







《Pixel convolutional neural network for multi-focus image fusion》阅读笔记
最近要修改一个多聚焦图像融合的模型,要考虑数据集的设计。由于模型与损失函数的设计要求单张训练数据中要包含聚焦区域与失焦区域,因此数据集的设计不能单纯模仿CNN Fuse的方式。这篇文章的数据集设计方式恰好可以作为参考。
1、概述
CNN Fuse是第一次将卷积神经网络强大的特征提取能力运用到多聚焦图像融合中。《Pixel convolutional neural network for multi-focus image fusion》这篇文章主要是对多聚焦图像融合方法CNN Fuse不足之处的改进。
CNN Fuse主要利用CNN网络强大的特征提取能力,解决了基于空间域的传统多聚焦图像融合方法需要人为设计方法判断聚焦区域与失焦区域的不足
CNN Fuse还存在几个问题:
1、非端到端,无法单次进行多张输入图像的融合
2、对于方法中人为产生的数据集是否能模拟实际的聚焦于失焦的情况存在争议
3、CNN Fuse本质还是基于空间域块方法的多聚焦图像融合方法,因此会受块效应的影响,且基于空间域的块方法会有同一块中既包含失焦区域也包含聚焦区域的问题。
本文提出的p-CNN主要有以下几个特点:
1、利用CNN网络提取图像特征
2、基于空间域的像素级方法
3、通过公有数据集加多种不同程度的模糊滤波以及更精确的模糊标签分级创建数据集,来减轻块效应,同时产生像素级预测效果(是否有效?)
4、非端到端网络
2、数据集生成
作者提到,一个好的数据集应该有以下几点属性:
1、数据集太小模型一般很难学到有用的特征
