完整性验证(verity)相关的信息。
i_private:该字段是与文件系统特定或设备特定的私有数据与索引节点关联的指针。
3.2 inode链表
struct inode结构体有几个链表成员:
(1)
struct hlist_node i_hash;
除根目录的inode外,所有inode对象(这里的inode指的时vfs inode,在访问文件时在内存中生成)在一个散列表中出现,加入到一个全局哈希表inode_hashtable中,其哈希项的索引计算基于所属文件系统的超级块描述符地址,以及inode编号。以支持根据inode编号和超级块快速访问inode,这两项的组合在系统范围内是唯一的。这个哈希表的作用是方便查找属于某个文件系统的特定inode。
// linux-5.4.18/fs/inode.c
static struct hlist_head *inode_hashtable __read_mostly;
/*
* Initialize the waitqueues and inode hash table.
*/
void __init inode_init_early(void)
{
/* If hashes are distributed across NUMA nodes, defer
* hash allocation until vmalloc space is available.
*/
if (hashdist)
return;
inode_hashtable =
alloc_large_system_hash("Inode-cache",
sizeof(struct hlist_head),
ihash_entries,
14,
HASH_EARLY | HASH_ZERO,
&i_hash_shift,
&i_hash_mask,
0,
0);
}
void __init inode_init(void)
{
/* inode slab cache */
inode_cachep = kmem_cache_create("inode_cache",
sizeof(struct inode),
0,
(SLAB_RECLAIM_ACCOUNT|SLAB_PANIC|
SLAB_MEM_SPREAD|SLAB_ACCOUNT),
init_once);
/* Hash may have been set up in inode_init_early */
if (!hashdist)
return;
inode_hashtable =
alloc_large_system_hash("Inode-cache",
sizeof(struct hlist_head),
ihash_entries,
14,
HASH_ZERO,
&i_hash_shift,
&i_hash_mask,
0,
0);
}
/**
* __insert_inode_hash - hash an inode
* @inode: unhashed inode
* @hashval: unsigned long value used to locate this object in the
* inode_hashtable.
*
* Add an inode to the inode hash for this superblock.
*/
void __insert_inode_hash(struct inode *inode, unsigned long hashval)
{
struct hlist_head *b = inode_hashtable + hash(inode->i_sb, hashval);
spin_lock(&inode_hash_lock);
spin_lock(&inode->i_lock);
hlist_add_head(&inode->i_hash, b);
spin_unlock(&inode->i_lock);
spin_unlock(&inode_hash_lock);
}
EXPORT_SYMBOL(__insert_inode_hash);
__insert_inode_hash函数用于将一个索引节点(inode)插入到指定超级块(superblock)的索引节点哈希表中。
/**
* iget_locked - obtain an inode from a mounted file system
* @sb: super block of file system
* @ino: inode number to get
*
* Search for the inode specified by @ino in the inode cache and if present
* return it with an increased reference count. This is for file systems
* where the inode number is sufficient for unique identification of an inode.
*
* If the inode is not in cache, allocate a new inode and return it locked,
* hashed, and with the I_NEW flag set. The file system gets to fill it in
* before unlocking it via unlock_new_inode().
*/
struct inode *iget_locked(struct super_block *sb, unsigned long ino)
{
struct hlist_head *head = inode_hashtable + hash(sb, ino);
struct inode *inode;
again:
spin_lock(&inode_hash_lock);
inode = find_inode_fast(sb, head, ino);
spin_unlock(&inode_hash_lock);
if (inode) {
if (IS_ERR(inode))
return NULL;
wait_on_inode(inode);
if (unlikely(inode_unhashed(inode))) {
iput(inode);
goto again;
}
return inode;
}
inode = alloc_inode(sb);
if (inode) {
struct inode *old;
spin_lock(&inode_hash_lock);
/* We released the lock, so.. */
old = find_inode_fast(sb, head, ino);
if (!old) {
inode->i_ino = ino;
spin_lock(&inode->i_lock);
inode->i_state = I_NEW;
hlist_add_head(&inode->i_hash, head);
spin_unlock(&inode->i_lock);
inode_sb_list_add(inode);
spin_unlock(&inode_hash_lock);
/* Return the locked inode with I_NEW set, the
* caller is responsible for filling in the contents
*/
return inode;
}
/*
* Uhhuh, somebody else created the same inode under
* us. Use the old inode instead of the one we just
* allocated.
