







一、x86_64架构寄存器简介
1.1 简介
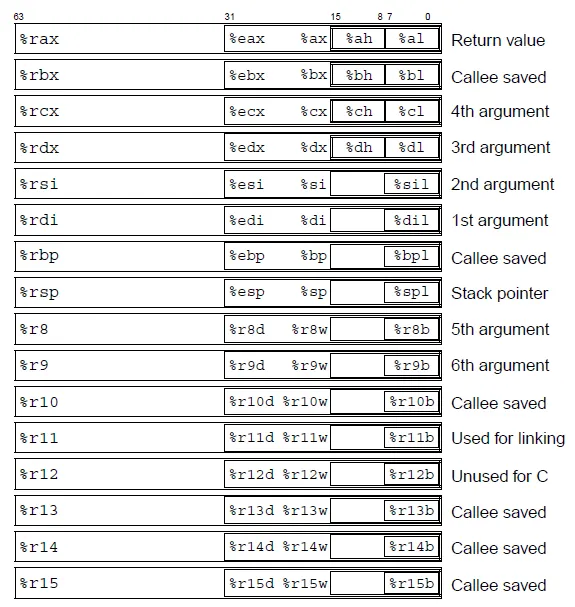
在x86架构中,有8个通用寄存器可用:eax、ebx、ecx、edx、ebp、esp、esi和edi。在x86_64(x64)扩展中,这些寄存器被扩展为64位,以’r’前缀代替’e’,并添加了另外8个寄存器:r8、r9、r10、r11、r12、r13、r14和r15。
(1)
x64架构中寄存器的数量增加了,这为优化寄存器分配提供了更多机会,并减少了对栈的依赖。这影响了应用程序二进制接口(ABI)的重要设计决策,ABI定义了函数如何被调用以及参数如何在程序的不同部分之间传递。
x64 ABI中的一个重要变化是更多地使用寄存器传递函数参数。调用约定指定最多可以通过寄存器(rdi、rsi、rdx、rcx、r8和r9)传递6个整数或指针参数,而不是将它们推入栈中。这减少了栈的使用,并改善了具有少量参数的函数调用的性能。
根据ABI规范,在函数中,前6个整数或指针参数将被传递到寄存器中。第一个参数被放置在rdi寄存器中,第二个参数放置在rsi寄存器中,第三个参数放置在rdx寄存器中,然后是rcx、r8和r9寄存器。只有第7个参数及以后的参数才会传递到栈上。
如下图所示函数P调用函数Q:
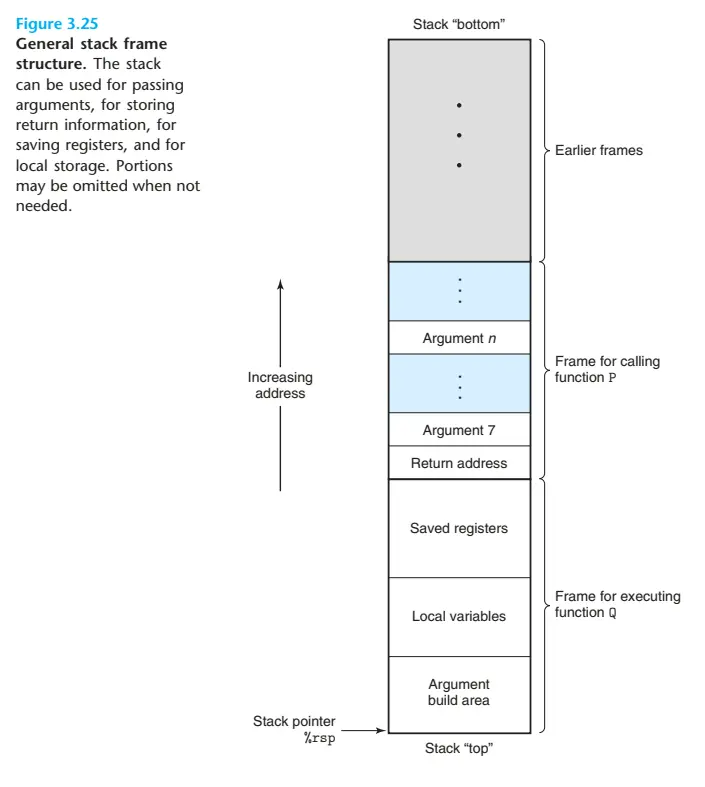
备注:第7个参数及以后的参数时保存在调用者的栈中,上述函数P调用函数Q过程中,如果函数Q需要大于6个的参数,那么函数P调用函数Q时将参数7-n保存在自己的栈帧中,第7个参数及以后的参数是从右向左压入栈中,将先压入参数n,最后压入参数7,可以看到函数P的栈帧,参数n在高地址,参数7在低地址。
比如 函数 fun1 调用 函数 fun2:
fun2()
{
}
fun1()
{
fun2(a,b,c,d,e,f,g,h);
}
函数 fun1 调用 函数 fun2时,通过寄存器最多传递6个整数(指针或者整数),但是fun2需要8个参数,那么函数 fun1 在调用函数 fun2之前在自己的栈帧中存储好多余的参数,也就是第7个参数及以后的参数。其中参数7位于位于栈顶,在栈帧低地址。
函数 fun1 调用 函数 fun2的过程:将参数1-6复制到对应的寄存器(rdi、rsi、rdx、rcx、r8和r9),把参数7-8放在函数 fun1的栈顶,当参数到位后,程序就可以执行call指令将控制转移到函数 fun2了。如果函数 fun2也调用了大于6个参数的函数,那么也要把超出6个参数的部分保存在自己的栈帧中,
