







腾讯云:通用文字识别之英文识别(本地图片)
下面的代码是识别本地图片的,在线url图片的可以参考官网文档,因为官网对于本地图片识别的案例代码介绍很少,文档写得对于新手来说不是很友好,在自己捣鼓好久之后才弄好,所以写个博客来记录一下。
需要替换的地方已经在代码中注明,有不清楚的地方可以评论,看到会回复。
from tencentcloud.common import credential
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException
from tencentcloud.ocr.v20181119 import ocr_client, models
import base64
try:
# 用你的ID和KEY替换掉SecretId、SecretKey
cred = credential.Credential("SecretId", "SecretKey")
httpProfile = HttpProfile()
httpProfile.endpoint = "ocr.tencentcloudapi.com"
# 使用TC3-HMAC-SHA256加密方法,不使用可能会报错
clientProfile = ClientProfile("TC3-HMAC-SHA256")
clientProfile.httpProfile = httpProfile
# 按就近的使用,所以我用的是ap-shanghai
client = ocr_client.OcrClient(cred, "ap-shanghai", clientProfile)
req = models.EnglishOCRRequest()
# 将本地文件转换为ImageBase64
with open("E:\\image\\7.jpg", 'rb') as f:
base64_data = base64.b64encode(f.read())
s = base64_data.decode()
params = '{"ImageBase64":"%s"}' % s
req.from_json_string(params)
resp = client.EnglishOCR(req)
resp = resp.to_json_string()
# 将官网文档里输出字符串格式的转换为字典,如果不需要可以直接print(resp)
resp = eval(resp)
# 下面都是从字典中取出识别出的文本内容,不需要其他的参数内容
resp_list = resp['TextDetections']
for resp in resp_list:
result = resp['DetectedText']
print(result)
except TencentCloudSDKException as err:
print(err)
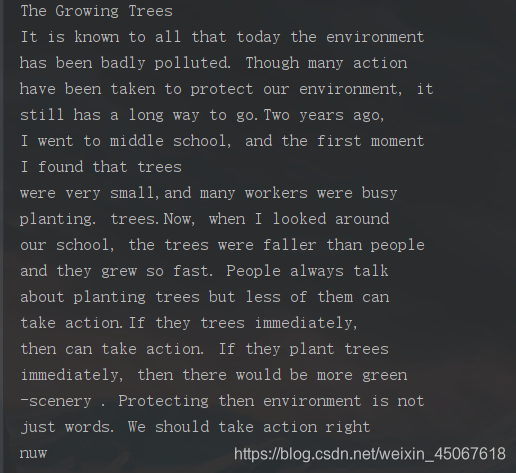
下面是识别好的内容格式,如果想要官网的那种json输出格式,就直接在resp = resp.to_json_string()之后打印输出resp就行,然后直接excet …,就OK了。














 2449
2449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









