






一、Pandas简介
Pandas是一个强大的分析结构化数据的工具集;
(Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的函数和方法,能够快速便捷地处理数据)
它的使用基础是Numpy(提供高性能的矩阵运算);
用于数据挖掘和数据分析,同时也提供数据清洗功能
文末放上代码、参考资料和相关数据文件
#全部行都能输出
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"二、基本操作
1.导入Pandas库并简写为pd,并输出版本号
import numpy as np
import pandas as pd
pd.__version__'1.0.3'
2.从列表创建Series
arr = [0, 1, 2, 3, 4]
df = pd.Series(arr)
df
三、文件读取与写入
1. 读取
1) csv格式
df = pd.read_csv('pandas/joyful-pandas-master/data/table.csv')
df.head()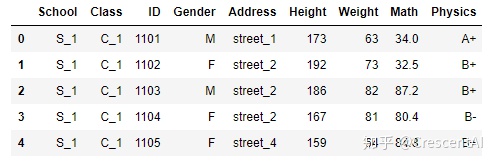
2) txt格式
df_txt = pd.read_table('pandas/joyful-pandas-master/data/table.txt')
df_txt.head()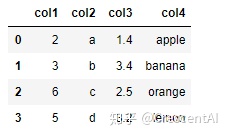
3) xls或xlxs格式
df_excel = pd.read_excel('pandas/joyful-pandas-master/data/table.xlsx')
df_excel.head()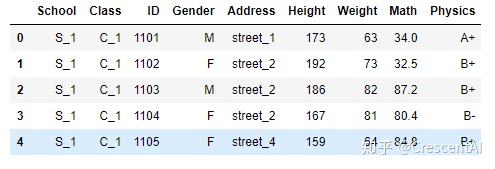
2. 写入
1) csv格式
df.to_csv('pandas/joyful-pandas-master/data/new_table.csv')2) xls或xlsx格式
df.to_excel('pandas/joyful-pandas-master/data/new_table2.xlsx', sheet_name='Sheel1')三、基本数据结构
1. 什么是Series

创建Series

1) 创建一个Series
#通过ndarray创建Series
np.random.seed(1234)
arr1=np.random.randint(1,10,(5,))
arr1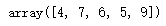
ser1 = pd.Series(arr1,index=['a', 'b', 'c', 'd', 'e']) #当data中的values多于1时,values和index的个数应一致,不一致的时候会报错
ser1
ser1 = pd.Series(arr1) #不指定索引的时候,索引默认是range(0,n)
ser1
#通过字典创建Series
dic1 = {'a' : 0., 'b' : 1., 'c' : 2.}
dic1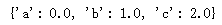
ser2 = pd.Series(dic1) #字典的数据结构是key-values键值对,不需要再单独指定索引
ser2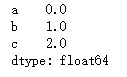
类 ndarray 的对象传入后也会转换为 ndarray 来创建 Series 。
#通过列表创建Series
list1=[1,2,3,4,5]
list1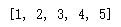
ser3 = pd.Series(list1) #没有指定显式index的时候,显示隐式索引
ser3
# 通过标量创建Series 当data只包含一个元素时,Series对象的定义支持"循环补齐"
ser4 = pd.Series(3,index=('x','y','z'))
ser4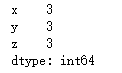