*/
spin_unlock(&inode_hash_lock);
destroy_inode(inode);
if (IS_ERR(old))
return NULL;
inode = old;
wait_on_inode(inode);
if (unlikely(inode_unhashed(inode))) {
iput(inode);
goto again;
}
}
return inode;
}
EXPORT_SYMBOL(iget_locked);
根据inode编号和超级块获取struct inode,快速访问inode,这两项的组合在系统范围内是唯一的。
(2)
struct list_head i_io_list; /* backing dev IO list */
用于将索引节点链接到当前正在进行I/O操作的索引节点列表。
(3)
struct list_head i_lru; /* inode LRU list */
用于将索引节点链接到最近最少使用(LRU)列表,用于 inode cache缓存管理,inode cache为了索引节点对象的加速查找。查找inode对象时,首先先从 inode cache 查找,如果不在 inode cache中,才从磁盘中的inode读取相应的数据,然后生成 VFS inode。
使用LRU(最近最少使用)策略来替换最不常用的inode对象,以确保缓存中存储的是最常访问的inode。
详细信息请参考:第四章 inode cache。
(4)
struct list_head i_sb_list;
除了散列表之外,inode还通过一个特定于超级块的链表维护,表头是super_block->s_inodes,i_sb_list用作链表元素。
每个inode被包含在所属文件系统的super_block 以s_inodes域为首的双循环链表中,inode的i_sb_list域保存了在该链表中的相连元素的指针。
struct super_block {
......
/* s_inode_list_lock protects s_inodes */
spinlock_t s_inode_list_lock ____cacheline_aligned_in_smp;
struct list_head s_inodes; /* all inodes */
}
这个链表只包含了所属文件系统的struct inode,还有其他文件系统的struct inode包含在各自的超级块对象中。
(5)
struct list_head i_wb_list; /* backing dev writeback list */
用于将索引节点链接到当前正在进行写回操作的索引节点列表,该链表通常与写入回写(writeback)机制相关。写回是将内存中已修改的数据同步到持久存储介质的过程。即内存中索引节点的信息与磁盘上索引节点的信息不一致,需要将内存中索引节点的信息根据机制更新到磁盘上索引节点。
struct super_block {
......
spinlock_t s_inode_wblist_lock;
struct list_head s_inodes_wb; /* writeback inodes */
}
每个writeback inodes被包含在所属文件系统的super_block 以s_inodes_wb域为首的双循环链表中,inode的i_wb_list 域保存了在该链表中的相连元素的指针。
这样做有下列好处:在写回数据时(数据回写通常也称之为同步)不需要扫描系统所有的inode,考虑writeback list上所有的inode就足够了。
这里就是将所有的inode分为几种不同类型的inode,分别链接到对应的链表上,当需要查找对应类型的inode时去相应的链表找即可,不需要去 s_inodes - all inodes list 查找。
(6)
struct hlist_head i_dentry;
硬链接可以让一个inode(一个文件)会对应多个目录项,i_dentry用于管理该inode的多个目录项。i_dentry引用这个inode的dentry链表的表头。dentry结构的d_alias域链入到所属inode的i_dentry(别名)链表的“连接件”。
i_dentry是引用这个inode的dentry目录项的表头:
INIT_HLIST_HEAD(&inode->i_dentry);
struct dentry {
......
struct hlist_node d_alias; /* inode alias list */
......
}
(7)
struct list_head i_devices;
union {
struct pipe_inode_info *i_pipe;
struct block_device *i_bdev;
struct cdev *i_cdev;
......