更多的寄存器可用性还影响了栈帧的使用。由于有更多的通用寄存器,可以更容易地将经常访问的变量保存在寄存器中,减少了将它们存储在栈上的需求。这可以提高代码执行效率,并可能导致更小的栈帧。
(2)
对于x86,其栈帧:

x86 架构函数参数传递都是采用压栈的方式传递:
cdecl(C 声明)是一种用于 C 编程语言的调用约定,它被许多 x86 架构的 C 编译器使用。在 cdecl 中,子程序的参数是通过栈传递的。
在 cdecl 调用约定中,函数的参数是从右向左依次压入栈中。调用方负责在调用函数之前将参数压入栈中,然后调用函数。在函数内部,被调用函数负责从栈中依次弹出参数,并按照声明时的顺序使用这些参数。
x86栈的相关知识:https://eli.thegreenplace.net/2011/02/04/where-the-top-of-the-stack-is-on-x86/
1.2 返回地址和FP
(1)x86_64
当P执行call指令的时候(在跳转到被调用过程的第一条指令之前),将下一条指令的地址作为返回地址压入栈中,返回地址应该属于P的栈帧一部分。
0000000000001147 <funb>:
1147: f3 0f 1e fa endbr64
114b: 55 push %rbp //保存rbp寄存器的值到栈帧中, 存储着上一层函数调用时的rbp值
114c: 48 89 e5 mov %rsp,%rbp
114f: 48 83 ec 18 sub $0x18,%rsp
......
117a: c3 ret
000000000000117b <main>:
......
119f: e8 a3 ff ff ff call 1147 <funb>
......
main函数调用call funb函数时,将返回地址压入到main函数自己的栈中,返回地址应该属于main的栈帧一部分。
函数funb不是叶子函数,会修改RBP寄存器的值,因此funb函数将RBP寄存器的值保存在funb函数的栈帧中,以便ret时恢复。
(2)ARM64
当P执行BL指令时,将下一条指令的地址作为返回地址保存在LR(x30寄存器中),此时没有压入栈中,当执行Q时,Q将LR(x30寄存器)的值压入Q的栈帧中,返回地址应该属于Q的栈帧一部分。
0000000000000744 <funb>:
744: a9bd7bfd stp x29, x30, [sp, #-48]! //保存x29, x30的值到栈帧中
748: 910003fd mov x29, sp
......
77c: d65f03c0 ret
0000000000000780 <main>:
......