s = pd.Series(np.random.randn(5), index = ['a', 'b', 'c', 'd', 'e'], name = '这是一个Series', dtype = 'float64')
s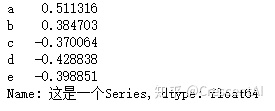
创建Series的方法
- 1 通过ndarray创建,可指定索引,但是指定索引的个数要和ndarray对象里边元素的个数一致
- 2 通过字典创建,不需要指定索婷,字典的键即索引
- 3 通过类ndarray对象创建,比如说列表,可以指定索引,但是之低昂索引的个数要和ndarray里边元素的个数一致
- 4 参数data可以是一个单独的标量,传入索引后,每个索引对应的都是统一数值的标量

2) 访问Series属性
s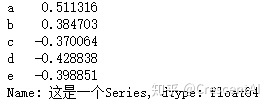
s.values # 查看values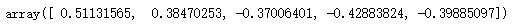
s.name # 查看Series的name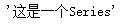
s.index # 查看index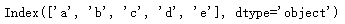
s.dtype # 查看数据类型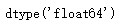
Series 数组和字典特性
- Series可以进行索引和切片操作
- Series 同时也像一个固定大小的 dict ,可以通过索引标签获取和设置值
- Series 与 ndarray 非常相似,是大多数 NumPy 函数的有效参数
3) 数组特性
s
s[0] # 通过位置信息(系统默认的隐式索引)索引查找元素0.5113156521513135
s[0] = 1 # 通过索引切片更改元素信息
s
s[1:4] # 通过位置信息索引切取连续元素
s[[4,3,0]] # 通过位置信息索引切取不连续元素
s<0.5 # 进行布尔判断
s[s<0.5] # 通过布尔判断切取满足指定条件的元素,通过布尔值进行切片,切的永远是True的元素
s[s>s.mean()] # 切片所有比均值大的元素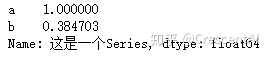
4) 字典特性
Series 同时也像一个固定大小的 dict ,可以通过索引标签获取和设置值:
s['a'] # 通过显式索引查找元素1.0
s['a'] = 0.511316
s
s['a':'c'] # 通过显式索引切取连续元素
s[['a','d','e']] # 通过显式索引切取不连续元素
'a' in sTrue
'h' in sFalse
s['h'] # 注:如果引用了未包含的标签,则会引发异常。
try:
print(s['f'])
except KeyError:
print('没有这个键')没有这个键
5) 调用方法
s.mean()-0.060346936266615005
Series有相当多的方法可以调用:
print([attr for attr in dir(s) if not attr.startswith('_')])['T', 'a', 'abs', 'add', 'add_prefix', 'add_suffix', 'agg', 'aggregate', 'align', 'all', 'any', 'append', 'apply', 'argmax', 'argmin', 'argsort', 'array', 'asfreq', 'asof', 'astype', 'at', 'at_time', 'attrs', 'autocorr', 'axes', 'b', 'between', 'between_time', 'bfill', 'bool', 'c', 'clip', 'combine', 'combine_first', 'convert_dtypes', 'copy', 'corr', 'count', 'cov', 'cummax', 'cummin', 'cumprod', 'cumsum', 'd', 'describe', 'diff', 'div', 'divide', 'divmod', 