};
inode可以表示多种对象,包括目录、文件、符号链接、字符设备、块设备等。
如果inode表示块设备,则i_rdev保存了块设备编号,i_bdev为指向块设备描述符(block_device)的指针,同时通过“连接件”i_devices链入到块设备的inodes链表。
如果inode表示字符设备,则i_rdev保存了字符设备编号,i_cdev为指向字符设备描述符(cdev)的指针,同时通过i_devices链入到链入到字符设备的list链表。
3.3 struct inode_operations
struct inode_operations {
struct dentry * (*lookup) (struct inode *,struct dentry *, unsigned int);
const char * (*get_link) (struct dentry *, struct inode *, struct delayed_call *);
int (*permission) (struct inode *, int);
struct posix_acl * (*get_acl)(struct inode *, int);
int (*readlink) (struct dentry *, char __user *,int);
int (*create) (struct inode *,struct dentry *, umode_t, bool);
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*unlink) (struct inode *,struct dentry *);
int (*symlink) (struct inode *,struct dentry *,const char *);
int (*mkdir) (struct inode *,struct dentry *,umode_t);
int (*rmdir) (struct inode *,struct dentry *);
int (*mknod) (struct inode *,struct dentry *,umode_t,dev_t);
int (*rename) (struct inode *, struct dentry *,
struct inode *, struct dentry *, unsigned int);
int (*setattr) (struct dentry *, struct iattr *);
int (*getattr) (const struct path *, struct kstat *, u32, unsigned int);
ssize_t (*listxattr) (struct dentry *, char *, size_t);
int (*fiemap)(struct inode *, struct fiemap_extent_info *, u64 start,
u64 len);
int (*update_time)(struct inode *, struct timespec64 *, int);
int (*atomic_open)(struct inode *, struct dentry *,
struct file *, unsigned open_flag,
umode_t create_mode);
int (*tmpfile) (struct inode *, struct dentry *, umode_t);
int (*set_acl)(struct inode *, struct posix_acl *, int);
} ____cacheline_aligned;
struct inode_operations 是 Linux 内核中的一个结构体,用于定义与索引节点(inode)相关的操作函数。它包含了一系列函数指针,用于实现文件系统的各种操作,如查找文件、创建文件、删除文件、读取链接目标等。
下面是 struct inode_operations 结构体中定义的一些常见操作函数及其功能:
lookup: 在给定的目录中查找指定名称的文件或目录。
get_link: 获取符号链接文件的目标路径。
permission: 检查是否具有对文件执行给定操作的权限。
get_acl: 获取与文件相关的 POSIX ACL(访问控制列表)。
readlink: 读取符号链接文件的目标路径。
create: 创建新文件。
link: 创建硬链接。
unlink: 删除链接。
symlink: 创建符号链接。
mkdir: 创建新目录。
rmdir: 删除目录。
mknod: 创建设备节点。
rename: 重命名文件或目录。
setattr: 设置文件属性。
getattr: 获取文件属性。
listxattr: 列出文件的扩展属性。
fiemap: 获取文件的区域映射。
update_time: 更新文件的访问和修改时间。
atomic_open: 打开文件或创建文件(原子操作)。
tmpfile: 创建临时文件。
set_acl: 设置文件的 POSIX ACL。
上述函数指针定义了文件系统实现所需的操作,并根据具体的文件系统类型进行相应的填充。通过实现这些函数,文件系统可以对索引节点执行特定的操作。
请注意,这只是 struct inode_operations 结构体的一个示例,实际的文件系统可能会定义和实现其他操作函数。
3.4 inode相关函数
(1)
// linux-5.4.18/fs/stat.c
static inline loff_t __inode_get_bytes(struct inode *inode)
{
return (((loff_t)inode->i_blocks) << 9) + inode->i_bytes;
}
loff_t inode_get_bytes(struct inode *inode)
{
loff_t ret;
spin_lock(&inode->i_lock);
ret = __inode_get_bytes(inode);
spin_unlock(&inode->i_lock);
return ret;
}
inode_get_bytes 函数调用 __inode_get_bytes 函数来获取索引节点的字节总数。
内联函数 __inode_get_bytes,该函数接受一个指向 struct inode 的指针作为参数,并返回一个 loff_t 类型的值,即 64 位的偏移量。
该函数通过以下方式计算索引节点的字节总数:
inode->i_blocks 是索引节点中分配的磁盘块数。
inode->i_bytes 是索引节点中最后一个块的字节偏移量。
乘以 512(<< 9 是位操作,相当于乘以 2 的 9 次方),然后将两者相加,得到索引节点的字节总数。
void inode_set_bytes(struct inode *inode, loff_t bytes)
{
/* Caller is here responsible for sufficient locking
* (ie. inode->i_lock) */
inode->i_blocks = bytes >> 9;
inode->i_bytes = bytes & 511;
}
EXPORT_SYMBOL(inode_set_bytes);
函数内部,它将字节总数 bytes 右移 9 位(相当于除以 512,将块数计算出来),并将结果存储在 inode->i_blocks 中。然后,它将 bytes 与 511 进行按位与操作(相当于取模 512),将结果存储在 inode->i_bytes 中。
通过调用 inode_set_bytes 函数,可以设置给定索引节点的字节总数。
(2)根据 struct file 获取 struct inode:
static inline struct inode *file_inode(const struct file *f)
{
return f->f_inode;
}
/**
* d_inode - Get the actual inode of this dentry
* @dentry: The dentry to query
*
* This is the helper normal filesystems should use to get at their own inodes
* in their own dentries and ignore the layering superimposed upon them.
