







sql优化
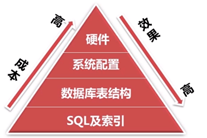
(1) SQL和索引优化
(2) 数据库表结构优化
(3) 系统配置优化
(4) 硬件优化
(1) select语句中尽量不使用select * from…, 使用具体的字段代替select name , age from …; * 代表所有的列, 不同的表, 列也不同, 需要解析列, 会查找所有的字段. 效率低。
(2) 尽量使用预编译的SQL;
因为预编译的SQL,发送给数据库时包含两个部分:sql语句和参数信息;
sql语句编译之后, 会将其缓存在数据库中, 下一次再次请求该语句时, 不会再执行编译的过程。
(3) where(where后不能跟聚合函数)和having:当使用where和having 都可以使用时,尽量使用where。

where:先过滤后分组(因为分组设计排序,所以排序数据少,效率高)
having:先分组后过滤
(1) 如果需要查询多张表,可以使用子查询,也可以使用多表查询时,理论上,尽量使用多表查询 —> 因为性能高.
因为子查询,对数据操作两次或多次,而多表查询则只操作一次,所以效率高
–> 不考虑笛卡尔积的情况下.
但是,如果表中的数据太多, 多表产生的笛卡尔积太大, 会影响多表查询的效率。
(2) 尽量不使用集合运算。
参与运算的集合越多,运行效率越低。UNION(去重并集) , UNION ALL(全并集) , INTERCEPT(交集) , MINUS(差集)
(3) 尽量不适用in操作符(针对Oracle)
ORACLE试图将in转换成多个表的连接,如果转换不成功则先执行IN里面的子查询,再查询外层的表记录,如果转换成功则直接采用多个表的连接方式查询。由此可见用IN的SQL至少多了一个转换的过程。在业务密集的SQL当中尽量不采用IN操作符,用EXISTS 方案代替。
(4) 强烈不建议使用not in操作符。
因为它不能使用表的索引,可以使用not exists来替代。
(5) 不要使用IS NULL或IS NOT NULL操作
判断字段是否为空一般是不会应用索引的,因为索引是不索引空值的,那么查找索引时去找字段为null的,肯定找不到。
用其它相同功能的操作运算代替,如:a is not null 改为 a>0 或a>’’等,或建表时不允许字段为空。
(6) LIKE模糊查询:’张%’走索引,而’%张’不走索引。
(7) 查询表顺序的影响
(8) 多表操作时,使用表的别名:可以避免解析的过程
(9) 不要在建立的索引的数据列上进行下列操作:
① 避免对索引字段进行计算操作、类型转换和使用函数
② 避免在索引字段上使用not,<>,!=
③ 避免在索引列上使用IS NULL和IS NOT NULL
④ 避免建立索引的列中使用空值
实现 Servlet 接口
因为是实现 Servlet 接口,所以我们需要实现接口里的方法。
下面我们也说明了 Servlet 的执行过程,也就是 Servlet 的生命周期。
//Servlet的生命周期:从Servlet被创建到Servlet被销毁的过程
//一次创建,到处服务
//一个Servlet只会有一个对象,服务所有的请求
/*
* 1.实例化(使用构造方法创建对象)
* 2.初始化 执行init方法
* 3.服务 执行service方法
* 4.销毁 执行destroy方法
*/
public class ServletDemo1 implements Servlet {
//public ServletDemo1(){}
//生命周期方法:当Servlet第一次被创建对象时执行该方法,该方法在整个生命周期中只执行一次
public void init(ServletConfig arg0) throws ServletException {
System.out.println("=======init=========");
}
//生命周期方法:对客户端响应的方法,该方法会被执行多次,每次请求该servlet都会执行该方法
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException {
System.out.println("hehe");
}
//生命周期方法:当Servlet被销毁时执行该方法
public void destroy() {
System.out.println("******destroy**********");
}
//当停止tomcat时也就销毁的servlet。
public ServletConfig getServletConfig() {
return null;
}
public String getServletInfo() {
return null;
}
}
类加载机制:
当程序主动使用某个类时,如果该类还未被加载到内存中,则JVM会通过加载、连接、初始化3个步骤来对该类进行初始化。如果没有意外,JVM将会连续完成3个步骤,所以有时也把这个3个步骤统称为类加载或类初始化。