2、如果训练数据尺寸太大那么同一个训练数据中同时包含聚焦与非聚焦区域的概率也就越大
3、训练数据及要有足够的规模支撑p-CNN学习到有用的特征
作者在设计数据集时参考了CNN Fuse的设计方式,在公有数据集Cifar-10(60000张32×32的数据,50000张训练10000张测试)上进行改进。
具体生成方式参考以下两图。


作者主要进行了两步操作
1、分别利用标准差为2,尺寸为2,4,8,16的高斯滤波器对图像进行滤波并将得到的数据分为三部分失焦(尺寸为8,16滤波器滤波得到),聚焦(原图),未知(尺寸为2,4滤波器滤波得到)。
2、为了模仿真实单聚焦图像里既含有聚焦区域有含有失焦区域,作者设计了12个32×32的Mask对图像进行滤波,其中Mask黑色部分对应原数据保持不变,白色部分正常进行模糊操作。并对上一步的分类再次细化(Fig.2后两列)其中被Mask1-6滤波的标为失焦,Mask7-12滤波的标为聚焦。(总的来说是结合图像模糊程度与模糊面积来对图像打标签)
经过以上两步操作以后得到的训练集包括13×50000聚焦,14×50000聚焦,2×50000未知。
3、p-CNN网络结构
p-CNN网络输入为32×32的图像,输出为为属于聚焦,未知,失焦的概率。网络本质为图像分类网络。作者之前设计了深度的网络(包含10层卷积,3层池化,2层全连接)与简单的网络(如下图),两者分类准确率相差不多(深层98.9%,简单98.5%),因此选择了简单的网络结构。
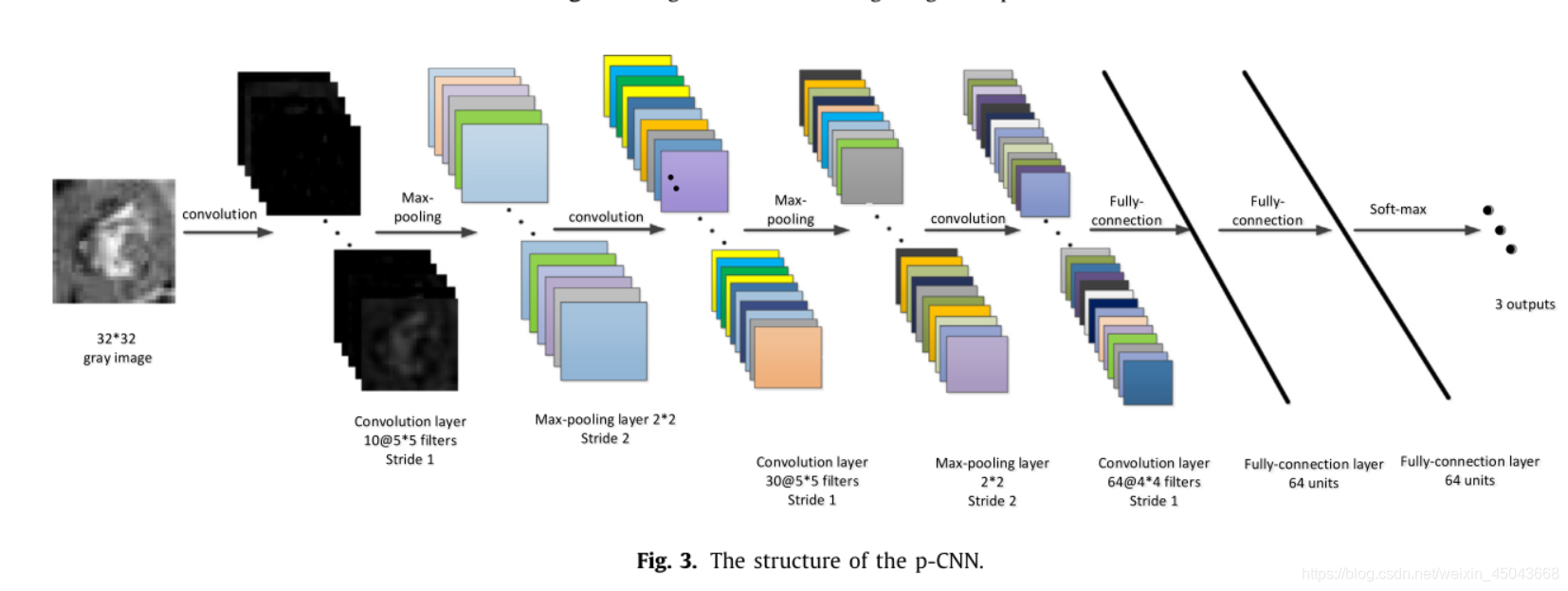