7a0: 97ffffe9 bl 744 <funb>
......
main函数调用bl funb函数时,将返回地址保存在LR(x30寄存器中),此时没有压入栈中。
函数funb不是叶子函数,会修改x29(FP寄存器), x30(链接寄存器)的值,执行stp指令将x29, x30这两个寄存器的值保存在自己的栈中,因此返回地址属于函数funb的栈帧一部分。
二、x86_64架构帧指针FP
在x86_64架构中,函数调用过程中需要的存储空间超出寄存器能够存放的大小时,就会在栈上分配空间,这个空间称为函数的栈帧(stack frame),函数调用创建一个栈帧(stack frame)来存储局部变量、函数参数、返回地址和其他与函数执行相关的信息。栈帧是在程序执行期间动态地分配和管理的。
并非每个函数调用都会创建栈帧。当函数调用参数少于6个且可以通过寄存器传递,以及所有局部变量都可以保存在寄存器中并且函数是叶子函数(叶子函数指该函数不会调用其他函数)时,就不需要创建栈帧。
大多数函数调用过程中栈帧都是定长的,在函数调用的开始就分配好了栈空间。
(1)帧指针(Frame Pointer):
在x86_64架构中,FP通常是指Frame Pointer,也称为帧指针。帧指针通常由RBP寄存器(Base Pointer)表示。
帧指针指向当前函数的栈帧的底部,即栈帧中局部变量和函数参数的起始位置。
从该地址为基准,向上(栈底方向)能获取返回地址、参数值,向下(栈顶方向)能获取函数局部变量值,而该地址处又存储着上一层函数调用时的ebp值
使用帧指针的好处是,它提供了一种相对于固定参考点的偏移量访问局部变量和函数参数的方式。通过将帧指针与偏移量相结合,可以准确地访问栈帧中的特定变量或参数。
通过帧指针,可以访问局部变量、函数参数和返回地址等信息。
帧指针的值在函数执行过程中是稳定的,不会随着栈的动态变化而改变。这使得调试器和性能分析器能够使用帧指针来构建函数调用图和跟踪变量的访问情况。
基于帧指针可以进行栈回溯:
在X86中,通常使用RBP寄存器作为帧指针使用,RBP寄存器所指向的栈单元中保存的是前一个RBP寄存器的值,通常也就是caller函数的RBP值。帧指针不仅对函数中的代码起到定位变量和参数的参照物作用,而且将栈中的一个个栈帧串联在一起,形成了一个可以遍历所有栈帧的链条,这也就是栈回溯的基本原理。
栈一直随着函数调用的深入,一直向栈顶方向压下去。每次调用函数时候,参数小于等于6个用寄存器传递,大于6个的参数压入caller的栈中,先压函数参数 7 - n(从右往左顺序压,参数n在高地址,参数7在低地址),再压入函数调用下条指令的地址(由call完成)。接着进入调用函数体中先执行"push %rbp"和"mov %rsp,%rbp"(一般已经由编译器加入到函数头中了),接着就是把函数体中的局部变量压入栈中。再遇到函数的调用的嵌套则依此类推。
"push %rbp"和"mov %rsp,%rbp"这两条指令实在大有深意:首先将RBP入栈,然后将栈顶指针RSP赋值给RBP。"mov %rsp,%rbp"这条指令表面上看是用rsp把rbp原来的值覆盖了,其实不然——因为给rbp赋值之前,原rbp值已被压栈(位于栈顶),而新的rbp又恰恰指向栈顶。
此时rbp寄存器就已处于一个很重要的地位,该寄存器中存储着栈中的一个地址(原rbp入栈后的栈顶),从该地址为基准,向上(栈底方向)能获取返回地址、参数值,向下(栈顶方向)能获取函数局部变量值,而该地址处又存储着上一层函数调用时的rbp值!这样就可以基于帧指针可以进行栈回溯。
详细请参考:Linux x86_64 dump_stack()函数基于FP栈回溯
(2)栈指针(Stack Pointer):
在x86_64架构中,栈指针通常由RSP寄存器(Stack Pointer)表示。
栈指针指向当前栈顶的位置,即最新压入栈的数据所在的内存地址。
使用push指令将数据存入栈中,使用pop指令将数据从栈中取出。
通过栈指针减小一个适当的量可以为没有指定初始值的数据在栈上分配空间,增加栈指针来释放栈空间。
当给一个函数分配栈时,编译阶段会计算好分配栈空间的大小,调用该函数的时候,SP寄存器一次性分配栈空间的大小。
func()
{
int a = 1;
int b = 2;