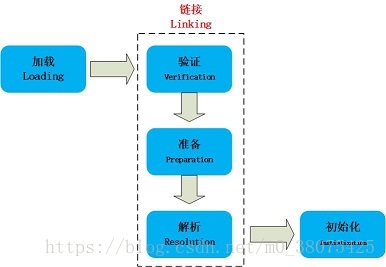
加载
加载指的是将类的class文件读入到内存,并为之创建一个java.lang.Class对象,也就是说,当程序中使用任何类时,系统都会为之建立一个java.lang.Class对象。
类的加载由类加载器完成,类加载器通常由JVM提供,这些类加载器也是前面所有程序运行的基础,JVM提供的这些类加载器通常被称为系统类加载器。除此之外,开发者可以通过继承ClassLoader基类来创建自己的类加载器。
通过使用不同的类加载器,可以从不同来源加载类的二进制数据,通常有如下几种来源。
从本地文件系统加载class文件,这是前面绝大部分示例程序的类加载方式。
从JAR包加载class文件,这种方式也是很常见的,前面介绍JDBC编程时用到的数据库驱动类就放在JAR文件中,JVM可以从JAR文件中直接加载该class文件。
通过网络加载class文件。
把一个Java源文件动态编译,并执行加载。
类加载器通常无须等到“首次使用”该类时才加载该类,Java虚拟机规范允许系统预先加载某些类。
1.JVM的类加载机制主要有如下3种。
全盘负责
所谓全盘负责,就是当一个类加载器负责加载某个Class时,该Class所依赖和引用其他Class也将由该类加载器负责载入,除非显示使用另外一个类加载器来载入。
双亲委派
所谓的双亲委派,则是先让父类加载器试图加载该Class,只有在父类加载器无法加载该类时才尝试从自己的类路径中加载该类。通俗的讲,就是某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父加载器,依次递归,如果父加载器可以完成类加载任务,就成功返回;只有父加载器无法完成此加载任务时,才自己去加载。
缓存机制
缓存机制将会保证所有加载过的Class都会被缓存,当程序中需要使用某个Class时,类加载器先从缓存区中搜寻该Class,只有当缓存区中不存在该Class对象时,系统才会读取该类对应的二进制数据,并将其转换成Class对象,存入缓冲区中。这就是为很么修改了Class后,必须重新启动JVM,程序所做的修改才会生效的原因。
2.这里说明一下双亲委派机制:

双亲委派机制,其工作原理的是,如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行,如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器,如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式,即每个儿子都很懒,每次有活就丢给父亲去干,直到父亲说这件事我也干不了时,儿子自己才想办法去完成。
双亲委派机制的优势:采用双亲委派模式的是好处是Java类随着它的类加载器一起具备了一种带有优先级的层次关系,通过这种层级关可以避免类的重复加载,当父亲已经加载了该类时,就没有必要子ClassLoader再加载一次。其次是考虑到安全因素,java核心api中定义类型不会被随意替换,假设通过网络传递一个名为java.lang.Integer的类,通过双亲委托模式传递到启动类加载器,而启动类加载器在核心Java API发现这个名字的类,发现该类已被加载,并不会重新加载网络传递的过来的java.lang.Integer,而直接返回已加载过的Integer.class,这样便可以防止核心API库被随意篡改。
JDK、JRE和JVM三者之间关系
很多程序员已经写了很长一段时间java了,依然不明白JDK,JRE,JVM的区别。今天个人总结一下它们三者的关系、区别。
JDK(Java Development Kit)是针对Java开发员的产品,是整个Java的核心,包括了Java运行环境JRE、Java工具和Java基础类库。
Java Runtime Environment(JRE)是运行JAVA程序所必须的环境的集合,包含JVM标准实现及Java核心类库。
JVM是Java Virtual Machine(Java虚拟机)的缩写,是整个java实现跨平台的最核心的部分,能够运行以Java语言写作的软件程序。
下面分别详细介绍
JDK
JDK是java开发工具包,在其安装目录下面有六个文件夹、一些描述文件、一个src压缩文件。bin、include、lib、 jre这四个文件夹起作用,demo、sample是一些例子。可以看出来JDK包含JRE,而JRE包含JVM。
bin:最主要的是编译器(javac.exe)
include:java和JVM交互用的头文件
lib:类库
jre:java运行环境(注意:这里的bin、lib文件夹和jre里的bin、lib是不同的)
总的来说JDK是用于java程序的开发,而jre则是只能运行class而没有编译的功能。
JDK是提供给Java开发人员使用的,其中包含了java的开发工具,也包括了JRE。所以安装了JDK,就不用在单独安装JRE了。 其中的开发工具包括编译工具(javac.exe)打包工具(jar.exe)等
JRE