'dot', 'drop', 'drop_duplicates', 'droplevel', 'dropna', 'dtype', 'dtypes', 'duplicated', 'e', 'empty', 'eq', 'equals', 'ewm', 'expanding', 'explode', 'factorize', 'ffill', 'fillna', 'filter', 'first', 'first_valid_index', 'floordiv', 'ge', 'get', 'groupby', 'gt', 'hasnans', 'head', 'hist', 'iat', 'idxmax', 'idxmin', 'iloc', 'index', 'infer_objects', 'interpolate', 'is_monotonic', 'is_monotonic_decreasing', 'is_monotonic_increasing', 'is_unique', 'isin', 'isna', 'isnull', 'item', 'items', 'iteritems', 'keys', 'kurt', 'kurtosis', 'last', 'last_valid_index', 'le', 'loc', 'lt', 'mad', 'map', 'mask', 'max', 'mean', 'median', 'memory_usage', 'min', 'mod', 'mode', 'mul', 'multiply', 'name', 'nbytes', 'ndim', 'ne', 'nlargest', 'notna', 'notnull', 'nsmallest', 'nunique', 'pct_change', 'pipe', 'plot', 'pop', 'pow', 'prod', 'product', 'quantile', 'radd', 'rank', 'ravel', 'rdiv', 'rdivmod', 'reindex', 'reindex_like', 'rename', 'rename_axis', 'reorder_levels', 'repeat', 'replace', 'resample', 'reset_index', 'rfloordiv', 'rmod', 'rmul', 'rolling', 'round', 'rpow', 'rsub', 'rtruediv', 'sample', 'searchsorted', 'sem', 'set_axis', 'shape', 'shift', 'size', 'skew', 'slice_shift', 'sort_index', 'sort_values', 'squeeze', 'std', 'sub', 'subtract', 'sum', 'swapaxes', 'swaplevel', 'tail', 'take', 'to_clipboard', 'to_csv', 'to_dict', 'to_excel', 'to_frame', 'to_hdf', 'to_json', 'to_latex', 'to_list', 'to_markdown', 'to_numpy', 'to_period', 'to_pickle', 'to_sql', 'to_string', 'to_timestamp', 'to_xarray', 'transform', 'transpose', 'truediv', 'truncate', 'tshift', 'tz_convert', 'tz_localize', 'unique', 'unstack', 'update', 'value_counts', 'values', 'var', 'view', 'where', 'xs']
2.DataFrame
DataFrame是一个可以包含不同数据类型列的二维数据结构,类似于电子表格或SQL表,或Series对象的字典集合,是最常用的pandas对象。
1)创建DataFrame
和 Series 类似,创建 DataFrame 时,也接受许多不同类的参数。虽然在绝大多数情况下,我们通过读取文件来创建 DataFrame。 DataFrame 可以从序列类的数据构建:
方法一 : 包含列表的字典创建
#使用包含列表的字典创建DataFrame时,各个列表内元素个数必须一致
data1 = {'员工姓名':['赵一','钱明','周元'], #默认字典的键为dataframe的字段名,不设定索引的时候,自动给出默认索引,从0到len(list)-1
'销售业绩':[30000,20000,50000],
'提成收入':[6000,4000,10000]}
df1 = pd.DataFrame(data1)
df1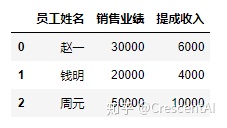
方法二 : 包含series的类字典创建
data = {'员工姓名':pd.Series(['赵一','钱明','周元','李雷']), #与第一种创建方式相比,各series中的元素个数可以不一致
'销售业绩':pd.Series([30000,20000,50000]),
'提成收入':pd.Series([6000,4000,10000])}
df2 = pd.DataFrame(data)
df2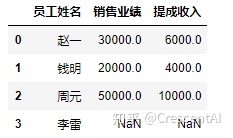
data = {'员工姓名':pd.Series(['赵一','钱明','周元','李雷'],index = ['001','002','003','004']), #指定index与不指定index的区别
'销售业绩':pd.Series([30000,20000,50000],index = ['001','002','003']),
'提成收入':pd.Series([6000,4000,10000],index = ['001','002','003'])}
df2 = pd.DataFrame(data)
df2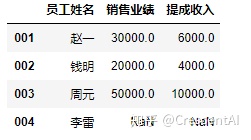
pd.DataFrame(df2, index=['003', '001', '002']) #创建的时候可以只用一部分index,而且index与记录一一对应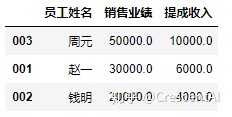
pd.DataFrame(df2, index=['003', '001', '002'], #列名(columns)可以进行指定.如果指定了不存在的列,dataframe会自动用空值补齐
columns=['提成收入', '基本工资'])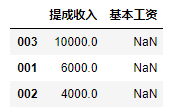
df = pd.DataFrame({'col1':list('abcde'), 'col2':range(5,10), 'col3':[1.3,2.5,3.6,4.6,5.8]},
index = list('一二三四五'))
df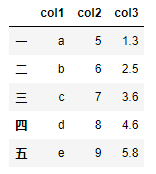
2) 访问索引和列名
df.head()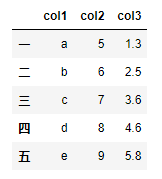
df.index #访问索引 在外部数据导入后,可以用访问索引和列名的方法对数据有有一个大概的了解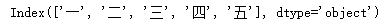
df.columns # 访问列名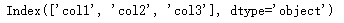
3) DataFrame 列操作
DataFrame 列的选取,设置和删除列的工作原理与类似的 dict 操作相同。
df['col1'] # 单独一个列是series数据结构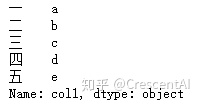
type(df)pandas.core.frame.DataFrame
type(df['col1'])pandas.core.series.Series
4) 增加列
df2['基本工资'] = 2500 #增加一列并且给增加的列赋值,如果赋值为单个标量,会自动在列里广播填充
df2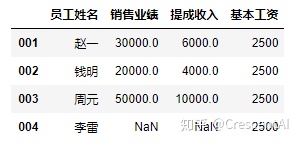
df2["创造收益"] = df2['销售业绩'] - df2['提成收入'] - df2['基本工资'] #增加一列并且给增加的列赋值,赋值可以是已存在列之间的聚合运算