int c = 3;
}
比如上述函数,一次性计算这三个局部变量所需要占用的占空间大小,调用该函数时移动SP寄存器分配这三个局部变量所需要占用的占空间大小。
(3)局部变量和函数参数:
每个函数调用都会在栈帧中分配一定的空间来存储局部变量和函数参数。
这些变量和参数的访问通常是相对于帧指针的偏移量来进行的。
(4)返回地址(Return Address):
在函数调用时,返回地址会被压入栈中,以便在函数执行完毕后返回到调用它的位置。
在跳转到被调用过程的第一条指令之前,CALL指令会将RIP寄存器中的地址推送到当前栈上。这个地址被称为返回指令指针(return-instruction pointer),它指向在从被调用过程返回后,调用过程应该从哪条指令继续执行。在从被调用过程返回时,RET指令会将返回指令指针从栈中弹出,并将其放回RIP寄存器中。然后,调用过程的执行会继续。
RIP寄存器:用于指示将要执行的下一条指令的地址。当处理器执行指令时,RIP寄存器会自动递增,指向下一条将要执行的指令的地址。在分支、跳转或调用指令执行时,RIP寄存器的值会被改变以跳转到新的指令地址。在过程调用中,CALL指令会将返回地址(下一条指令地址)推送到栈上,而RET指令会将栈上的返回地址弹出并存储回RIP寄存器,从而实现从子过程返回到调用过程。
(5)栈帧布局(Stack Frame Layout):
栈帧布局是指栈帧中各个元素的相对位置和顺序。
栈帧布局是由编译器在函数编译过程中决定的,通常根据函数的局部变量和参数的需求进行分配和组织。
备注:在x86_64架构下,gcc没有使用优化选项时,帧指针来访问栈帧的数据,栈指针来分配和释放栈帧的空间。
当gcc使用 -O 优化选项时会省略帧指针,即gcc的所有级别的优化(-O1, -O2, -O3等)都会打开-fomit-frame-pointer,该选项的功能是函数调用时不保存frame指针,请参考第4节。
三、示例
寄存器是唯一被所有过程(函数调用)共享的资源,虽然在给定时刻只有一个函数调用只在执行,但是我们仍然要确保当一个过程(caller - 调用者)调用另一个过程(callee - 被调用者)时,callee不会覆盖caller稍后会使用的寄存器值,callee必须保存这些寄存器的值,保证他们的值在 callee返回到caller 与 caller调用callee 的值是一样的。
callee保存一个寄存器不变,要么就是根本不改变它(callee肯定要使用寄存器来加快数据的运算,因此callee在使用通用寄存器前先将其保存在栈中,然后再使用),要么就是把原始值压入栈中,callee把原始值压入栈中就可以使用该寄存器了,返回到caller时,将其从栈中弹出,恢复该寄存器的值。
对于x86_64架构 rbx,rbp 和 r12 - r15 被划分为被调用者保存寄存器。
在x86_64架构中,函数调用过程中被调用者保存的寄存器包括 rbx、rbp、r12、r13、r14 和 r15。这些寄存器的保存是为了在函数调用过程中保护被调用者的现场,以便在函数返回后能够正确恢复。
保护调用者的数据:被调用者保存寄存器的值,包括 rbx、rbp、r12、r13、r14 和 r15,是为了确保在函数调用过程中不会意外修改调用者的重要数据。通过保存这些寄存器的值,可以防止函数的执行对调用者的数据造成破坏。
long utilfunc(long a, long b, long c)
{
long xx = a + 2;
long yy = b + 3;
long zz = c + 4;
long sum = xx + yy + zz;
return xx * yy * zz + sum;
}
long myfunc(long a, long b, long c, long d,
long e, long f, long g, long h)
{
long xx = a * b * c * d * e * f * g * h;
long yy = a + b + c + d + e + f + g + h;
long zz = utilfunc(xx, yy, xx % yy);
return zz + 20;
}
func1
{
myfunc(a,b,c,d,e,f,g,h);
}