JRE是指java运行环境。光有JVM还不能成class的执行,因为在解释class的时候JVM需要调用解释所需要的类库lib。在JDK的安装目录里你可以找到jre目录,里面有两个文件夹bin和lib,在这里可以认为bin里的就是jvm,lib中则是jvm工作所需要的类库,而jvm和 lib和起来就称为jre。所以,在你写完java程序编译成.class之后,你可以把这个.class文件和jre一起打包发给朋友,这样你的朋友就可以运行你写程序了。
包括Java虚拟机(JVM Java Virtual Machine)和Java程序所需的核心类库等,
如果想要运行一个开发好的Java程序,计算机中只需要安装JRE即可。
JVM
JVM就是我们常说的java虚拟机,它是整个java实现跨平台的最核心的部分,所有的java程序会首先被编译为.class的类文件,这种类文件可以在虚拟机上执行,也就是说class并不直接与机器的操作系统相对应,而是经过虚拟机间接与操作系统交互,由虚拟机将程序解释给本地系统执行。
可以理解为是一个虚拟出来的计算机,具备着计算机的基本运算方式,它主要负责将java程序生成的字节码文件解释成具体系统平台上的机器指令。让具体平台如window运行这些Java程序。
简单而言:使用JDK开发完成的java程序,交给JRE去运行。
三者之间关系
JDK 包含JRE,JRE包含JVM。
JVM:将字节码文件转成具体系统平台的机器指令。
JRE:JVM+Java语言的核心类库。
JDK:JRE+Java的开发工具。
我们开发的实际情况是:我们利用JDK(调用JAVA API)开发了属于我们自己的JAVA程序后,通过JDK中的编译程序(javac)将我们的文本java文件编译成JAVA字节码,在JRE上运行这些JAVA字节码,JVM解析这些字节码,映射到CPU指令集或OS的系统调用。
JSP九大内置对象
page(pageContext) --> request(response) --> session --> application(最大的域)
Out --> Exception --> Config(out了一个Exception,去看一下配置文件Config)
记忆:从前往后,从小往大,成对儿记忆。
a) page:page 对象代表JSP本身,只有在JSP页面内才是合法的,类似于Java编程中的 this 指针。
b) pageContext:通过它可以获取 JSP页面的out、request、reponse、session、application、config等对象
c) request:封装请求参数(业务参数,请求路径,IP,端口,请求头等)
d) response:设置contentType,响应方式等
e) session:服务器为每用户都创建一个session对象,保存用户信息
f) application:服务器启动时创建,关闭时销毁。类似session,但它的生命域和声明周期比session更长,所有客户共享这个内置的Application对象(在线人员统计)
g) out:给浏览器输出信息,并管理应用服务器上的输出缓冲区
h) exception:显示异常信息,只有在包含 isErrorPage=“true” 的页面才可以被使用,在一般的JSP页面中使用该对象将无法编译JSP文件。
i) config:获取服务器的配置信息。当一个Servlet 初始化时,容器把某些信息通过config对象传递给这个 Servlet,可以在web.xml中提供初始化参数。
对Java Serializable(序列化)的理解和总结
1、序列化是干什么的?
简单说就是为了保存在内存中的各种对象的状态(也就是实例变量,不是方法),并且可以把保存的对象状态再读出来。虽然你可以用你自己的各种各样的方法来保存object states,但是Java给你提供一种应该比你自己好的保存对象状态的机制,那就是序列化。
2、什么情况下需要序列化
a)当你想把的内存中的对象状态保存到一个文件中或者数据库中时候;
b)当你想用套接字在网络上传送对象的时候;
c)当你想通过RMI传输对象的时候;
3、当对一个对象实现序列化时,究竟发生了什么?
在没有序列化前,每个保存在堆(Heap)中的对象都有相应的状态(state),即实例变量(instance ariable)
**4、实现序列化(保存到一个文件)的步骤
** a)Make a FileOutputStream
java 代码
- **FileOutputStream fs =new FileOutputStream(*“foo.ser”);
b)Make a ObjectOutputStream
java 代码
- ObjectOutputStream os = new ObjectOutputStream(fs);
c)write the object
java 代码
-
os.writeObject(myObject1);
简而言之:序列化的作用就是为了不同jvm之间共享实例对象的一种解决方案.由java提供此机制,效率之高,是其他解决方案无法比拟的.自家的东西嘛.
