






 本文详细介绍了GCN模型在train.py中的调用过程,包括参数定义(如nfeat、nhid、dropout),以及图卷积层的结构、权重初始化和前馈运算。重点阐述了如何从contentfile和citesfile中加载数据,构建图并进行归一化处理。
本文详细介绍了GCN模型在train.py中的调用过程,包括参数定义(如nfeat、nhid、dropout),以及图卷积层的结构、权重初始化和前馈运算。重点阐述了如何从contentfile和citesfile中加载数据,构建图并进行归一化处理。
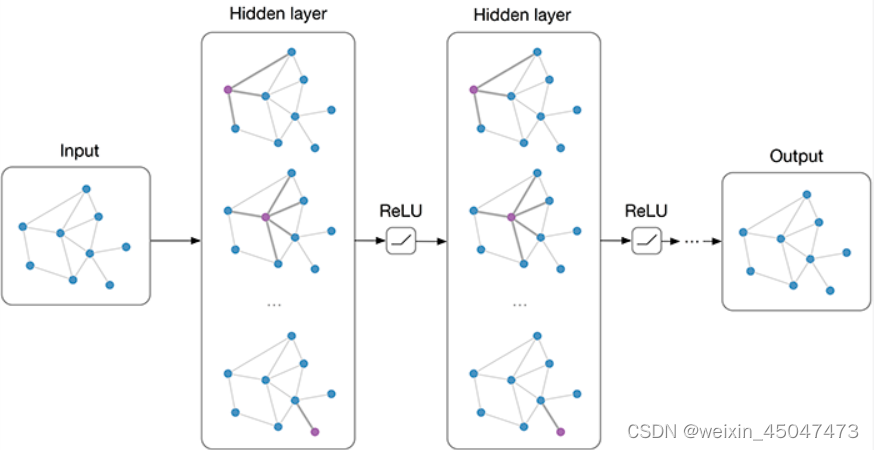
一、模型结构定义
1.1调用位置
train.py中调用模型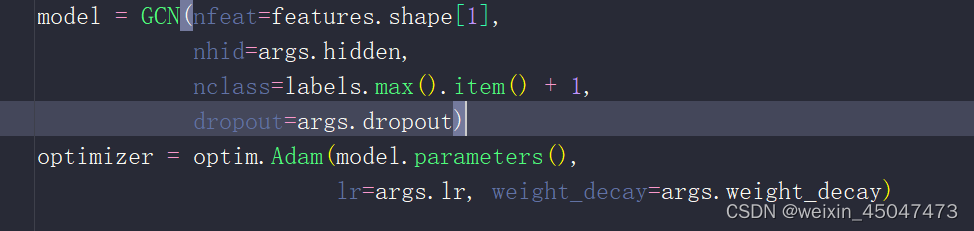
1.2传入参数
model.py:
- nfeat为底层节点的参数feature的个数
- nhid为隐藏层节点个数
- nclass最终的分类数
- dropout在训练过程中随机关闭神经元的比例,用于防止过拟合