(1)其中myfunc函数栈布局如下所示:

myfunc函数的栈帧就是 RBP到RSP,func1调用myfunc,将参数1-6(a、b、c、d、e、f)复制到对应的寄存器(rdi、rsi、rdx、rcx、r8和r9),把参数g、h放在函数 func1的栈顶,把返回地址压入到栈顶中,myfunc函数的栈帧保存局部变量xx、yy、zz。
返回地址和参数g、h都是放在函数 func1的栈帧中。
根据AMD64 ABI的正式定义:
%rsp指向的位置后面的128字节区域被认为是保留的,不应该被信号处理程序或中断处理程序修改。因此,函数可以使用这个区域作为临时数据存储区,这些数据在函数调用之间不需要保留。特别是,叶子函数可以将整个栈帧放在这个区域中,而不需要在函数的开头和结尾调整栈指针。这个区域被称为红区(red zone)。
简单来说,红区是一种优化策略。代码可以假设rsp下面的128字节不会被信号处理程序或中断处理程序异步破坏,因此可以将其用作临时数据的存储区,而无需显式地移动栈指针。这个优化的关键是最后一句话——使用红区存储数据时,可以节省减少rsp和恢复rsp的两条指令。
这意味着当函数使用红区来存储临时数据时,可以省略调整栈指针的指令,从而提高代码的执行效率。红区的使用使得对栈指针的调整仅发生在需要保留的数据超过128字节的情况下,而对于较小的临时数据,可以直接使用红区,无需额外操作。
需要注意的是,红区的使用是可选的,并且在使用时需要小心确保不会超出128字节的范围,以避免与异常处理相关的问题。
(2)其中utilfunc函数栈布局如下所示:
回想一下上面代码示例中的myfunc是如何调用另一个名为utilfunc的函数的。这样做是故意的,目的是使myfunc成为非叶子,从而防止编译器应用红区优化。看看utilfunc的代码,这确实是一个叶函数。让我们看看使用gcc编译时它的堆栈框架是什么样子的。

由于utilfunc只有3个参数,因此调用它不需要使用堆栈,因为所有参数都适合寄存器。此外,由于它是一个叶函数,gcc选择对其所有局部变量使用红色区域。因此,rsp不需要递减(稍后恢复)来为该数据分配空间。
四、保存帧指针
在函数执行过程中,基指针rbp(以及在x86上的前身ebp)作为指向栈帧开头的稳定"锚点",在手动汇编编码和调试中非常方便。然而,一段时间以前就注意到,编译器生成的代码实际上并不需要它(编译器可以轻松地从rsp跟踪偏移量),而DWARF调试格式提供了访问栈帧的手段(CFI),无需使用基指针。
因此,一些编译器开始省略基指针以进行积极的优化,从而缩短函数的前奏和尾声,并提供了一个额外的通用寄存器供使用(请记住,在具有有限通用寄存器集的x86上,这非常有用)。
gcc在x86上默认保留基指针,但允许使用-fomit-frame-pointer编译标志进行优化。关于是否建议使用此标志存在争议——如果您对此感兴趣,可以进行一些搜索。
无论如何,AMD64 ABI引入的另一个"新特性"是明确将基指针作为可选项,规定如下:
可以通过使用%rsp(栈指针)来索引栈帧,从而避免将%rbp用作栈帧指针的传统用法。这种技术在前奏和尾声中可以节省两条指令,并提供了一个额外的通用寄存器(%rbp)。
gcc遵循这个建议,并在进行优化编译时,默认情况下在x64上省略帧指针。它提供了一个选项通过使用-fno-omit-frame-pointer标志来保留帧指针。出于清晰起见,上面显示的栈帧是在没有省略帧指针的情况下生成的。
-fomit-frame-pointer:省略帧指针。
-fno-omit-frame-pointer:保留帧指针。
gcc在x86(x86_64)上默认保留基指针
x86_64架构,gcc优化选项 -O 默认使用-fomit-frame-pointer编译标志进行优化,省略帧指针。
-fomit-frame-pointer
Omit the frame pointer in functions that don't need one. This avoids the instructions to save, set up and restore the frame pointer; on many targets it also makes
an extra register available.