\1. 什么是Java对象序列化
Java平台允许我们在内存中创建可复用的Java对象,但一般情况下,只有当JVM处于运行时,这些对象才可能存在,即,这些对象的生命周期不会比JVM的生命周期更长。但在现实应用中,就可能要求在JVM停止运行之后能够保存(持久化)指定的对象,并在将来重新读取被保存的对象。Java对象序列化就能够帮助我们实现该功能。
使用Java对象序列化,在保存对象时,会把其状态保存为一组字节,在未来,再将这些字节组装成对象。必须注意地是,对象序列化保存的是对象的"状态",即它的成员变量。由此可知,对象序列化不会关注类中的静态变量。
除了在持久化对象时会用到对象序列化之外,当使用RMI(远程方法调用),或在网络中传递对象时,都会用到对象序列化。Java序列化API为处理对象序列化提供了一个标准机制,该API简单易用,在本文的后续章节中将会陆续讲到。
\2. 简单示例
在Java中,只要一个类实现了java.io.Serializable接口,那么它就可以被序列化。此处将创建一个可序列化的类Person,本文中的所有示例将围绕着该类或其修改版。
http状态码
l status:
200 :OK;
302:重定向
304:表示所请求的文件没有被修改(那么浏览器就会从缓存中取之前的数据,从而节省带宽);
400:请求参数漏了
404文件访问不到(路径不对);
405:HTTP method GET is not supported by this URL,一般是get请求方式不对,换成post/put/delete等请求方式即可。
500服务器内部错误(路径对了,但是服务器内部的代码报错)
session和cookie区别与联系
l Cookie是网景公司发明,而session是sun公司定义的一个接口。Cookie是由http协议制定,并不是java独有,php或.net都可以使用cookie。
l cookie和session都是键值对的形式:cookie由一般由服务器创建,然后响应并保存到浏览器内存;session则是保存到服务器内存。
l cookie默认是会话级别(浏览器关闭就销毁),Tomcat中session默认生命周期是30分钟。
session和cookie的生命周期:
session:
创建
第一次访问jsp时,jsp会被转成servlet,在转换过程中,底层会自动调用 request.getSession()方法,去创建一个session,作为jsp九大内置对象之一和 该jsp绑定;
而访问servlet时,如果内部没有使用request.getSession()方法,是不会创建 session的;只有手动调用该方法,才会创建。
注:访问HTML,js,图片,css等静态资源是不会创建session的,因为访问 这些静态资源用不到session,跟session没有半毛钱关系,死板的创建session 和cookie 是浪费资源的。
销毁:
Tomcat默认30分钟后销毁,或者手动调用invalidate()方法,使之失效。
注:服务器关闭时,如果30分钟不到,session是不会销毁的,会被持久化到 本地磁盘,服务器启动会再次加载进内存。
cookie:(要存储中文要设置字符集)
创建:
session创建之后,服务器会自动创建一个cookie,把session的id存入cookie (Set-cookie:JSESSIONID=session的id),并响应给浏览器。当然,代码中可以手动new Cookie(“key”,”value”)并响应给浏览器。
销毁:
默认是浏览器关闭就销毁(cookie存储于浏览器内存,浏览器关闭,内存即释放,因而销毁),可以进行持久化,持久化之后即使浏览器关闭也不会销毁(存到硬盘上,再次打开浏览器又会被加载)。
bigDecimal
对于财务/double/float数据是怎么处理的?
使用BigDecimal:
BigDecimal的创建:使用字符串构造
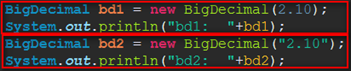
结果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lVfZRUbh-1646572211546)(C:\Users\Irving Chen\AppData\Roaming\Typora\typora-user-images\image-20211012134106440.png)]](https://img-blog.csdnimg.cn/a601c5a232a1492490b0462385317d63.png)
注1:使用构造时传入doubltaie类型数据是无效的,数据依然会损失。
l add, subtract, multiply, divide
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SXNOmXov-1646572211547)(C:\Users\Irving Chen\AppData\Roaming\Typora\typora-user-images\image-20211012134115592.png)]](https://img-blog.csdnimg.cn/4651c41a28f140f881391b325842c462.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBASXJ2aW5nLWNoYW4=,size_15,color_FFFFFF,t_70,g_se,x_16)
结果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Qt6KSGbD-1646572211547)(C:\Users\Irving Chen\AppData\Roaming\Typora\typora-user-images\image-20211012134131240.png)]](https://img-blog.csdnimg.cn/80fbd5b3f47d4f468e020e30f481f989.png)
注2:使用除法时,必须指定保留到小数点后几位,否则除不尽的时候,就会报“算数异常”。
第3个参数是指定小数点的取舍方式,有:四舍五入制,进位制,退位制,等等,可也以不写,它有自己的默认方式。
注3:有时间练一遍,没时间拉倒,无所谓,基本上把BigDecimal的构造和加减乘除的方法记住就够了。
ArrayList LinkedList
ArrayList :一般情况下,数组在内存中是连续存储的(这就是为啥创建数组时必须要指定长度,因为它要去内存中预留一块足够大的空间),通过指针去找到一个数组下标是非常快的;但是,福兮祸所伏,数组需要去维护下标,导致增删就比较慢。
LinkedList :链表数据存储是不连续的,比如:内存中,A空间指向B空间,B空间指向C空间,C空间指向D空间。我要查D空间的数据,每次都要从A空间顺着找过去,跳来跳去导致查询效率很低;但是,祸兮福所倚,链表不需要维护每个数据的地址,增删时,只需要修改该数据前后两个数据的关联地址即可。
同步和异步
ajax 同步和异步区别?