df2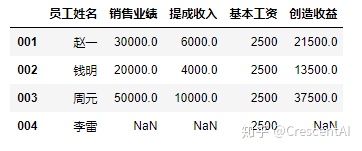
df2["是否达标"] = df2['创造收益'] > 20000 #增加一列并且给增加的列赋值,赋值可以是对其中某一列的布尔判断
df2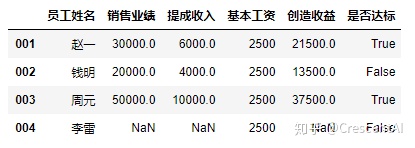
df2['公司名称'] = '脑洞大开有限公司' ##增加一列并且给增加的列赋值,赋值为标量,会自动在列里广播填充.填充的数值类型也可以是字符串类型
df2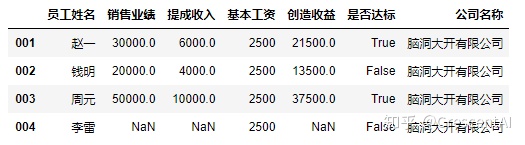
#如果新增的列中传入的是 Series 并且索引不完全相同,那么会默认按照索引对齐,没有指定填充值的位置默认用空值进行填充:
df2['性别'] = pd.Series(['女','男'],index = ['001','003'])
df2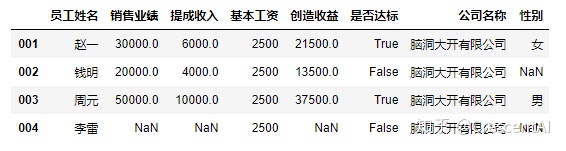
insert方法插入列
df2.insert(5,"年龄",[25,32,30,24]) #插入列,参数为指定插入位置,插入列的列名,给插入的列赋值,赋值的内容可以是列表
df2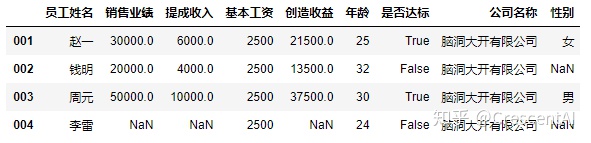
df2.insert(0,"工龄","1年") #插入列并给插入的列赋值,赋值的内容可以是标量
df2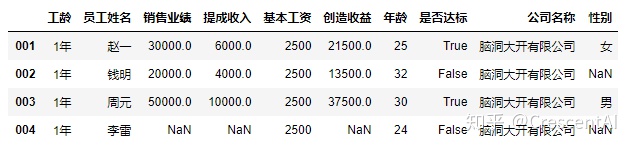
df2.insert(5,"社保金额",df2["基本工资"]*0.05) #插入列并给插入的列赋值,赋值的内容也可以是series(获取的列其数据结构是series)
df2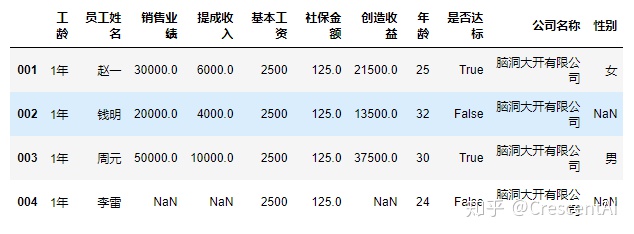
删除或移出列
del df2["工龄"] #直接在原数据集上做修改
df2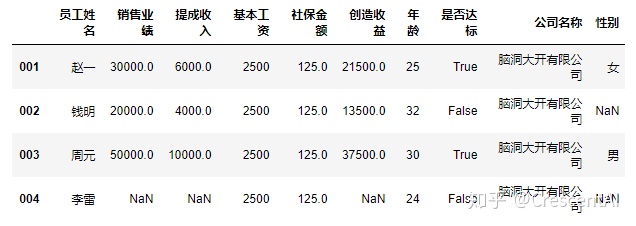
df2.pop("年龄") #抛出指定列并对原数据进行改变
df2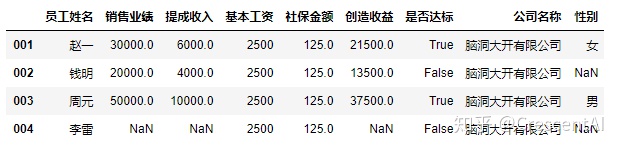
df2.drop(columns=['是否达标'],axis=1) #返回一个副本,原数据没有发生改变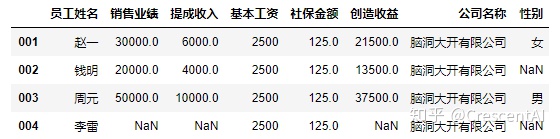
df2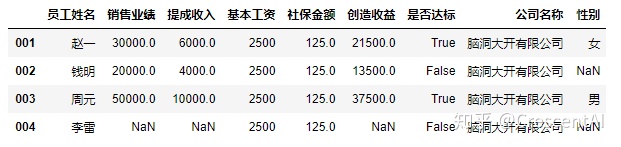
分配列的操作
assign方法,依据现有列派生的新列
df2.assign(利润率 = df2.创造收益/df2.销售业绩) #和前边单纯的插入或新增列的操作不同,返回的是视图,assign方法不会改变原数据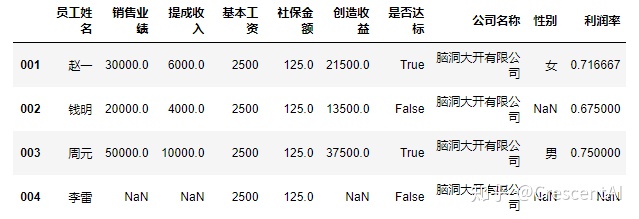
df2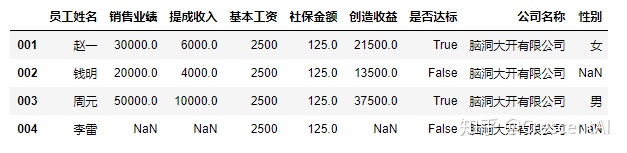
df2.assign(利润率 = df2.创造收益/df2.销售业绩, #assign方法可以同时分配多列,想要捕捉到分配列之后的dataframe,赋值新的dataframe名字给它
成本率 = (df2.提成收入+df2.基本工资)/df2.销售业绩)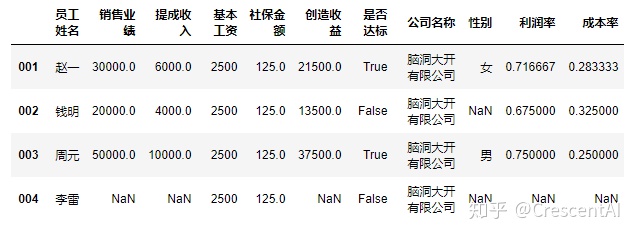
df2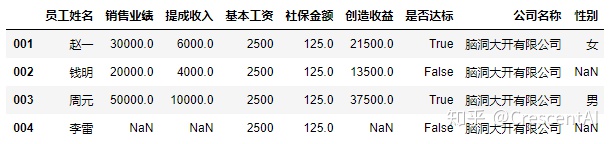
5) 调用属性和方法
df2.index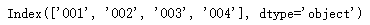
df2.columns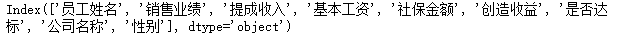
df2.values
df2.shape(4, 9)
df2.mean()
6) 索引/选择
索引/选择的基本语法如下:
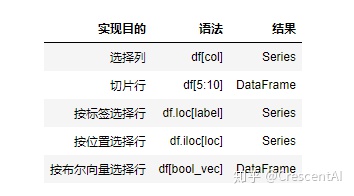
这是Pandas中非常强大的特性,不理解这一特性有时就会造成一些麻烦
df3 = pd.DataFrame({'A':[1,2,3]},index=[1,2,3])
df4 = pd.DataFrame({'A':[1,2,3]},index=[3,1,2])