*/
static inline struct inode *d_inode(const struct dentry *dentry)
{
return dentry->d_inode;
}
struct file {
struct path f_path;
struct inode *f_inode; /* cached value */
}
struct path {
struct vfsmount *mnt;
struct dentry *dentry;
} __randomize_layout;
struct dentry {
......
struct inode *d_inode;
} __randomize_layout;
因此根据 struct file 获取 struct inode 有两种方案:
struct file *file;
struct inode * inode = file->f_inode;
struct inode * inode = file->f_path.dentry->d_inode;
(3)
static inline bool is_root_inode(struct inode *inode)
{
return inode == inode->i_sb->s_root->d_inode;
}
struct inode {
struct super_block *i_sb;
}
struct super_block {
struct dentry *s_root;
}
struct dentry {
struct inode *d_inode;
}
静态内联函数 is_root_inode,用于判断给定的 inode 是否为根目录的 inode。它可以在文件系统操作或权限控制等方面使用,以确定当前操作是否在根目录上进行。
(4)
/**
* iget_locked - obtain an inode from a mounted file system
* @sb: super block of file system
* @ino: inode number to get
*
* Search for the inode specified by @ino in the inode cache and if present
* return it with an increased reference count. This is for file systems
* where the inode number is sufficient for unique identification of an inode.
*
* If the inode is not in cache, allocate a new inode and return it locked,
* hashed, and with the I_NEW flag set. The file system gets to fill it in
* before unlocking it via unlock_new_inode().
*/
struct inode *iget_locked(struct super_block *sb, unsigned long ino)
{
struct hlist_head *head = inode_hashtable + hash(sb, ino);
struct inode *inode;
again:
spin_lock(&inode_hash_lock);
inode = find_inode_fast(sb, head, ino);
spin_unlock(&inode_hash_lock);
if (inode) {
if (IS_ERR(inode))
return NULL;
wait_on_inode(inode);
if (unlikely(inode_unhashed(inode))) {
iput(inode);
goto again;
}
return inode;
}
inode = alloc_inode(sb);
if (inode) {
struct inode *old;
spin_lock(&inode_hash_lock);
/* We released the lock, so.. */
old = find_inode_fast(sb, head, ino);
if (!old) {
inode->i_ino = ino;
spin_lock(&inode->i_lock);
inode->i_state = I_NEW;
hlist_add_head(&inode->i_hash, head);
spin_unlock(&inode->i_lock);
inode_sb_list_add(inode);
spin_unlock(&inode_hash_lock);
/* Return the locked inode with I_NEW set, the
* caller is responsible for filling in the contents
*/
return inode;
}
/*
* Uhhuh, somebody else created the same inode under
* us. Use the old inode instead of the one we just
* allocated.
*/
spin_unlock(&inode_hash_lock);
destroy_inode(inode);
if (IS_ERR(old))
return NULL;
inode = old;
wait_on_inode(inode);
if (unlikely(inode_unhashed(inode))) {
iput(inode);
goto again;
}
}
return inode;
}
EXPORT_SYMBOL(iget_locked);
iget_locked这个函数在上文提到过,根据inode编号和超级块从inode高速缓存中获取struct inode,快速访问inode,inode编号和超级块这两项的组合在系统范围内是唯一的。
(5)
/*
* search the inode cache for a matching inode number.