我们在使用 ajax 一般都会使用异步处理。
异步处理呢就是我们通过事件触发到 ajax,请求服务器,在这个期间无论服务器有没有响应,客户端的其他代码一样可以运行。
同步处理:我们通过实践触发 ajax,请求服务器,在这个期间等待服务器处理请求, 在这个期间客户端不能做任何处理。当 ajax 执行完毕才会继续执行其他代码。
同步:提交请求->等待服务器处理->处理完毕返回 这个期间客户端浏览器不能干任何事异步: 请求通过事件触发->服务器处理(这是浏览器仍然可以作其他事情)->处理完毕同步需要等待返回结果才能继续,异步不必等待,一般需要监听异步的结果
同步是在一条直线上的队列,异步不在一个队列上 各走各的
jquery 的 async:false,这个属性
默认是true:异步,false:同步。举例:
同步就是你叫我去吃饭,我听到了就和你去吃饭;如果没有听到,你就不停的叫,直到我告诉你听到了,才一起去吃饭。
异步就是你叫我,然后自己去吃饭,我得到消息后可能立即走,也可能等到忙完才去吃饭。
请求转发:
客户首先发送一个请求到服务器端,服务器端发现匹配的servlet,并指定它去执行,当这个servlet执行完之后,它要调用getRequestDispacther()方法,把请求转发给指定的student_list.jsp,整个流程都是在服务器端完成的,而且是在同一个请求里面完成的,因此servlet和jsp共享的是同一个request,在servlet里面放的所有东西,在student_list中都能取出来,因此,student_list能把结果getAttribute()出来,getAttribute()出来后执行完把结果返回给客户端。整个过程是一个请求,一个响应。
重定向:
客户发送一个请求到服务器,服务器匹配servlet,servlet处理完之后调用了sendRedirect()方法,立即向客户端返回这个响应,响应行告诉客户端你必须要再发送一个请求,去访问student_list.jsp,紧接着客户端收到这个请求后,立刻发出一个新的请求,去请求student_list.jsp,这里两个请求互不干扰,相互独立,在前面request里面setAttribute()的任何东西,在后面的request里面都获得不了。可见,在sendRedirect()里面是两个请求,两个响应。(服务器向浏览器发送一个302状态码以及一个location消息头,浏览器收到请求后会向再次根据重定向地址发出请求)
请求转发:request.getRequestDispatcher("/test.jsp").forword(request,response);
重定向:response.sendRedirect("/test.jsp");
区别:
1、请求次数:重定向是浏览器向服务器发送一个请求并收到响应后再次向一个新地址发出请求,转发是服务器收到请求后为了完成响应跳转到一个新的地址;重定向至少请求两次,转发请求一次;
2、地址栏不同:重定向地址栏会发生变化,转发地址栏不会发生变化;
3、是否共享数据:重定向两次请求不共享数据,转发一次请求共享数据(在request级别使用信息共享,使用重定向必然出错);
4、跳转限制:重定向可以跳转到任意URL,转发只能跳转本站点资源;
5、发生行为不同:重定向是客户端行为,转发是服务器端行为;
事务
ACID
4个特性:一致性,持久性,隔离性,原子性
1.一致性
不论事务成功还是失败,你的业务应该是一致的,数据不能被损坏。比如转账,你给张三转了1000,结果代码出错了,你扣了1000,但张三没有收到1000,这样数据/业务就损坏了,违反了一致性。应用系统从一个正确的状态到另一个正确的状态.而ACID就是说事务能够通过AID来保证这个C的过程.C是目的,AID都是手段. consistency
2.持久性
事务一旦完成,结果永久生效,无法回滚。durability
3.隔离性
多个事务同时处理一份数据时,事务之间应该相互隔离,否则就乱了(跟线程安全有点类似)。isolation
4.原子性
整个方法被捆绑成一个原子,不可拆分,要么一起成功,要么一起失败(同生共死)。 atomicity
并发事务引起的安全问题
1.脏读
A事务读取了B事务未提交的数据(一旦B事务回滚,可能会导致A事务读取的数据无效)。
2.不可重复读
一个事务方法中连续查询多次,却得到不同的结果(原因:并发事务在两次查询的中间对数据进行了修改)。
eg. 事务1:查询一条记录
-------------->事务2:更新事务1查询的记录
-------------->事务2:调用commit进行提交
事务1:再次查询上次的记录
***此时事务1对同一数据查询了两次,可得到的内容不同,称为不可重复读
3.虚读/幻读
一个事务方法中连续查询多次,却得到不同的结果(原因:并发事务在两次查询的瞬间对数据进行了增删)。
eg. 事务1:查询表中所有记录
-------------->事务2:插入一条记录