网络训练采用AlexNet的参数进行初始化;优化器选用SGD;batchsize = 128;动量系数 = 0.9;权重衰减0.0005;学习率0.01;每一层的权重取零均值高斯分布,标准偏差为0.01
image-CNN
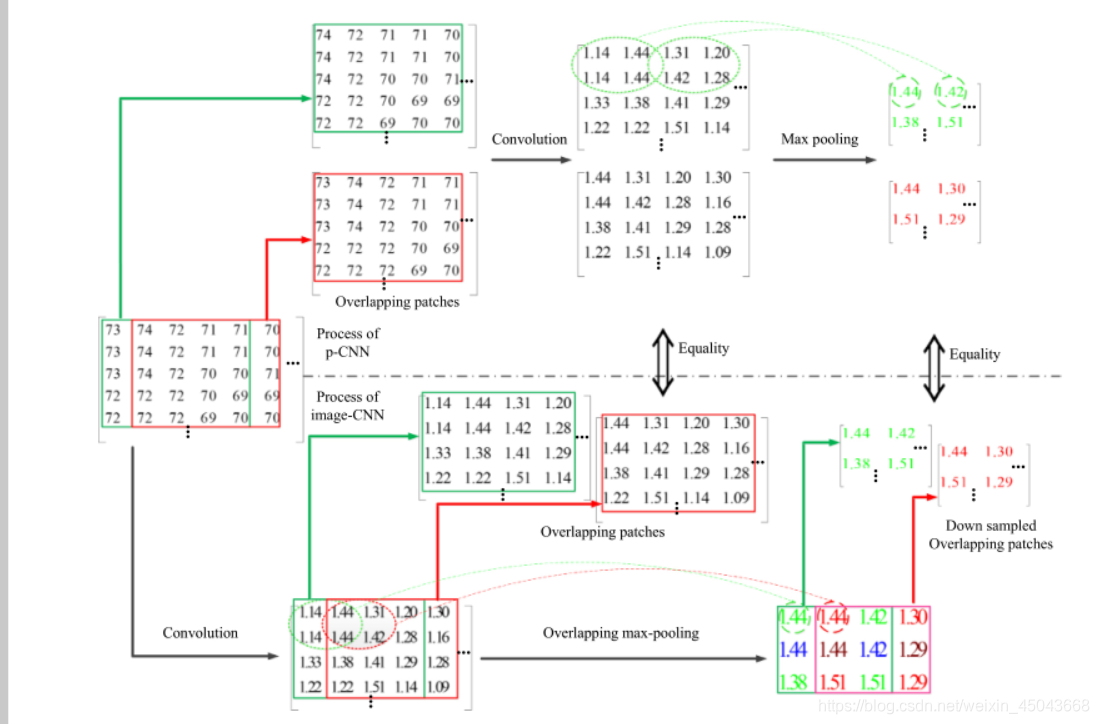
p-CNN在前向推理时将将输入图像分割成重叠的32×32的区域,区域中心对应输入图像的每个像素,对于m×n的输入图像则需要生成m×n个32×32的区域分别送入网络进行预测,这样对于一张输入图像就要运行m×n次p-CNN网络,时间消耗大,因此作者提出了image-CNN算法,来优化这个问题。image-CNN网络通过一次输入整张图就可以达到和p-CNN相同的效果,下图为二者关系:
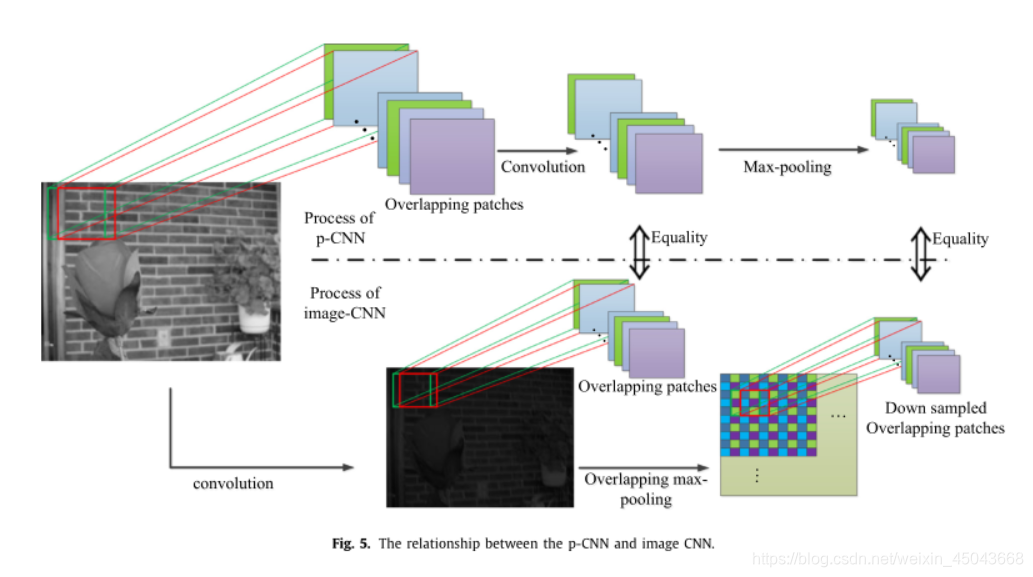
结合下图可以更好的理解两者之间的联系:
4、图像融合
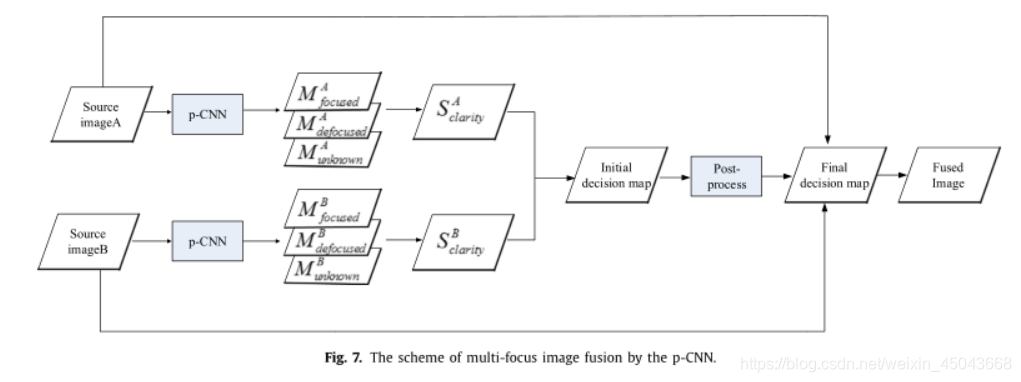
图像融合部分,分为特征提取,后处理,融合三部分。
1、特征提取
先通过p-CNN网络对待融合图像进行特征提取并对每个像素进行分类(聚焦,失焦,未确定),得到输入对应的输入图像得分图,综合两个输入图像的分类图得到初始决策图。
输入图像得分图的生成可以用以下公式表示:
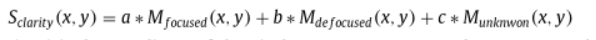
其中a,b,c是权重系数。Mfocused,Mdeocused,Munknown分别为网络预测的图像中个像素属于三个类别的可能性,作者最终确定a=0.4,b=-0.4,c=0.2(作者认为b设置为负值是为了降低失焦区域对决策图的影响)。
通过得分图得到初始决策图的过程可以用下图表示:
在初始得分图中1代表聚焦区域Focused,0代表失焦区域Defocused。
2、后处理
后处理主要是将初始决策图进行进一步处理,去除噪声得到最终决策图。
作者认为,初始得分图中总有被聚焦区域包裹的小片失焦区域(反之亦然),这些点可以看成是噪声点,因此要去掉(感觉参考了CNN Fuse的小区域移出后处理步骤)。作者使用的方法是将面积小于阈值的失焦区域改为聚焦区域,面积小于阈值的聚焦区域直接移除,阈值定义为输入图像面积的1/100。得到最终决策图。
3、融合
根据最终决策图对两张输入图像进行加权得到最终融合图像:
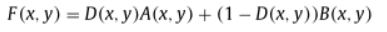
网络各步骤的输出图像如下图所示:

5、实验结果
在图像plant上的测试结果

在clock上的测试结果
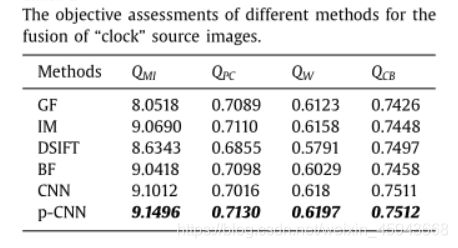
在其他指标上的对比
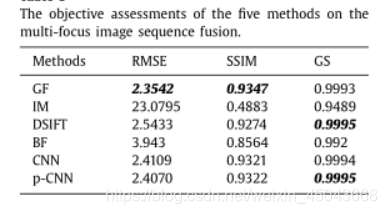
作者之后还提供了更多图像的测试结果,这部分和我们的方法中都用了Qcb这个评估指标,大致看起来这个评估指标上应该还是我们的方法更好一些。
程序运行效率
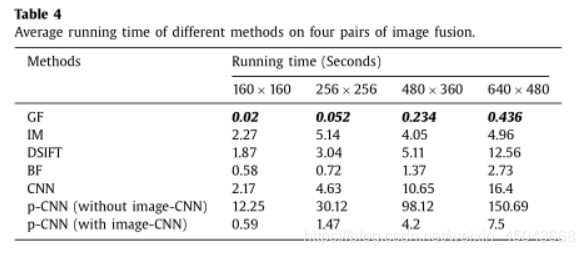
算法效率在尺寸小于640×480的图片上表现还不错。
感觉文章生成数据集方式值得借鉴,按文章的实验结果来看这种数据集训练出的网络可以实现图像融合的效果。














 5750
5750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