* If we find one, then the inode number we are trying to
* allocate is not unique and so we should not use it.
*
* Returns 1 if the inode number is unique, 0 if it is not.
*/
static int test_inode_iunique(struct super_block *sb, unsigned long ino)
{
struct hlist_head *b = inode_hashtable + hash(sb, ino);
struct inode *inode;
spin_lock(&inode_hash_lock);
hlist_for_each_entry(inode, b, i_hash) {
if (inode->i_ino == ino && inode->i_sb == sb) {
spin_unlock(&inode_hash_lock);
return 0;
}
}
spin_unlock(&inode_hash_lock);
return 1;
}
该函数的作用是在 inode 缓存中搜索具有与给定 inode 号 ino 和超级块 sb 匹配的 inode。如果找到匹配的 inode,则表示正在尝试分配的 inode 号不是唯一的,因此不能使用它。
首先,函数通过调用 hash 函数计算哈希值,并获取与该哈希值对应的哈希链表头指针 b。
然后,函数获取全局的 inode_hash_lock 自旋锁,以在执行搜索期间锁定 inode 缓存的哈希表。
接下来,函数使用 hlist_for_each_entry 宏遍历哈希链表中的每个 inode。对于每个 inode,它检查 inode 号和超级块是否与给定的匹配。如果找到匹配的 inode,则表示 inode 号不是唯一的,函数将释放自旋锁,并返回 0。
如果在整个哈希链表中没有找到匹配的 inode,函数将释放自旋锁,并返回 1,表示 inode 号是唯一的。
该函数用于检查给定的 inode 号是否已在 inode 缓存中存在,以避免分配重复的 inode 号。
四、inode cache
4.1 简介
在Linux内核中,inode缓存是用于高效管理和重用inode结构体的机制。inode缓存存储了最近使用过的inode对象,以便在需要时可以快速获取和操作它们,而无需每次都从磁盘上读取。
inode是Linux文件系统中的核心数据结构,它包含了文件或目录的元数据信息,如文件大小、访问权限、链接计数等。每个打开的文件都有一个关联的inode对象。
inode缓存通过减少从磁盘读取inode的次数,提高了文件系统的性能。它可以减少磁盘I/O的开销,加快文件系统操作的速度。当应用程序打开或访问文件时,内核首先检查inode缓存,看是否已经有相应的inode对象存在。如果存在,内核会从缓存中获取该inode对象,而无需再次读取磁盘上的数据。这样可以显著提高文件系统的响应速度。如果不存在,那么就会从磁盘读取inode的数据,生成VFS inode对象,并且将VFS inode对象添加到inode缓存中,方便下一次查找该inode对象。
// linux-5.4.18/fs/inode.c
static struct hlist_head *inode_hashtable __read_mostly;
/**
* ilookup - search for an inode in the inode cache
* @sb: super block of file system to search
* @ino: inode number to search for
*
* Search for the inode @ino in the inode cache, and if the inode is in the
* cache, the inode is returned with an incremented reference count.