df3-df4 #由于索引对齐,因此结果不是0
根据类型选择列
df.select_dtypes(include = ['number']).head()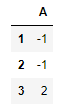
df.select_dtypes(include = ['float']).head()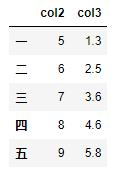
7)基于标签的索引
.loc 是基于标签的索引,必须使用数据的标签属性,否则会返回一个异常。
基于标签索引的基本语法 : df.loc[行索引,列索引]
逗号之前是切取的行信息,逗号之后是切取的列信息
只切取行信息返回所有列信息的时候,列索引和逗号可以省略
只切取列信息返回所有行信息的时候,行索引和冒号不能省略,用冒号表示切取所有行.
df2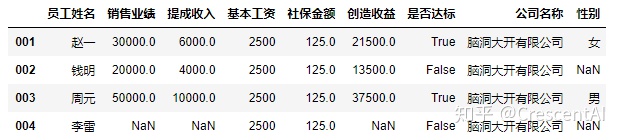
df2.loc["001"] #指窃取一行或者一列数据是返回series数据结构
直接切取一行信息的时候 - df["行信息":"行信息"] 返回是dataframe
- (基于标签的索引)df.loc["行信息"] 返回的是series
df2.loc[:,"员工姓名"] #切取一列的信息,行信息不能省略
df2.loc["001":"003"]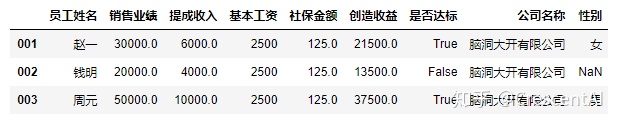
df2.loc[:,"员工姓名":"创造收益"] #切取列信息,返回所有行信息的时候注意冒号表示所有行并加逗号隔开行索引和列索引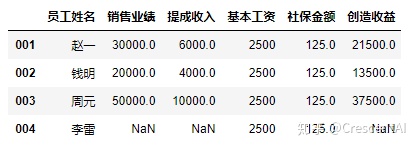
df2.loc["001":"003","员工姓名":"创造收益"] #切取完整数据框中的一部分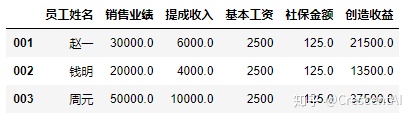
df2.loc[["001","003"]] #切取不连续的记录,选择的几行或者几列的名字需打包到列表中
df2.loc[:,["员工姓名","提成收入"]] #切取不连续的列信息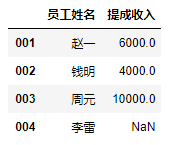
df2.loc[["001","003"],["员工姓名","创造收益","提成收入"]] #切取的行列信息都可以不连续,注意各个标签需要用方括号括起来,标签的顺序自定义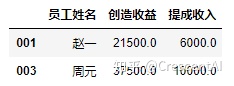
df2.loc[["001","003","004"],["员工姓名","销售业绩","是否达标"]]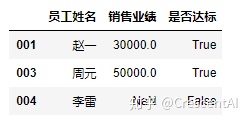
指向具体一列的某个记录值 df.at[行索引,列索引]
df2.at["001","员工姓名"]'赵一'
df2.loc["004","社保金额"]125.0
df2.loc["001","员工姓名"] #用.loc也可以实现'赵一'
df2.at["004","销售业绩"] = 40000 #可以对单个信息进行更改
df2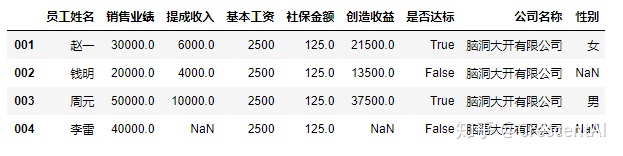
.loc 同时也可以用来扩展数据的列:
df2.loc[:,"员工状态"] = "在职"
df2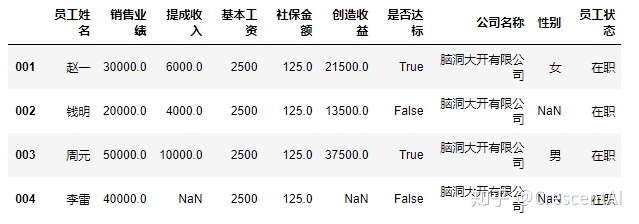
新建一列,新建列里边的信息是基于某一已经存在的列,并且对该存在列中的每个信息进行相同的函数(X)操作,用apply()函数,函数特点是它的参数是其他函数(X)
df2.loc[:,"整数"] = df2.loc[:,"销售业绩"].apply(round) #pd.apply允许用户传递一个函数并将其应用于Pandas系列的每个值
df2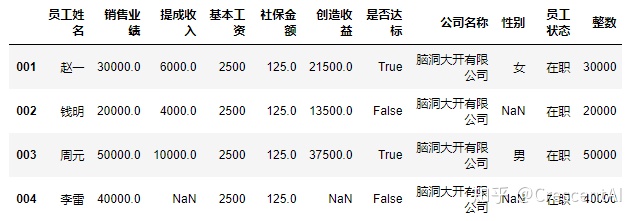
df2.drop("整数",axis=1,inplace=True)
df2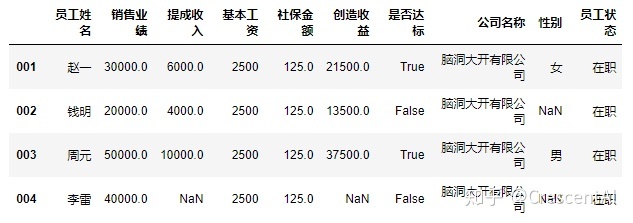
.loc 同时也可以用来扩展数据的行:
df2.loc["005"] = 233 #可以赋值一个标量
df2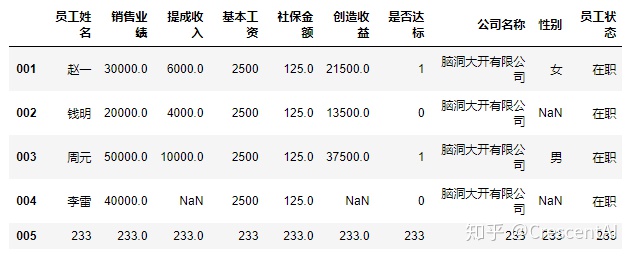