-------------->事务2:调用commit进行提交
事务1:再次查询表中所有记录
***此时事务1两次查询到的记录是不一样的,称为幻读
数据库4个隔离级别
安全性从低到高:唯一可穿
1.未提交读
安全级别最低,3个安全问题都解决不了。
2.已提交读(Oracle默认)
可以解决第一个问题(脏读)。
3.可重复读(mysql默认)
可以解决前两个问题(脏读和不可重复读)。
4.串行[又叫可序列化]
全部解决。
注意1:安全级别越来越高,那么效率就越来越低。比如串行,虽然把3个问题全解决了,但是有代价,它在执行A事务的时候,把整张表锁定,不论是读事物还是写事物,全都串行排队。
注意2:数据库的隔离级别可以修改,但一般采用默认,不过有人为了提高mysql的性能,将其隔离级别改为第二级(已提交读),由于间隙锁的优化策略的存在,解决了不可重复读和虚读/幻读。
事务的传播
事务的传播:一个事务方法调用另一个事务方法,必须指定事务如何传播(比如:一个service方法调用另一个service方法)。
注:事务的传播行为看的是被调用的方法,方法被调用的时候,就会触发事务的传播。
(1) REQUIRED(spring默认)
调用方有事务就用它的,没事务就用自己的
(2) REQUIRED_NEW
在事务方法调用过程中,把调用方的事务挂起,使用自己的事务。
(3) SUPPORTS
当前有事务就用,没事务就拉倒(不用)
(4) NOT_SUPPORTED
不支持事务,当前有事务就挂起
(5) NESTED
如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作。
(6) NEVER
以非事务方式运行,假设当前存在事务,则抛出异常
(7) REQUIRES_NEW
新建事务,假设当前存在事务。把当前事务挂起
面向对象
\3. 什么是面向对象?逻辑的封装
面向过程:强调的是各个环节的步骤顺序。
面向对象:面向对象是基于面向过程的,特点是封装,继承和多态。一个物体或者事物都可以看成一个对象。
举个例子:洗衣服。
面向过程:全人工操作----接水,加洗衣粉,揉搓,拧干等步骤;
面向对象:找个洗衣机(对象),把这个过程交给洗衣机处理。
成员变量和局部变量区别
l 在类中的位置:成员变量出现在类中方法外,局部变量出现在方法内部或者方法的形参上。
l 在内存中的位置:成员变量随对象的创建而出现在堆中,局部变量随方法的调用而出现在栈中。
l 生命周期:成员变量随着对象的创建而创建,随着对象的销毁而销毁;局部变量是随着方法的调用而产生,随着方法的调用的结束而销毁。
l 初始值:成员变量有默认初始值(eg:int类型的成员变量是0),局部变量没有默认值,必须手动赋值。
==和equals区别
l 基本数据类型:只能用==;
l 引用数据类型:都可以使用。equals是Object的方法,它底层调用的就是==,所以==和equals都是比较地址值,但是如果类中重写了equals方法,比较的就是具体的值了。eg1: String重写了(比较具体值),但是StringBuffer没有(比较地址值)。

eg2:自定义一个类Abc
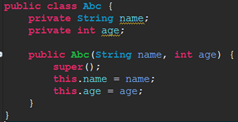

结果:false
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-txq6KfAO-1646572562868)(C:\Users\Irving Chen\AppData\Roaming\Typora\typora-user-images\image-20210923135539877.png)]](https://img-blog.csdnimg.cn/b7b0154c2bcd43499c467a25338fd7b3.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OlKHQ4MI-1646572562869)(C:\Users\Irving Chen\AppData\Roaming\Typora\typora-user-images\image-20210923135542643.png)]](https://img-blog.csdnimg.cn/6b115f8ebc474a3491b6cee8f6b665d6.png)
结果为:true
代码调试
Java后端代码打断点
- F5:跳入方法;
- F6:向下逐行调试;
- F7:跳出方法;
- F8:直接跳转到下一个断点;
前端代码打断点
debugger;
JS中attr和prop区别
一、attr和prop区别
attr 是从页面搜索获得元素值,所以页面必须明确定义元素才能获取值,相对来说较慢。
prop是从属性对象中取值,属性对象中有多少属性,就能获取多少值,不需要在页面中显示定义。
二、attr和prop怎么选择?