*/
struct inode *ilookup(struct super_block *sb, unsigned long ino)
{
struct hlist_head *head = inode_hashtable + hash(sb, ino);
struct inode *inode;
again:
spin_lock(&inode_hash_lock);
inode = find_inode_fast(sb, head, ino);
spin_unlock(&inode_hash_lock);
if (inode) {
if (IS_ERR(inode))
return NULL;
wait_on_inode(inode);
if (unlikely(inode_unhashed(inode))) {
iput(inode);
goto again;
}
}
return inode;
}
EXPORT_SYMBOL(ilookup);
inode缓存在内核中被称为inode cache,它是通过哈希表(inode_hashtable)实现的。哈希表中的每个槽位存储了一组相似的inode对象,这些对象根据哈希函数将它们映射到相应的槽位中。当需要查找或插入inode对象时,内核根据inode编号使用哈希函数确定对应的槽位,并在该槽位中查找或插入inode对象。
inode缓存还采用了一些优化策略来提高性能。例如,使用LRU(最近最少使用)策略来替换最不常用的inode对象,以确保缓存中存储的是最常访问的inode。此外,还会对inode对象进行引用计数,以确保在没有任何引用时能够正确释放和回收它们。
inode缓存是Linux文件系统中关键的性能优化手段之一,它在许多文件系统的实现中得到广泛使用,包括常见的文件系统如Ext4、XFS等。通过减少磁盘I/O,提高文件系统的响应速度,inode缓存对于提升系统的整体性能和效率非常重要。
与inode cache对应的还有dentry cache,dentry cache是为了加速dentry的查找。
如下图所示:

图片来自于:极客时间Linux性能优化实战
清理缓存:
/proc/sys/vm/drop_caches (since Linux 2.6.16)
Writing to this file causes the kernel to drop clean caches, dentries, and inodes from memory, causing that memory to become free. This can be useful for memory
management testing and performing reproducible filesystem benchmarks. Because writing to this file causes the benefits of caching to be lost, it can degrade
overall system performance.
To free pagecache, use:
echo 1 > /proc/sys/vm/drop_caches
To free dentries and inodes, use:
echo 2 > /proc/sys/vm/drop_caches
To free pagecache, dentries and inodes, use:
echo 3 > /proc/sys/vm/drop_caches
Because writing to this file is a nondestructive operation and dirty objects are not freeable, the user should run sync(1) first.
4.2 inode cache初始化
// linux-5.4.18/init/main.c
start_kernel()
-->vfs_caches_init_early();
......
-->vfs_caches_init();
(1)
// linux-5.4.18/fs/dcache.c
void __init vfs_caches_init_early(void)
{
int i;
for (i = 0; i < ARRAY_SIZE(in_lookup_hashtable); i++)
INIT_HLIST_BL_HEAD(&in_lookup_hashtable[i]);
dcache_init_early();
inode_init_early();
}
// linux-5.4.18/fs/inode.c
/*
* Initialize the waitqueues and inode hash table.
*/
void __init inode_init_early(void)
{
/* If hashes are distributed across NUMA nodes, defer
* hash allocation until vmalloc space is available.
*/
if (hashdist)
return;
inode_hashtable =
alloc_large_system_hash("Inode-cache",
sizeof(struct hlist_head),
ihash_entries,
14,
HASH_EARLY | HASH_ZERO,
&i_hash_shift,
&i_hash_mask,
0,
0);
}
(2)
// linux-5.4.18/fs/dcache.c
void __init vfs_caches_init(void)
{
names_cachep = kmem_cache_create_usercopy("names_cache", PATH_MAX, 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC, 0, PATH_MAX, NULL);
dcache_init();
inode_init();
files_init();
files_maxfiles_init();
mnt_init();
bdev_cache_init();
chrdev_init();
}
// linux-5.4.18/fs/inode.c
void __init inode_init(void)
{
/* inode slab cache */
inode_cachep = kmem_cache_create("inode_cache",
sizeof(struct inode),
0,
(SLAB_RECLAIM_ACCOUNT|SLAB_PANIC|
SLAB_MEM_SPREAD|SLAB_ACCOUNT),
init_once);
/* Hash may have been set up in inode_init_early */
