






尽力啦,码字好痛苦
目录
前言
初次运行自监督学习相关的模型,有较大意义,故记录在此。MAE在此我不再赘述,代码均以mmselfsup文件夹为工作空间,安装问题需要注意mmselfsup,mmclassification,mmengine的版本对应问题,在此我不赘述,请使用源码安装方式。
提示:以下是本篇文章正文内容,下面案例可供参考
一、自定义数据集准备
1.遥感分类数据集NWPU-PESISC45
共包含45类,每类包含700张256*256大小的RGB三通道图片。类别包括:飞机、机场、棒球场、篮球场、海滩、桥梁、丛林、教堂、圆形农田、云、商业区、密集住宅、沙漠、森林、高速公路、高尔夫球场、地面田径、港口、工业地区、交叉口、岛、湖、草地、中型住宅、移动房屋公园、山、立交桥、宫、停车场、铁路、火车站、矩形农田、河、环形交通枢纽、跑道、海、船舶、雪山、稀疏住宅、体育场、储水箱、网球场、露台、火力发电站和湿地。下载地址为:https://aistudio.baidu.com/aistudio/datasetdetail/51873
2.重构数据集
(1)原始数据集组织格式
NWPU-RESISC45/
├── airplane
│ ├── xxx.png
│ ├── xxy.png
│ └── ...
├── airport
│ ├── 123.png
│ ├── 124.png
│ └── ...
(2)数据集划分
教程里面有写哈,有两种可选的数据格式,而NWPU这个数据集已经是这种格式,只需要按比例剖分出预训练数据集、fine-tune训练以及验证测试数据集就可以了,验证测试用的是同一个文件夹
准备数据集 — MMClassification 1.0.0rc5 文档
预训练数据集:finetune训练数据集:验证测试数据集=8:1:1
处理代码如下:
需要注意的是,这个代码是把所有图片放入一个文件夹中,这样是可以进行预训练的,但是后面的finetune不行哈,需要使用还是自己修改一下
##深度学习过程中,需要制作训练集和验证集、测试集。
import os, random, shutil
def moveFile(fileDir):
pathDir = os.listdir(fileDir) # 取图片的原始路径
filenumber = len(pathDir)
rate = 0.8 # 自定义抽取图片的比例,比方说100张抽10张,那就是0.1
picknumber = int(filenumber * rate) # 按照rate比例从文件夹中取一定数量图片
sample = random.sample(pathDir, picknumber) # 随机选取picknumber数量的样本图片
for name in sample:
shutil.move(fileDir + name, tarDir + name)
return
if __name__ == '__main__':
fileDir = "./data/NWPU-RESISC45/" # 源图片文件夹路径
tarDir = './data/NWPU/pretrained_prepared/selfsup-data/' # 移动到新的文件夹路径
for dir,dirname, filename in os.walk(fileDir):
for i in dirname :
print(i)
classfile=fileDir+i+"/"
moveFile(classfile)
# for i,a,b in os.walk(fileDir):
# print(i)
# print(a)
(3)划分结果
预训练数据集
finetune训练数据集,验证测试数据集类似
二、预训练
1.配置文件
复制已有的模板在其上修改是最快的方法,找到预训练配置文件configs/selfsup/mae/mae_vit-base-p16_8xb512-coslr-400e_in1k.py,复制并重命名为mae_vit-base-p16_8xb512-coslr-400e_NWPU.py并修改。 '../_base_/schedules/adamw_coslr-200e_in1k.py'为训练策略文件,可以修改训练的epochs等,默认为200个epochs。本次实验设置 batch_size=32,num_workers=4,epochs=400,大家根据自己的情况设定。
_base_ = [
'../_base_/models/mae_vit-base-p16.py',
# '../_base_/datasets/imagenet_mae.py',
'../_base_/schedules/adamw_coslr-200e_in1k.py',
'../_base_/default_runtime.py',
]
#custom dataset
#修改为自定义数据集类别
dataset_type = 'mmcls.CustomDataset'
data_root = 'your_path' # 预训练数据集路径
file_client_args = dict(backend='disk')
#视觉变换管道,主要用于数据增强以及扩充,输出结果作为模型的输入数据,提供模型的泛化能力
view_pipeline = [
dict(type='RandomResizedCrop', size=224, backend='pillow'),
dict(type='RandomFlip', prob=0.5),
dict(
type='RandomApply',
transforms=[
dict(
type='ColorJitter',
brightness=0.8,
contrast=0.8,
saturation=0.8,
hue=0.2)
],
prob=0.8),
dict(
type='RandomGrayscale',
prob=0.2,
keep_channels=True,
channel_weights=(0.114, 0.587, 0.2989)),
dict(type='RandomGaussianBlur', sigma_min=0.1, sigma_max=2.0, prob=0.5),
]
######训练数据管道,主要将原始数据转换为深度学习模型能够接受的格式
train_pipeline = [
#从文件中加载图像
dict(type='LoadImageFromFile', file_client_args=file_client_args),
dict(type='MultiView', num_views=2, transforms=[view_pipeline]),
#打包成一个字典
dict(type='PackSelfSupInputs', meta_keys=['img_path'])
]
#字典列表为输入,数据加载器
train_dataloader = dict(
batch_size=32,
num_workers=4,
persistent_workers=True,
#采样器
sampler=dict(type='DefaultSampler', shuffle=True),
collate_fn=dict(type='default_collate'),
dataset=dict(
type=dataset_type,
data_root=data_root,
# ann_file='meta/train.txt',
# data_prefix=dict(img_path='./'),
pipeline=train_pipeline))
# optimizer
optimizer = dict(
lr=1.5e-4 * 4096 / 256,
paramwise_options={
'ln': dict(weight_decay=0.),
'bias': dict(weight_decay=0.),
'pos_embed': dict(weight_decay=0.),
'mask_token': dict(weight_decay=0.),
'cls_token': dict(weight_decay=0.)
