









《Image Segmentation-based Multi-focus Image Fusion through Multi-scale Convolutional Neural Network》
一、概述
文章通过基于图像分割的方式进行多聚焦图像融合。文章发表于2017年,与CNN Fuse的论文同年发表,从内容上看像是基于CNN Fuse的改进。 算法整体思路与CNN Fuse思路较为相近,区别在于作者引入了多尺度的思想。
二、多尺度卷积模型
1、算法总体流程


- 待融合图像通过多尺度卷积网络提取特征,生成与输入图像相同尺寸且包含其聚焦与失焦信息的特征图
- 将特征图利用阈值0.9二值化为二值图,并利用形态学变换(主要用于删除特征图中面积小于输入图像百分之一大小的小区域),分水岭变换等后处理操作对特征图及进行后处理生成最终决策图
- 利用最终决策图对待融合图像加权,完成图像融合
2、多尺度卷积网络实现
- 多尺度提取
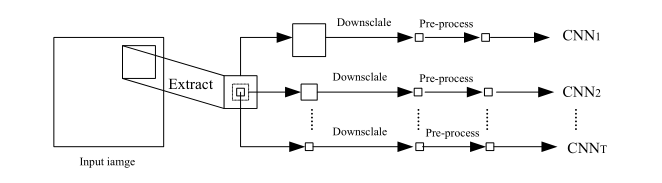
多尺度提取按以下步骤进行(文中取T=3):
(1)作者定义了三种尺度的window(分别为16×16、32×32、64×64)以输入图像每个像素点为中心截取这三个尺度的区域(原图为m×n大小则共需截取mn3个区域)
(2)将32×32以及64×64的区域下采样到16×16
(3)将得到的三个16*16区域进行90°/180°翻转的预处理,使网络能够学习到旋转不变性
(4)将预处理后的数据送入网络训练(这部分图像难道是有标注过的数据?文章中没有写清楚) - 卷积网络网络训练思路
作者认为多聚焦图像融合可以看作一个二值分割的问题。因此卷积网络模型训练的目标如下:
对于相同区域的图像对{Pa,Pb},训练一个输出范围为[0,1]的CNN网络,网络输出接近1,说明Pa为聚焦区域Pb为失焦区域,反之则Pb为聚焦区域Pa为失焦区域。网络这部分思路与CNN Fuse的思路基本一致。
文中未提到T个CNN网络是否共享参数仅仅提到网络结构相同,参数应该是不共享的。CNN网络具体结构如下所示:

此处的Mc对应算法总流程中M1-MT中的一个。
3、Inter fusion
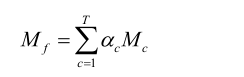
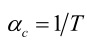
4、后处理
- 阈值为0.9的二值化操作
- 利用形态学变换,删除特征图中面积小于输入图像1/100大小的小区域
- 进一步利用分水岭算法得到最终决策图
5、融合
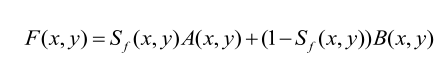
其中F为融合结果,S为最终决策图,A与B为两张待融合图像。
三、算法结果评估
作者对比了另外四种方法:MWGF、SSDI、CNN Fuse、DSIFT,结果如下:
- 主观评估



- 客观评估
















 4272
4272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