if (!hashdist)
return;
inode_hashtable =
alloc_large_system_hash("Inode-cache",
sizeof(struct hlist_head),
ihash_entries,
14,
HASH_ZERO,
&i_hash_shift,
&i_hash_mask,
0,
0);
}
从源码中我们可以看到 dcache 和 icache 这两种缓存的初始化的都在/fs/dcache.c目录下。
因为dcache在一定意义上提供了对索引节点的缓存。和目录项对象相关的索引节点对象不会被释放,因为目录项会让相关索引节点的使用计数为正,这样就可以确保索引节点留在内存中了。只要目录项被缓存,其相应的索引节点也就被缓存。所以只要路径名在缓存中找到了,那么相应的索引节点肯定也在内存中缓存着。
因为文件访问呈现空间和时间的局部性,所以对目录项和索引节点进行缓存非常有益。文件访问有时间上的局部性,是因为程序可能一次又一次地访问相同地文件。因此,当一个文件被访问时,所缓存地相关目录项和索引节点在不久被命中地概率比较高。文件访问具有空间地局部性是因为程序可能在同一个目录下访问多个文件,因此对一个文件对应地目录项缓存后极有可能被命中,因为相关地文件可能在下次又被使用。
4.3 inode cache查看
查看/proc/slabinfo这个文件可以得到,所有目录项和各种文件系统索引节点的缓存情况:
# cat /proc/slabinfo | grep -E '^#|dentry|inode'
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
mqueue_inode_cache 17 17 960 17 4 : tunables 0 0 0 : slabdata 1 1 0
fuse_inode 76 76 832 19 4 : tunables 0 0 0 : slabdata 4 4 0
ecryptfs_inode_cache 0 0 1024 16 4 : tunables 0 0 0 : slabdata 0 0 0
fat_inode_cache 40 40 792 20 4 : tunables 0 0 0 : slabdata 2 2 0
squashfs_inode_cache 4117 4117 704 23 4 : tunables 0 0 0 : slabdata 179 179 0
ext4_fc_dentry_update 0 0 96 42 1 : tunables 0 0 0 : slabdata 0 0 0
ext4_inode_cache 40716 40716 1192 27 8 : tunables 0 0 0 : slabdata 1508 1508 0
hugetlbfs_inode_cache 24 24 664 24 4 : tunables 0 0 0 : slabdata 1 1 0
sock_inode_cache 1039 1140 832 19 4 : tunables 0 0 0 : slabdata 60 60 0
proc_inode_cache 5741 6049 712 23 4 : tunables 0 0 0 : slabdata 263 263 0
shmem_inode_cache 3208 3318 776 21 4 : tunables 0 0 0 : slabdata 158 158 0
inode_cache 35798 35800 640 25 4 : tunables 0 0 0 : slabdata 1432 1432 0
dentry 110523 110523 192 21 1 : tunables 0 0 0 : slabdata 5263 5263 0
这个界面中,dentry行表示目录项缓存,inode_cache行表示VFS索引节点缓存,其余的则是各种文件系统的索引节点缓存。
使用 slabtop ,来找到占用内存最多的缓存类型。
# 按下c按照缓存大小排序,按下a按照活跃对象数排序
$ slabtop
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
92745 92745 100% 1.16K 3435 27 109920K ext4_inode_cache
167097 167097 100% 0.19K 7957 21 31828K dentry
36150 35986 99% 0.62K 1446 25 23136K inode_cache
4256 4233 99% 4.00K 532 8 17024K kmalloc-4k
23884 23884 100% 0.57K 853 28 13648K radix_tree_node
62016 61565 99% 0.12K 1938 32 7752K kernfs_node_cache
34086 33634 98% 0.20K 1794 19 7176K vm_area_struct
151130 151130 100% 0.05K 1778 85 7112K shared_policy_node
63804 63804 100% 0.10K 1636 39 6544K buffer_head
765 604 78% 6.38K 153 5 4896K task_struct
2320 2293 98% 2.00K 145 16 4640K kmalloc-2k
6049 5683 93% 0.70K 263 23 4208K proc_inode_cache
6976 6680 95% 0.50K 436 16 3488K kmalloc-512
412 412 100% 8.00K 103 4 3296K kmalloc-8k
4163 4163 100% 0.69K 181 23 2896K squashfs_inode_cache
3675 3675 100% 0.76K 175 21 2800K shmem_inode_cache
12453 12453 100% 0.19K 593 21 2372K kmalloc-192
9296 7826 84% 0.25K 581 16 2324K filp
8544 8544 100% 0.25K 534 16 2136K kmalloc-256
1584 1545 97% 1.00K 99 16 1584K kmalloc-1k
......
可以看到目录项和索引节点占用了最多的Slab缓存。
参考资料
Linux 5.4.18
极客时间Linux性能优化实战
https://static.lwn.net/kerneldoc/filesystems/vfs.html
存储基础 — 文件描述符 fd 究竟是什么?

















 7966
7966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