})
optimizer_config = dict()
# learning policy
lr_config = dict(
policy='StepFixCosineAnnealing',
min_lr=0.0,
warmup='linear',
warmup_iters=40,
warmup_ratio=1e-4,
warmup_by_epoch=True,
by_epoch=False)
# schedule
runner = dict(max_epochs=400)
# runtime
checkpoint_config = dict(interval=1, max_keep_ckpts=3, out_dir='')
persistent_workers = True
log_config = dict(
interval=100, hooks=[
dict(type='TextLoggerHook'),
])2.终端命令
#打开终端,激活环境进入到mmselfsup文件夹
python tools/train.py config=configs/selfsup/mae/mae_vit-base-p16_8xb512-coslr-400e_NWPU.py
###因为电脑电源线接触不良,训练到190个epoch时不小心断开了
##重新恢复训练
python tools/train.py config=configs/selfsup/mae/mae_vit-base-p16_8xb512-coslr-400e_NWPU.py -RESUME=work_dirs/selfsup/mae_vit-base-p16_8xb512-coslr-400e_NWPU/epoch_190.pth3.损失可视化
mmselfsup框架提供了analyze_log可视化曲线工具,但是会报错,不如自己写一个哈
代码如下:
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
import json
##日志路径,其中数据类型为字典
data_path_1 = "work_dirs/selfsup/mae_vit-base-p16_8xb512-coslr-400e_NWPU/log0_600.json"
def read_json(data_path, key_1, key_2):
iter, acc_seg = [], []
with open(data_path, 'r') as f:
content = f.readlines()
for line in content:
print(line)
if "ft" in data_path:
if key_1 in line:
iter.append(json.loads(line)[key_1])
if key_2 in line:
acc_seg.append(json.loads(line)[key_2])
else:
if key_1 in line:
if json.loads(line)[key_1] in iter:
continue
else:
iter.append(json.loads(line)[key_1])
if key_2 in line:
# if json.loads(line)["mode"] == stage::
acc_seg.append(json.loads(line)[key_2])
print(line)
else:
continue
return iter, acc_seg
##可视化字典的键名与键值,对应x与y轴
iter_1, acc_seg_1 = read_json(data_path_1,"epoch", "loss")
max_value = max(acc_seg_1)
print(max_value)
#设置横纵坐标的名称以及对应字体格式
font = {'family' : 'Times New Roman',
'weight' : 'normal',
'size' : 10,
}
index = 0
# for i in range(len(acc_seg_2)):
# if acc_seg_2[i] >= 80:
# index = i
# break
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.set_xlabel('epoch', font)
ax.set_ylabel('loss', font)
ax.plot(iter_1[index:], acc_seg_1[index:])
plt.legend(loc='upper right')
plt.show()
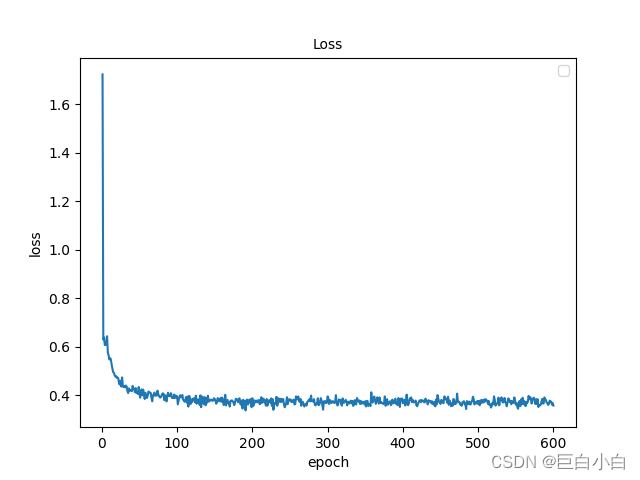
三、fine-tune
1、运行训练配置文件