对于HTML元素本身就带有的固有属性,在处理时,使用prop方法。快速,准确。
对于HTML元素我们自己自定义的DOM属性,在处理时,使用attr方法。
三、例子
<input id="chke1" type="checkbox" />记住密码
<input id="chke2" type="checkbox" checked="checked" />记住密码
像checkbox,radio和select这样的元素,选中属性对应“checked”和“selected”,这些也属于固有属性,因此需要使用prop方法去操作才能获得正确的结果。
$("#chke1").prop("checked");// false
$("#chke2").prop("checked");// true
$("#chke1").attr("checked"); //undefined
$("#chke2").attr("checked"); //"checked"
回顾什么是Spring
Spring是一个开源框架,2003 年兴起的一个轻量级的Java 开发框架,作者:Rod Johnson 。
Spring是为了解决企业级应用开发的复杂性而创建的,简化开发。
Spring是如何简化Java开发的
为了降低Java开发的复杂性,Spring采用了以下4种关键策略:
1、基于POJO的轻量级和最小侵入性编程,所有东西都是bean;
2、通过IOC,依赖注入(DI)和面向接口实现松耦合;
3、基于切面(AOP)和惯例进行声明式编程;
4、通过切面和模版减少样式代码,RedisTemplate,xxxTemplate;
什么是SpringBoot
学过javaweb的同学就知道,开发一个web应用,从最初开始接触Servlet结合Tomcat, 跑出一个Hello Wolrld程序,是要经历特别多的步骤;后来就用了框架Struts,再后来是SpringMVC,到了现在的SpringBoot,过一两年又会有其他web框架出现;你们有经历过框架不断的演进,然后自己开发项目所有的技术也在不断的变化、改造吗?建议都可以去经历一遍;
言归正传,什么是SpringBoot呢,就是一个javaweb的开发框架,和SpringMVC类似,对比其他javaweb框架的好处,官方说是简化开发,约定大于配置, you can “just run”,能迅速的开发web应用,几行代码开发一个http接口。
所有的技术框架的发展似乎都遵循了一条主线规律:从一个复杂应用场景 衍生 一种规范框架,人们只需要进行各种配置而不需要自己去实现它,这时候强大的配置功能成了优点;发展到一定程度之后,人们根据实际生产应用情况,选取其中实用功能和设计精华,重构出一些轻量级的框架;之后为了提高开发效率,嫌弃原先的各类配置过于麻烦,于是开始提倡“约定大于配置”,进而衍生出一些一站式的解决方案。
是的这就是Java企业级应用->J2EE->spring->springboot的过程。
随着 Spring 不断的发展,涉及的领域越来越多,项目整合开发需要配合各种各样的文件,慢慢变得不那么易用简单,违背了最初的理念,甚至人称配置地狱。Spring Boot 正是在这样的一个背景下被抽象出来的开发框架,目的为了让大家更容易的使用 Spring 、更容易的集成各种常用的中间件、开源软件;
Spring Boot 基于 Spring 开发,Spirng Boot 本身并不提供 Spring 框架的核心特性以及扩展功能,只是用于快速、敏捷地开发新一代基于 Spring 框架的应用程序。也就是说,它并不是用来替代 Spring 的解决方案,而是和 Spring 框架紧密结合用于提升 Spring 开发者体验的工具。Spring Boot 以约定大于配置的核心思想,默认帮我们进行了很多设置,多数 Spring Boot 应用只需要很少的 Spring 配置。同时它集成了大量常用的第三方库配置(例如 Redis、MongoDB、Jpa、RabbitMQ、Quartz 等等),Spring Boot 应用中这些第三方库几乎可以零配置的开箱即用。
简单来说就是SpringBoot其实不是什么新的框架,它默认配置了很多框架的使用方式,就像maven整合了所有的jar包,spring boot整合了所有的框架 。
Spring Boot 出生名门,从一开始就站在一个比较高的起点,又经过这几年的发展,生态足够完善,Spring Boot 已经当之无愧成为 Java 领域最热门的技术。
Spring Boot的主要优点:
- 为所有Spring开发者更快的入门
- 开箱即用,提供各种默认配置来简化项目配置
- 内嵌式容器简化Web项目
- 没有冗余代码生成和XML配置的要求
真的很爽,我们快速去体验开发个接口的感觉吧!
pom.xml
父依赖
其中它主要是依赖一个父项目,主要是管理项目的资源过滤及插件!
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.2.5.RELEASE</version> <relativePath/> <!-- lookup parent from repository --></parent>
点进去,发现还有一个父依赖
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>2.2.5.RELEASE</version> <relativePath>../../spring-boot-dependencies</relativePath></parent>
这里才是真正管理SpringBoot应用里面所有依赖版本的地方,SpringBoot的版本控制中心;
以后我们导入依赖默认是不需要写版本;但是如果导入的包没有在依赖中管理着就需要手动配置版本了;
启动器 spring-boot-starter
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId></dependency>
springboot-boot-starter-xxx:就是spring-boot的场景启动器
spring-boot-starter-web:帮我们导入了web模块正常运行所依赖的组件;
SpringBoot将所有的功能场景都抽取出来,做成一个个的starter (启动器),只需要在项目中引入这些starter即可,所有相关的依赖都会导入进来 , 我们要用什么功能就导入什么样的场景启动器即可 ;我们未来也可以自己自定义 starter;
主启动类
分析完了 pom.xml 来看看这个启动类
默认的主启动类
//@SpringBootApplication 来标注一个主程序类//说明这是一个Spring Boot应用@SpringBootApplicationpublic class SpringbootApplication {
public static void main(String[] args) { //以为是启动了一个方法,没想到启动了一个服务 SpringApplication.run(SpringbootApplication.class, args); }
}
但是**一个简单的启动类并不简单!**我们来分析一下这些注解都干了什么
结论:
- SpringBoot在启动的时候从类路径下的META-INF/spring.factories中获取EnableAutoConfiguration指定的值
- 将这些值作为自动配置类导入容器 , 自动配置类就生效 , 帮我们进行自动配置工作;
- 整个J2EE的整体解决方案和自动配置都在springboot-autoconfigure的jar包中;
- 它会给容器中导入非常多的自动配置类 (xxxAutoConfiguration), 就是给容器中导入这个场景需要的所有组件 , 并配置好这些组件 ;
- 有了自动配置类 , 免去了我们手动编写配置注入功能组件等的工作;
SpringApplication.run分析
分析该方法主要分两部分,一部分是SpringApplication的实例化,二是run方法的执行;
SpringApplication
这个类主要做了以下四件事情:
1、推断应用的类型是普通的项目还是Web项目
2、查找并加载所有可用初始化器 , 设置到initializers属性中
3、找出所有的应用程序监听器,设置到listeners属性中
4、推断并设置main方法的定义类,找到运行的主类
这就是自动装配的原理!