df2.drop("005",axis=0,inplace=True)
df2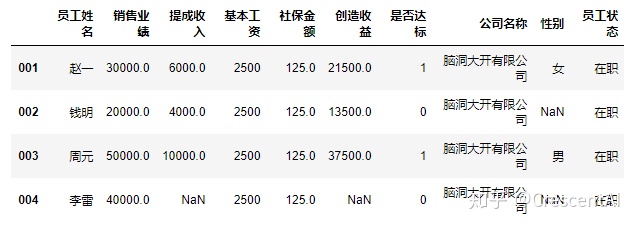
8) 将Series转换为DataFrame
s = df.mean()
s.name = 'to_DataFrame'
s
s.to_frame()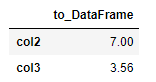
使用T符号可以转置
s.to_frame().T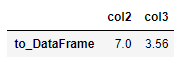
四、常用基本函数
df = pd.read_csv('pandas/joyful-pandas-master/data/table.csv')1) head和tail
df.head() # 默认显示前五条数据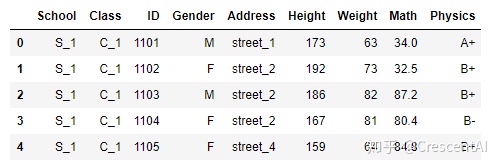
df.tail() # 默认显示后五条数据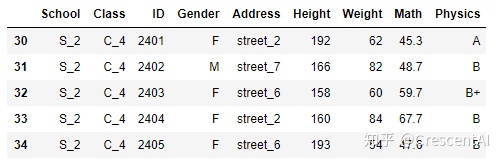
df.head(3) # 指定n参数显示多少条数据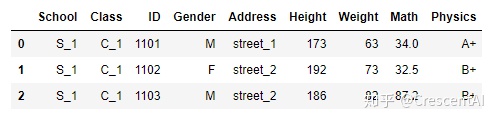
2) unique和nunique
df['Physics'].nunique() # 统计并显示有多少个唯一值7
df['Physics'].unique() # unqiue显示所有唯一值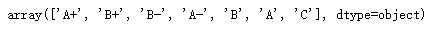
3) count和value_counts
df.isnull().mean()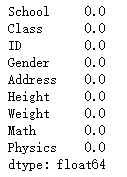
df['Physics'].count() # count返回非缺失值元素个数35
df['Physics'].value_counts() # value_counts返回每个元素有多少个
4) describe和info
df.info() # info函数返回有哪些列、有多少非缺失值、每列的类型
df.describe() # describe默认统计数值型数据的各个统计量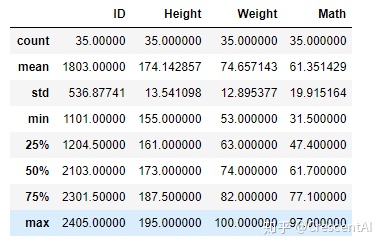
df.describe(percentiles=[.05, .25, .50, .75, .95]) # 可以自行选择分位数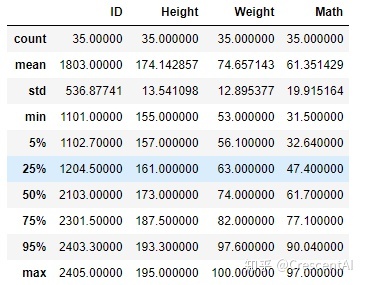
df['Physics'].describe() # 对于非数值型也可以用describe函数
5) idxmax和nlargest
df['Math'].idxmax() # idxmax函数返回最大值,在某些情况下特别适用,idxmin功能类似5
df['Math'].nlargest(3) # nlargest函数返回前几个大的元素值,nsmallest功能类似
6) clip和replace
clip和replace是两类替换函数
clip是对超过或者低于某些值的数进行截断
df['Math'].head()
df['Math'].clip(33,80).head()
df['Math'].mad()16.924244897959188
replace是对某些值进行替换
df['Address'].head()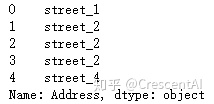
df['Address'].replace(['street_1', 'street_2'],['one', 'two']).head()
通过字典,可以直接在表中修改
df.replace({'Address':{'street_1':'one', 'street_2':'two'}}).head()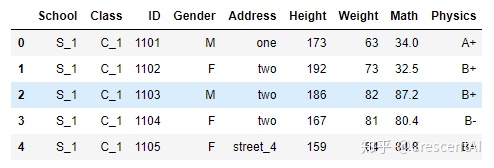
7) apply函数
apply是一个自由度很高的函数,对于Series,它可以迭代每一列的值操作:
df['Math'].apply(lambda x:str(x)+'!').head() # 可以使用lambda表达式,也可以使用函数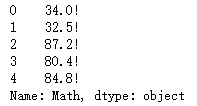