1.3GCN定义
gcl1输入尺寸nfeat,输出尺寸nhid
gcl2输入尺寸nhid,输出尺寸nclass
1.4网络结构
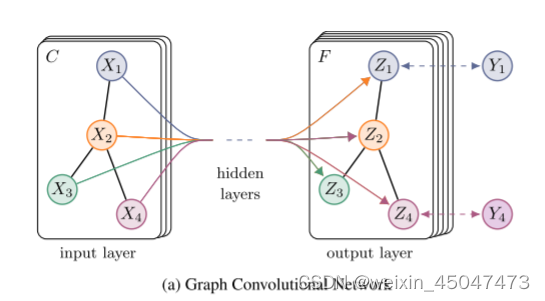
论文公式:
- 其中:A是对称邻接矩阵,由如下构造对称性:
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)。。
W0是输入层到隐藏层的权重矩阵,W1是隐藏层到输出层的权重矩阵
代码实现:
adj=A是对称邻接矩阵
二、图卷积层
2.1层初始化定义GraphConvolution
in_features:输入特征那的维度
out_features:输出特征的维度
bias:bool型是否使用偏置项
weigt:可学习的权重矩阵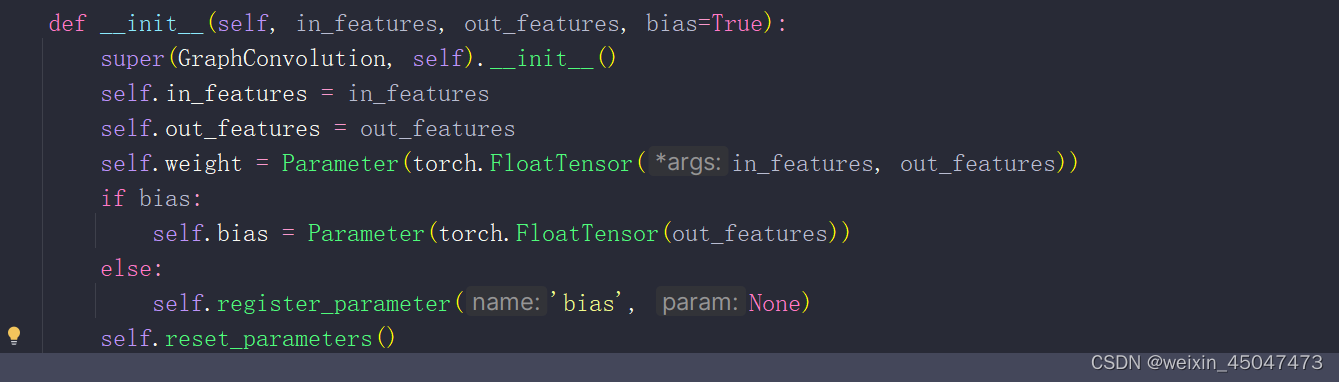
2.2初始化权重reset parameters
weight或bias.data.uniform_(-stdv,stdv):初始化为均匀分布在(-stdv,stdv)范围内的值,
其中stdv是根据权重大小计算的标准差的倒数,用于确定初始化值的范围。
2.3前馈运算forward
论文中是三个矩阵相乘:
input:输入特征矩阵 adj:邻接矩阵
support:输入特征矩阵和权重矩阵的矩阵乘法,XW
output:邻接矩阵和support的稀疏矩阵乘法,实现图卷积,AXW
如果bias=true,则将其加到输出上
三、加载数据
3.1content file
core数据集,7个类别:
Case_Based
Genetic_Algorithms
Neural_Networks
Probabilistic_Methods
Reinforcement_Learning
Rule_Learning
Theory
<paper_id> <word_attributes>+ <class_label>
第一列:paper_id,第二系列:词汇表中的每个单词是否出现在该论文中,第三:类别标签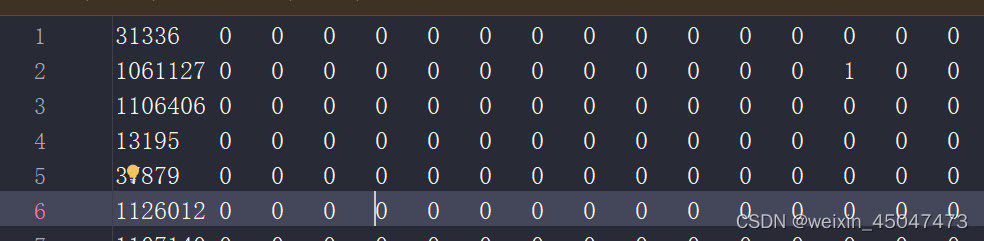

3.2cites file
<ID of cited paper> <ID of citing paper>
前面为被引用论文的id,后面为引用前面的论文id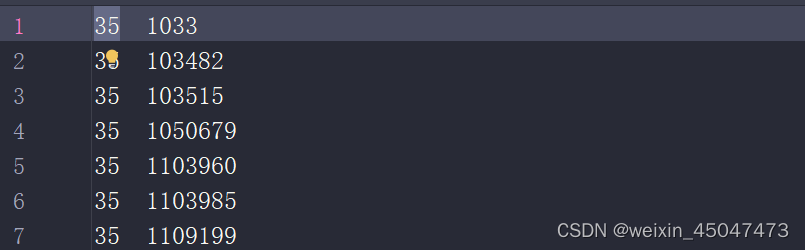
3.3读取数据
3.3.1content file读取:
构建特征矩阵features:第2列到倒数第2列
对标签进行独热编码labels:选取每行的最后一个元素

3.3.2citesd读取
构建图:根据contecontents与cites创建图,算出edges矩阵和adj矩阵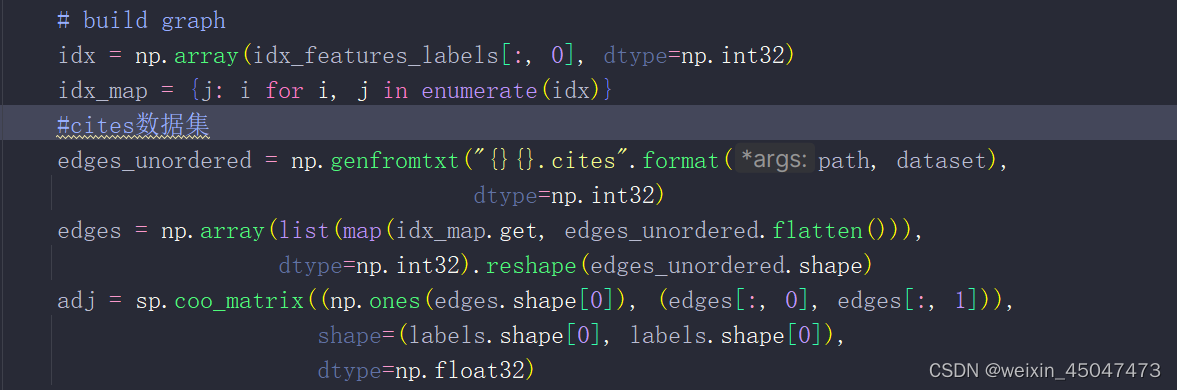
矩阵定义:
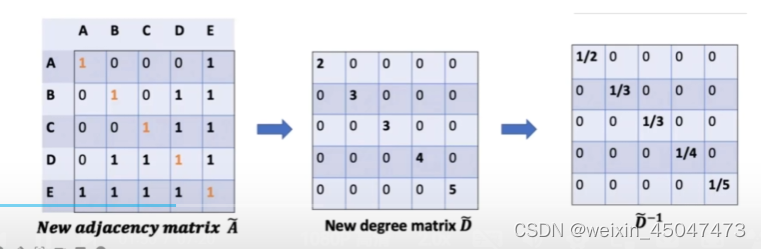
3.3.3运算 symmetric adjacency matrix A (无向性)
论文中的计算方式为:,
,IN为单位矩阵,表示:加上自连接的邻接矩阵
,加上自连接后的节点度数

