







本学习笔记基于ElasticSearch 7.10版本,旧版本已经废弃的聚合功能暂时不做笔记,以后有涉及到再做补充。
参考官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations-metrics.html
指标聚合比较简单,大多数都是对查询返回的数据进行简单的数值处理。本章主要学习以下 9 个常用的指标聚合,如果想了解剩下的,可以参考官方文档。
1、Max
Max 聚合可以统计最大值,类似 MySQL 数据库中的 max 函数。
例如查询价格最高的书籍:
GET books/_search
{
"aggs": {
"max_price": {
"max": {
"field": "price"
}
}
}
}
查询结果的最下面,价格最高的书籍是269:
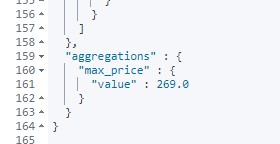
如果有某个文档缺少 price 字段,还可以使用 missing 来赋值,如下:
# 新增一个测试文档,price 字段留空
POST books/_doc
{
"name": "测试数据",
"publish" :"高等教育出版社",
"type" :"大学教材",
"author" :"大方哥",
"info": "高等教育出版社高等教育出版社高等教育出版社高等教育出版社高等教育出版社"
}
# 使用 missing 参数,设置 price 空字段值为 1000
GET books/_search
{
"aggs": {
"max_price": {
"max": {
"field": "price",
"missing": 1000
}
}
}
}
也可以通过脚本来查询最大值,可以先通过 doc['price'].size()!=0 去判断文档是否有对应的属性:
GET books/_search
{
"aggs": {
"max_price": {
"max": {
"script": {
"source": "if(doc['price'].size()!=0){doc.price.value}"
}
}
}
}
}
2、Min
统计最小值,用法和 Max 基本一致:
GET books/_search
{
"aggs": {
"min_price": {
"min": {
"field": "price",
"missing": 1000
}
}
}
}
GET books/_search
{
"aggs": {
"min_price": {
"min": {
"script": {
"source": "if(doc['price'].size()!=0){doc.price.value}"
}
}
}
}
}
3、Avg
统计平均值
GET books/_search
{
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
GET books/_search
{
"aggs": {
"avg_price": {
"avg": {
"script": {
"source": "if(doc['price'].size()!=0){doc.price.value}"
}
}
}
}
}
4、Sum
对字段求和
GET books/_search
{
"aggs": {
"sum_price": {
"sum": {
"field": "price"
}
}
}
}
GET books/_search
{
"aggs": {
"sum_price": {
"sum": {
"script": {
"source": "if(doc['price'].size()!=0){doc.price.value}"
}
}
}
}
}
5、Cardinality
Cardinality 聚合用于基数统计,类似于 MySQL 中的 distinct count(0),去重后再计数。
注意: ElasticSearch 中 text 字段类型是分析型,默认不允许进行聚合操作。如果有聚合操作的需求,可以考虑以下两种方式:
- 设置
text字段类型的 fielddata 属性为 true。 - 将字段类型或者字段的子域在设置成
keyword。
5.1、设置 text 字段类型的 fielddata 属性为 true
因为 books 索引已经存在,我们要先删除,再新建索引设置 fielddata,导入数据后再进行 Cardinality 统计:
DELETE books
PUT books
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"publish":{
"type": "text",
"analyzer": "ik_max_word",
"fielddata": true
},
"type":{
"type": "text",
"analyzer": "ik_max_word"
},
"author":{
"type": "keyword"
},
"info":{
"type": "text",
"analyzer": "ik_max_word"
},
"price":{
"type": "double"
}
}
}
}
到 bookdata.json 文件目录下,用 cmd 命令行工具,重新导入数据:
curl -XPOST "http://localhost:9200/books/_bulk?pretty" -H "content-type:application/json" --data-binary @bookdata.json
现在就可以使用 cardinality 查询出版社的总数量:
GET books/_search
{
"aggs": {
"publish_count": {
"cardinality": {
"field": "publish"
}
}
}
}

注意: 这种方式虽然可以进行聚合操作,但是无法满足精准聚合,因为 text 类型会进行分词。而且 fielddata 是动态创建到内存中,如果文档很多时,可能有动态创建慢,占内存等问题,所以推荐使用下面第二种方式。
有关 fielddata 属性介绍可以参考:ElasticSearch学习笔记七(映射参数)。
5.2、将字段类型或者字段的子域设置成 keyword
同样需要删除索引再新建,这次将 publish 字段子域设置成 keyword :
PUT books
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"publish":{
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"size": {
"type": "keyword"
}
}
},
"type":{
"type": "text",
"analyzer": "ik_max_word"
},
"author":{
"type": "keyword"
},
"info":{
"type": "text",
"analyzer": "ik_max_word"
},
"price":{
"type": "double"
}
}
}
}
再次使用 cardinality 查询出版社的总数量:
GET books/_search
{
"aggs": {
"publish_count": {
"cardinality": {
"field": "publish"
}
}
}
}
这次查询到的准确结果为 13 个:
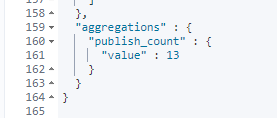
6、Stats
stats 表示基本统计聚合,可以同时返回 min、max、sum、count、avg 结果:
GET books/_search
{
"aggs": {
"stats_agg": {
"stats": {
"field": "price"
}
}
}
}
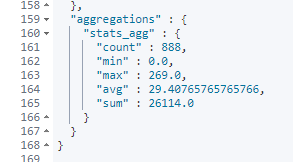
7、Extends Stats
Extends Stats 表示高级统计聚合,比 stats 聚合返回更多的内容:
GET books/_search
{
"aggs": {
"extended_stats_agg": {
"extended_stats": {
"field": "price"
}
}
}
}

8、Percentiles
Percentiles 是百分位数值统计,运用于统计学中:将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数。
文字解释看起来比较难理解,还是拿书籍价格举例,分别看一下 25%、50%、75%、100% 这四个百分位上的书籍价格:
GET books/_search
{
"aggs": {
"percentiles_agg": {
"percentiles": {
"field": "price",
"percents": [
1,
5,
10,
15,
25,
50,
75,
95,
100
]
}
}
}
}
可以看到,中位数 50% 的书籍价格是 28 元,也就是说有一半的书籍价格比 28 元低,另一半比 28 元高,对应的 25%、75%、100% 也是类似。

9、Value count
Value count 可以按照字段统计文档数量,该字段值为空 null 的文档会被丢弃:
GET books/_search
{
"aggs": {
"count": {
"value_count": {
"field": "price"
}
}
}
}
版权声明:
本文仅记录ElasticSearch学习心得,如有侵权请联系删除。
更多内容请访问原创作者:江南一点雨
















 627
627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