On some targets this flag has no effect because the standard calling sequence always uses a frame pointer, so it cannot be omitted.
Note that -fno-omit-frame-pointer doesn't guarantee the frame pointer is used in all functions. Several targets always omit the frame pointer in leaf functions.
Enabled by default at -O and higher.
-fomit-frame-pointer 是GCC编译器的一个编译选项。当启用该选项时,它告诉编译器在不需要基指针的函数中省略基指针。通过省略基指针,编译器避免了保存、设置和恢复基指针的指令,从而使生成的代码更小、更快。
省略基指针还提供了一个额外的通用寄存器可供使用,这对于具有有限通用寄存器数量的架构(如x86)非常有用。
然而,需要注意的是,该选项的效果可能因目标架构而异。在一些目标架构中,标准调用序列始终使用基指针,因此该选项可能没有效果,基指针仍然会被使用。
值得注意的是,即使不使用 -fno-omit-frame-pointer,也不能保证在所有函数中都使用基指针。一些目标架构,特别是在叶子函数(不调用其他函数的函数)中,仍然会省略基指针以进行优化。
默认情况下,在优化级别 -O 及更高级别时, -fomit-frame-pointer 选项会被启用,意味着在优化的代码中会省略基指针。
当gcc没有使用优化选项时,函数开头和结尾会有如下指令:
func
{
push %rbp
mov %rsp,%rbp
sub $0x50,%rsp
......
ops %rbp
......
pop %rbp
ret
}
首先,指令"push %rbp"将当前函数的基指针值压入栈中,保存起来。接下来,指令"mov %rsp, %rbp"将当前栈指针的值(rsp)复制到基指针(rbp)中,将其作为新的栈帧的基准。
接下来,指令"sub $0x50, %rsp"将栈指针向下移动,为函数的局部变量和临时存储空间分配一段空间。在这个例子中,它分配了80字节(0x50的十六进制值)的空间。
在这两条指令之后,可能会有其他指令用于函数的实际操作和计算。比如通过帧指针,可以访问局部变量、函数参数和返回地址等信息。
最后,指令"pop %rbp"将之前保存在栈中的基指针值弹出,并恢复原来的基指针值。然后,指令"ret"用于从函数中返回。
这段代码的作用是在函数执行前保存基指针,然后在函数执行完毕后恢复基指针,并返回到调用函数的位置。它还通过减少栈指针%rsp的值来为函数的局部变量和临时存储空间分配内存。这样可以确保函数在执行期间帧指针%rbp对局部变量和其他数据的正确访问,并在函数返回时释放相应的空间。
五、基于帧指针FP栈回溯
在X86中,通常使用RBP寄存器作为帧指针使用,RBP寄存器所指向的栈单元中保存的是前一个RBP寄存器的值,通常也就是caller函数的RBP值。帧指针不仅对函数中的代码起到定位变量和参数的参照物作用,而且将栈中的一个个栈帧串联在一起,形成了一个可以遍历所有栈帧的链条,这也就是栈回溯的基本原理。
下面是通过帧指针FP(RBP寄存器)来实现函数返回地址,被调用函数地址的获取的简单实现原理 :
#include <stdio.h>
int add(int a, int b)
{
return a + b;
}
int main()
{
int a = 2;
int b = 3;
int c = add(a, b);
return 0;
}
main函数调用add函数,会将下一条指令当作返回地址压入到栈中,执行add函数,处于add函数栈帧,我们可以获取其保存的RBP寄存器的值,返回地址在保存的RBP寄存器地址的上方,因此返回地址等于 RBP + 8。
返回地址就是main函数调用add函数的下一条指令地址0x400526,返回地址上一条指令就是main函数调用add函数的地址,这样就可以获取到main函数调用add函数的地址,以下汇编为例:
00000000004004ed <add>:
4004ed: 55 push %rbp
4004ee: 48 89 e5 mov %rsp,%rbp
4004f1: 89 7d fc mov %edi,-0x4(%rbp)
4004f4: 89 75 f8 mov %esi,-0x8(%rbp)
4004f7: 8b 45 f8 mov -0x8(%rbp),%eax
4004fa: 8b 55 fc mov -0x4(%rbp),%edx
4004fd: 01 d0 add %edx,%eax
4004ff: 5d pop %rbp
400500: c3 retq
0000000000400501 <main>:
400501: 55 push %rbp
400502: 48 89 e5 mov %rsp,%rbp
400505: 48 83 ec 10 sub $0x10,%rsp
400509: c7 45 fc 02 00 00 00 movl $0x2,-0x4(%rbp)
400510: c7 45 f8 03 00 00 00 movl $0x3,-0x8(%rbp)
400517: 8b 55 f8 mov -0x8(%rbp),%edx
40051a: 8b 45 fc mov -0x4(%rbp),%eax
40051d: 89 d6 mov %edx,%esi
40051f: 89 c7 mov %eax,%edi
400521: e8 c7 ff ff ff callq 4004ed <add>
400526: 89 45 f4 mov %eax,-0xc(%rbp)
400529: b8 00 00 00 00 mov $0x0,%eax
40052e: c9 leaveq
40052f: c3
返回地址 = 0x400526,那么 call 指令的地址 = 0x400526 - 5 = 0x400521,知道call指令的地址对该地址进行寻址,获取到指令的编码 e8 c7 ff ff ff,就能够获取到被调用函数 add 的入口地址。
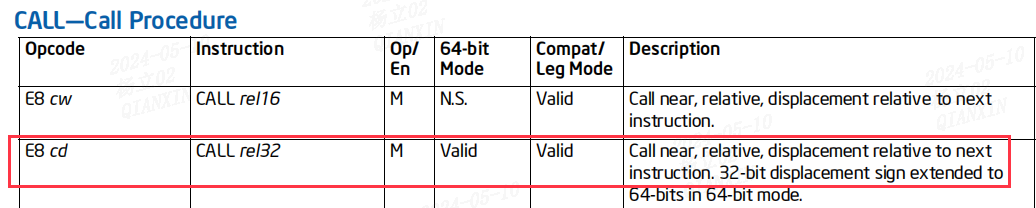
所以可以根据call机器指令的特征码E8来找到函数返回地址和被调用函数地址。
Call near, relative, displacement relative to next instruction.
计算公式:目的地址(被调函数首地址)的计算方法为: 目的地址 = 返回地址 + 相对偏移(四字节机器码)
偏移量是相对于call指令下一条指令的便宜,因此被调用函数 add 的入口地址 =
0x400526 + 0xffffffc7 = 0x4004ed
然后根据地址0x4004ed查询符号表就可以获取到 add 函数名。
x86_64通过帧指针FP(RBP寄存器)来实现函数返回地址,被调用函数地址的获取:
获取 add 函数 栈帧中保存的RBP寄存器的地址 a
--> a + 8 是返回地址所在的位置,对该位置取值 *(a + 8)获取其返回地址b,即main函数call add函数下一条指令的地址
--> b - 5 是main函数call指令的地址
--> 对main函数call指令的地址进行寻找,获取指令编码
--> add 函数的地址 = 返回地址 + 相对偏移(四字节机器码)
--> 然后通过访问 rbp 寄存器指向的caller rbp 的值来获取到调用caller函数的栈帧指针的值 c = *a ,有了这个值 c 就可以不断的回溯上方的栈帧,一个栈帧就是一个调用层次。
参考资料
https://accu.org/journals/overload/31/173/bendersky/
https://www.cnblogs.com/lsh123/p/7804845.html
https://blog.csdn.net/Longyu_wlz/article/details/103327538

















 2544
2544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