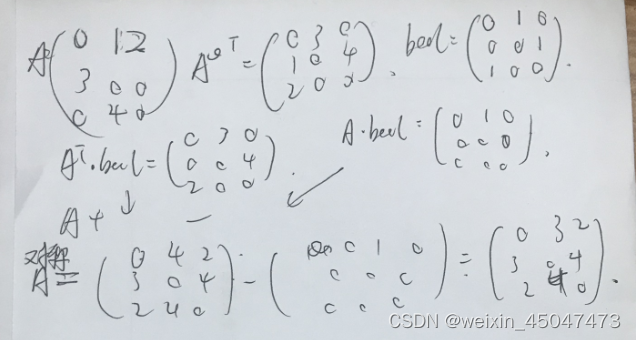
3.3.4 归一化运算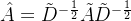
论文中的计算方式为:,
,IN为单位矩阵,表示:加上自连接的邻接矩阵
,加上自连接后的节点度数
为啥要对做归一化?
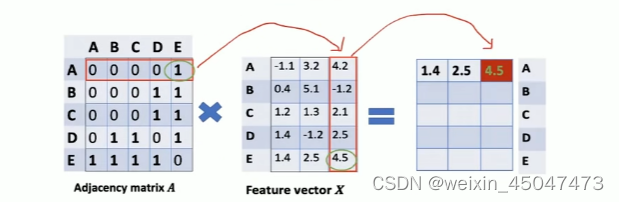
首先,输入的特征矩阵X 去乘以邻接矩阵A 目的是将节点的邻居特征信息 聚合到中心节点
其次,算AX=F矩阵乘法时,度越大的节点,所求的特征矩阵F的特征就很大(比如D节点)。
但是,特征信息并不一定和度 成正相关,所以要剔除 度的影响,
所以,通过左行右列乘D的逆 对A做归一化
(其实就是A*1/D 求平均的感觉)
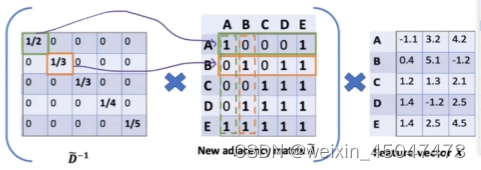
代码实现:
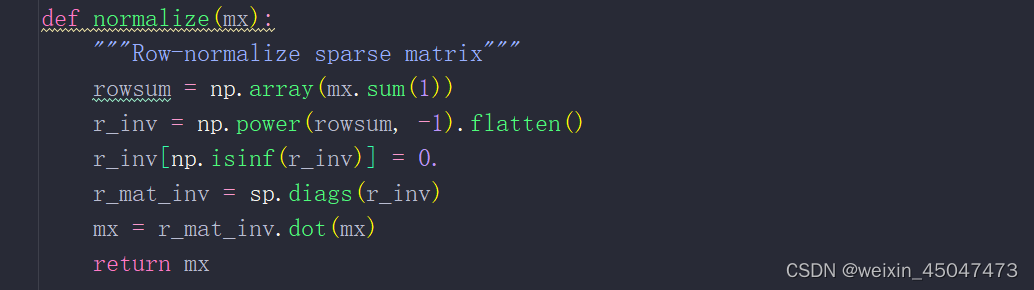 mx.sum(1) 对矩阵每一行元素求和,邻接矩阵每一行的和是 节点的度
mx.sum(1) 对矩阵每一行元素求和,邻接矩阵每一行的和是 节点的度
np.power(rowsum,-1) 对度取倒数得到归一化因子
r_inv[np.isinf(r_inv)]=0 将任何无穷大的值替换为0,因为有度为0的情况这时除以0导致数值无穷大
r_mat_inv=sp.diags(r_inv) 将归一化因子构建成一个对角矩阵
最后将对角矩阵和原矩阵相乘,进行归一化。
参考Graph Convolution Network图卷积网络(一)训练运行与代码概览_graph convolution layer代码-CSDN博客















 1060
1060











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