复制configs/benchmarks/classification/imagenet/vit-base-p16_ft-8xb256-coslr-100e_in1k.py并重命名为vit-base-p16_ft-8xb128-coslr-200e_NWPU.py,其中修改部分与预训练文件差不多哈,我就不说了,实在不明白可以留个言。一般100个epochs还未收敛,所以我改为了200个epochs。
GPUS=1 bash ./tools/benchmarks/classification/mim_dist_train.sh configs/benchmarks/classification/imagenet/vit-base-p16_ft-8xb2048-coslr-100e_NWPU.py /home/bzy/mmselfsup/work_dirs/epoch_600.pth可能存在的问题:
问题:GPUS默认为8,修改为1(要根据自己电脑的gpu个数修改哈)

问题:在;训练、验证、测试数据集加载器中添加pin_memory=False

问题:CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling "`cublasSgemmStridedBatched"
CUDA以及pytorch降为11.0以及1.7.1版本
2、使用验证集验证结果

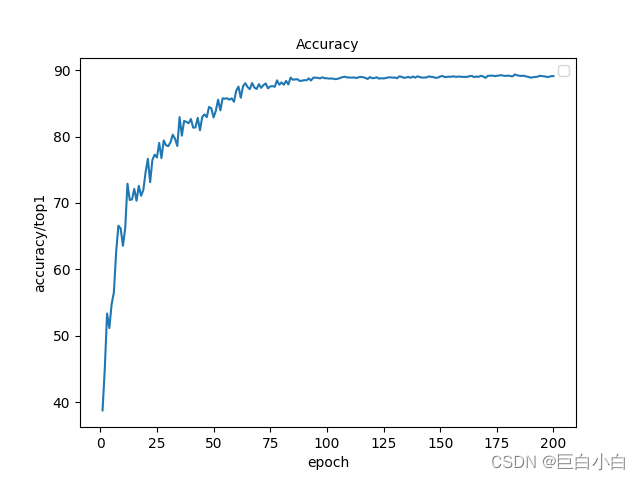
这个是用上面可视化loss曲线的代码做的哈
GPUS=1 bash ./tools/benchmarks/classification/mim_dist_test.sh configs/benchmarks/classification/imagenet/vit-base-p16_ft-8xb128-coslr-300e_NWPU.py --cfg-options randomness.seed=0 --checkpoint work_dirs/vit-base-p16_ft-8xb128-coslr-200e_NWPU/epoch_200.pth --show-dir workdir/mae --dump ceshijieguo.pkl--show-dir workdir/mae #分类图片会保存至此
--dump test_result.pkl#用于离线绘制混淆矩阵
四、结果
1、混淆矩阵
(如果类别不多可以考虑可视化,函数也写好了,但是这个数据集45类,就保存为excel表格了)
from mmengine.evaluator import Evaluator
from mmengine.fileio import load
import numpy as np
import pandas as pd
# p, top_k=(1, 5)))
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix,recall_score,precision_score,accuracy_score
def plot_confusion_matrix(cm, labels_name, title, colorbar=False, cmap=None):
plt.imshow(cm, interpolation='nearest', cmap=cmap) # 在特定的窗口上显示图像
for i in range(len(cm)):
for j in range(len(cm)):
plt.annotate(cm[j, i], xy=(i, j), horizontalalignment='center', verticalalignment='center')
if colorbar:
plt.colorbar()
num_local = np.array(range(len(labels_name)))
plt.xticks(num_local, labels_name) # 将标签印在x轴坐标上
plt.yticks(num_local, labels_name) # 将标签印在y轴坐标上
plt.title(title) # 图像标题
plt.ylabel('True label')
plt.show()
# y_true = [2, 0, 2, 2, 0, 1]
# y_pred = [0, 0, 2, 2, 0, 2]
data = load('ceshijieguo.pkl')
print(data[1])
for i in data[1]:
print(i)
print(data[1][i])
print(len(data))
Y_True=[]
Y_pred=[]
for i in range(len(data)):
gt_label=data[i]["gt_label"]["score"]