精髓
1、SpringBoot启动会加载大量的自动配置类
2、我们看我们需要的功能有没有在SpringBoot默认写好的自动配置类当中;
3、我们再来看这个自动配置类中到底配置了哪些组件;(只要我们要用的组件存在在其中,我们就不需要再手动配置了)
4、给容器中自动配置类添加组件的时候,会从properties类中获取某些属性。我们只需要在配置文件中指定这些属性的值即可;
**xxxxAutoConfigurartion:自动配置类;**给容器中添加组件
xxxxProperties:封装配置文件中相关属性;
了解:@Conditional
了解完自动装配的原理后,我们来关注一个细节问题,自动配置类必须在一定的条件下才能生效;
@Conditional派生注解(Spring注解版原生的@Conditional作用)
作用:必须是@Conditional指定的条件成立,才给容器中添加组件,配置配里面的所有内容才生效;
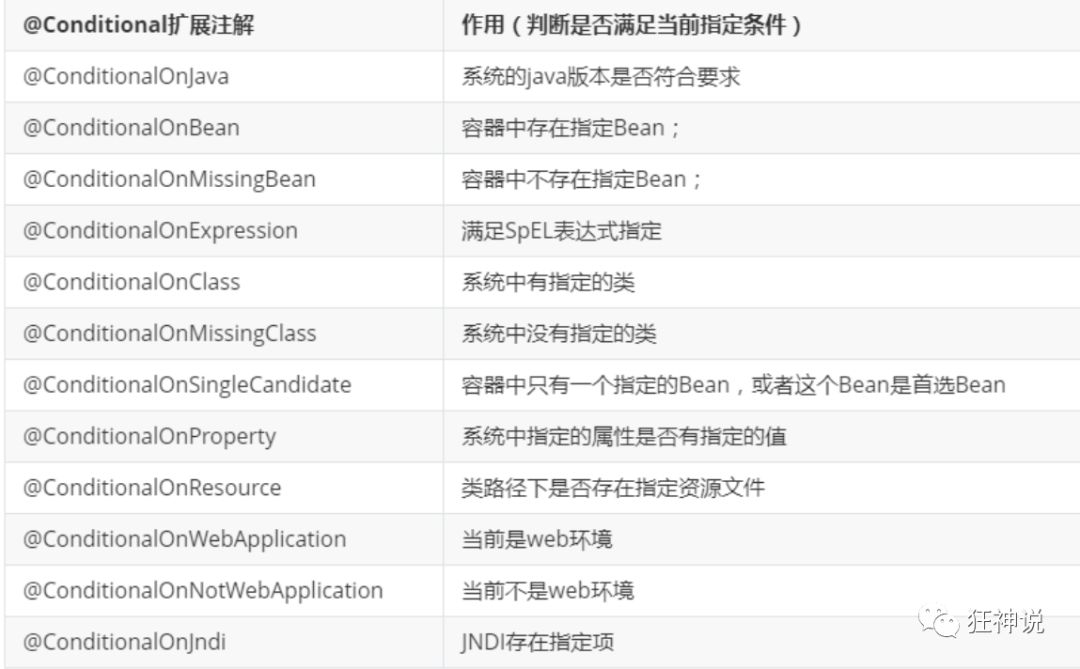
那么多的自动配置类,必须在一定的条件下才能生效;也就是说,我们加载了这么多的配置类,但不是所有的都生效了。
我们怎么知道哪些自动配置类生效?
我们可以通过启用 debug=true属性;来让控制台打印自动配置报告,这样我们就可以很方便的知道哪些自动配置类生效;
#开启springboot的调试类debug=true















 221
221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