对于DataFrame,它可以迭代每一个列操作:
df.apply(lambda x:x.apply(lambda x:str(x)+'!')).head() # 这是一个稍显复杂的例子,有利于理解apply的功能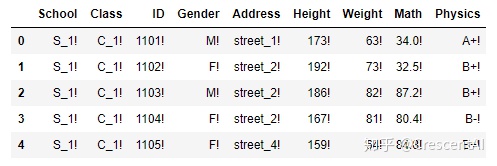
五、排序
1) 索引排序
df.set_index('Math').head()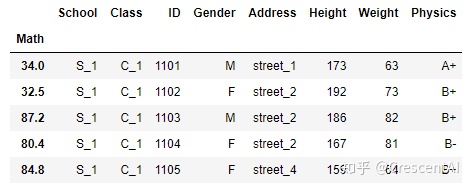
df.set_index('Math').sort_index().head() # 可以设置ascending参数,默认为升序,True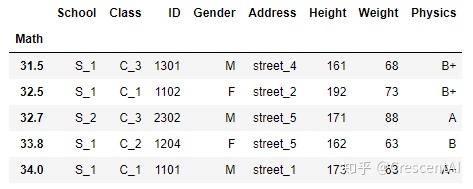
df.set_index('Math').sort_index(ascending=False).head()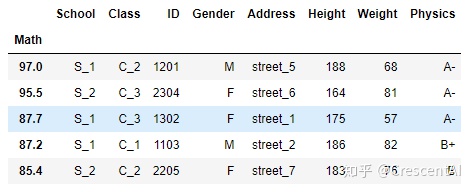
2) 值排序
df.sort_values(by = 'Class').head() # 按值进行升序排序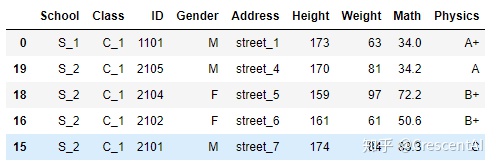
多个值排序,即先对第一层排,在第一层相同的情况下对第二层排序
df.sort_values(by=['Address','Height']).head()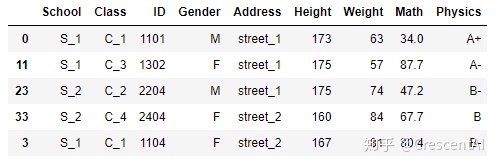
六、问题与练习
1. 问题
【问题一】 Series和DataFrame有哪些常见属性和方法?
【问题二】 value_counts会统计缺失值吗?
【问题三】 与idxmax和nlargest功能相反的是哪两组函数?
【问题四】 在常用函数一节中,由于一些函数的功能比较简单,因此没有列入,现在将它们列在下面,请分别说明它们的用途并尝试使用。
sum/mean/median/mad/min/max/abs/std/var/quantile/cummax/cumsum/cumprod
【问题五】 df.mean(axis=1)是什么意思?它与df.mean()的结果一样吗?第一问提到的函数也有axis参数吗?怎么使用?
2. 练习
【练习一】 现有一份关于美剧《权力的游戏》剧本的数据集,请解决以下问题:
(a)在所有的数据中,一共出现了多少人物?
(b)以单元格计数(即简单把一个单元格视作一句),谁说了最多的话?
(c)以单词计数,谁说了最多的单词?
df5 = pd.read_csv('pandas/joyful-pandas-master/data/Game_of_Thrones_Script.csv')
df5.head()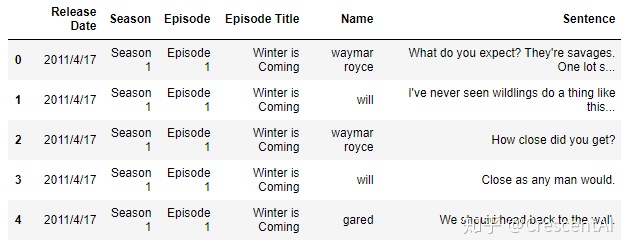
(a)在所有的数据中,一共出现了多少人物?
(b)以单元格计数(即简单把一个单元格视作一句),谁说了最多的话?
(c)以单词计数,谁说了最多的单词?
【练习二】现有一份关于科比的投篮数据集,请解决如下问题:
(a)哪种action_type和combined_shot_type的组合是最多的?
(b)在所有被记录的game_id中,遭遇到最多的opponent是一个支?
df6 = pd.read_csv('pandas/joyful-pandas-master/data/Kobe_data.csv',index_col='shot_id')
df6.head()
#index_col的作用是将某一列作为行索引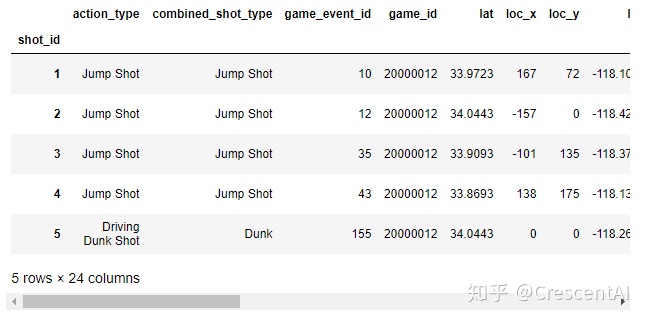
(a)哪种action_type和combined_shot_type的组合是最多的?
(b)在所有被记录的game_id中,遭遇到最多的opponent是一个支?
代码:
六、参考资料
1、Python for Data Analysis Wes McKinney著
2、Pandas Cookbook Theodore Petrou著
3、User Guide Pandas开发团队编写















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