pred_label=data[i]["pred_label"]["score"]
gt_label=np.where(gt_label==1)
pred_label=np.where(pred_label==max(pred_label))
print(gt_label)
print(pred_label)
Y_True.extend(gt_label[0])
Y_pred.extend(pred_label[0])
classes=["airplane",
"airport", "baseball_diamond", "basketball_court", "beach", "bridge", "chaparral",
"church", "circular_farmland", "cloud", "commercial_area", "dense_residential", "desert", "forest",
"freeway", "golf_course", "ground_track_field", "harbor", "industrial_area", "intersection", "island",
"lake", "meadow", "medium_residential", "mobile_home_park", "mountain", "overpass", "palace", "parking_lot", "railway", "railway_station", "rectangular_farmland", "river", "roundabout",
"runway", "sea_ice", "ship", "snowberg", "sparse_residential", "stadium", "storage_tank", "tennis_court", "terrace", "thermal_power_station","wetland"]
cm = confusion_matrix(Y_True, Y_pred)
cm_normalize=confusion_matrix(Y_True, Y_pred,normalize='true')
print(cm)
plot_confusion_matrix(cm_normalize, classes, "Confusion Matrix")
data = pd.DataFrame(cm,columns=classes)
data_normal=pd.DataFrame(cm_normalize,columns=classes)
writer = pd.ExcelWriter('MAE_confusion_matrix.xlsx')
data.to_excel(writer, 'confusion_matrix', float_format='%.5f') # ‘sheet_2’是写入excel的sheet名
data_normal.to_excel(writer, 'confusion_matrix_normalize', float_format='%.5f')
recall_score = recall_score(Y_True,Y_pred,average='macro')
print(recall_score)
pre_score = precision_score(Y_True,Y_pred,average='macro')
print(pre_score)
ACC =accuracy_score(Y_True,Y_pred)
print(ACC)
writer.save()
writer.close()
2、分类结果
通过验证测试命令中--show-dir参数生成的分类结果文件夹中的图片示例如下:



3、可视化重建结果
因为官方给的命令是一张图片一张图片生成的,这里可以整个文件夹循环生成哈,浅浅改一下路径
import os
for file in os.listdir('./data/NWPU/val/'):
print(file)
for png in os.listdir(("./data/NWPU/val/"+file)):
png1="./data/NWPU/val/"+file+"/"+png
out="./data/vis/"+file+"/"+png
print(png1)
print(out)
os.system("python tools/analysis_tools/visualize_reconstruction.py configs/selfsup/mae/mae_vit-base-p16_8xb512-coslr-400e_NWPU.py \
--checkpoint work_dirs/epoch_600.pth\
--img-path {} \
--out-file {}\
--norm-pix".format(png1,out))

4、特征空间分析(tsne)
官方代码中未包含图例,于分析有碍,我添加了图例部分,自行取用哈,修改tools/analysis_tools/visualize_tsne.py绘图那一部分即可。
classes=["airplane",
"airport", "baseball_diamond", "basketball_court", "beach", "bridge", "chaparral",
"church", "circular_farmland", "cloud", "commercial_area", "dense_residential", "desert", "forest",
"freeway", "golf_course", "ground_track_field", "harbor", "industrial_area", "intersection", "island",
"lake", "meadow", "medium_residential", "mobile_home_park", "mountain", "overpass", "palace", "parking_lot", "railway", "railway_station", "rectangular_farmland", "river", "roundabout",
"runway", "sea_ice", "ship", "snowberg", "sparse_residential", "stadium", "storage_tank", "tennis_court", "terrace", "thermal_power_station","wetland"]
for key, val in results.items():
# count=count+1
# print(key)
# print(count)
# print(val)
plt.figure(figsize=(20, 20))
result = tsne_model.fit_transform(val)
res_min, res_max = result.min(0), result.max(0)
res_norm = (result - res_min) / (res_max - res_min)
labels=np.asarray(labels)
for j in range(len(classes)):
temp=np.where(labels==j)[0]
print(labels)
print(len(labels))
res_norm_part=[]
for i in temp:
res_norm_part.append(res_norm[i])
res_norm_part=np.asarray(res_norm_part)
print(res_norm_part.shape)
plt.scatter(
res_norm_part[:, 0],
res_norm_part[:, 1],
alpha=1.0,
s=150,
label=classes[j],
color=["#"+''.join([random.choice('0123456789ABCDEF') for j in range(6)])])
#marker=marker)
# label=classes
# plt.scatter(
# res_norm[:, 0],
# res_norm[:, 1],
# alpha=1.0,
# s=15,
# c=labels,
# # label=classes,
# cmap='tab20')
# print(type(labels[0]))
# print(labels[0])
# print(labels[90])
plt.legend(fontsize=16, markerscale=1, bbox_to_anchor=(1, 1))
plt.savefig(f'{tsne_work_dir}saved_pictures/{key}.png')
logger.info(f'Saved results to {tsne_work_dir}saved_pictures/') 示例图如下,这不是最终结果哈,我随便挑的一个epoch模型文件做出来的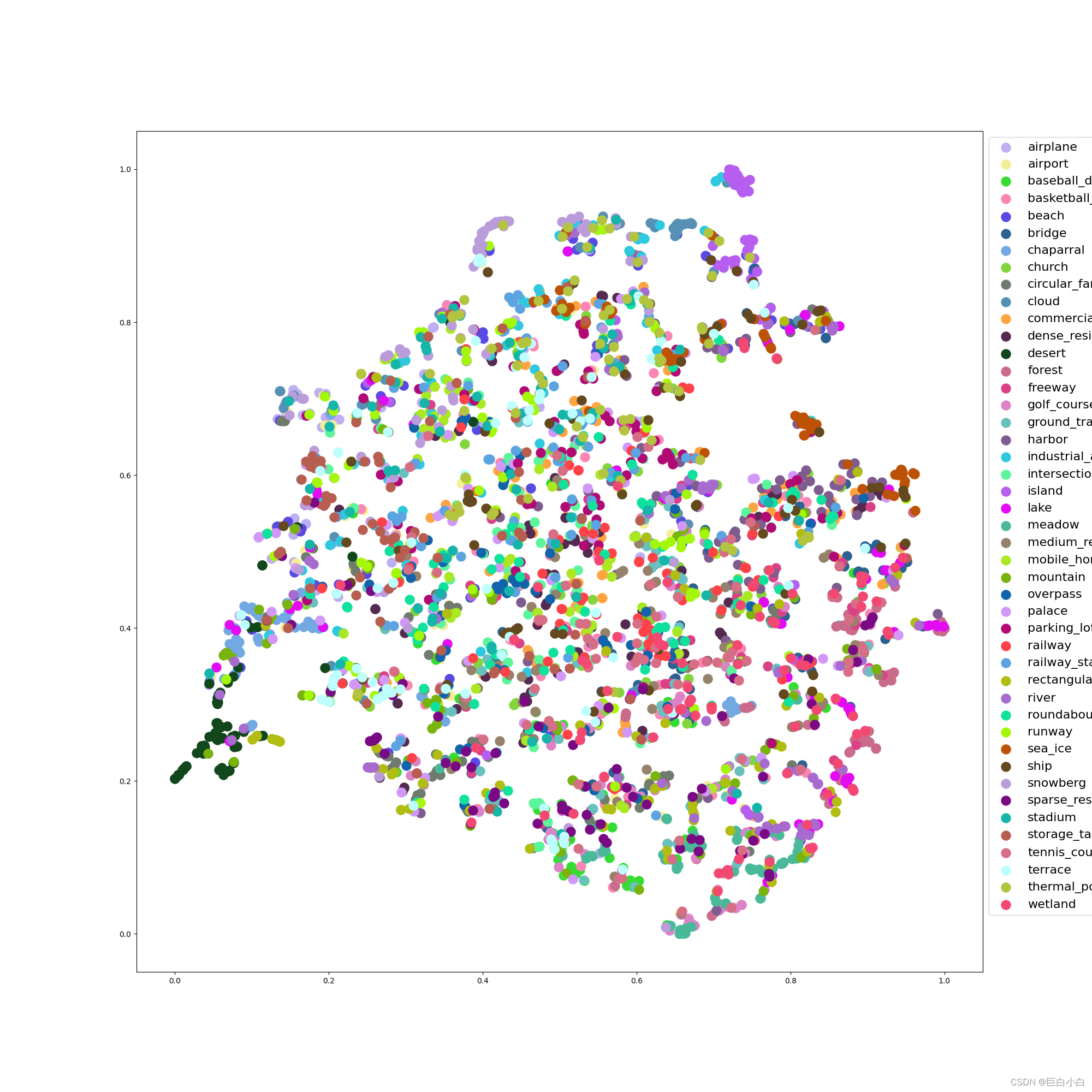
有点丑嘿嘿,大家浅浅参考一些吧,不要太多嘿嘿嘿嘿,有些代码可能有一点点bug,因为我翻来覆去改我自己也忘了谁是谁了,但是问题不会太大,是可行的!


















 4115
4115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











