







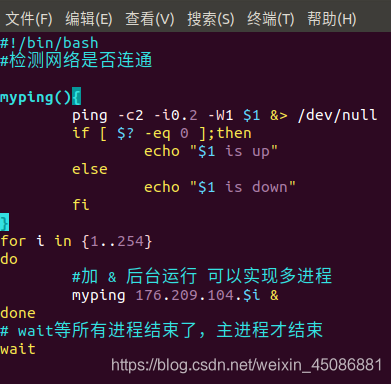
1,多线程批量执行脚本(利用后台执行)
2,正则表达式:(模糊匹配)
使用一些特征来描述数据
日志文件:根据IP匹配地区
sed语法格式:
sed [选项] '条件指令' 文件名
1),选项
p==print
d:delete
=:打印匹配行的行号
-n 取消默认的完整输出,只要需要的
-e 允许多项编辑
-i 修改文件内容 (相当于保存修改过的源文件,会对源文件造成影响)
-r 不需要转义
注意:& 符号在sed命令中代表上次匹配的结果
2),条件指令
a\ 在当前行后添加一行或多行。 (append)追加
c\ 用此符号后的新文本替换当前行中的文本。
i\ 在当前行之前插入文本。
d 删除行
h 把模式空间里的内容复制到暂存缓冲区
H 把模式空间里的内容追加到暂存缓冲区
g 把暂存缓冲区里的内容复制到模式空间,覆盖原有的内容
G 把暂存缓冲区的内容追加到模式空间里,追加在原有内容的后面
l 列出非打印字符
p 打印行
n 读入下一输入行,并从下一条命令而不是第一条命令开始对其的处理
q 结束或退出sed
r 从文件中读取输入行
! 对所选行以外的所有行应用命令
s 用一个字符串替换另一个 s/旧/新
g 在行内进行全局替换
w 将所选的行写入文件
x 交换暂存缓冲区与模式空间的内容
y 将字符替换为另一字符(不能对正则表达式使用y命令)
sed -n '3p' /etc/hosts # 打印文件的第三行
sed -n '3,9p' /var/log/a.log # 打印文件的第3到9行
sed 's/2009//g' /etc/a.txt # 将a.txt文件中所有的2009替换为空(变相删除)
sed '2a XYZ' /etc/a.txt # 在第2行后面添加一行XYZ
sed '2i XYZ' /etc/hosts # 在第2行前面添加一行XYZ
awk(数据过滤,逐行处理)
语法格式:awk [选项] '条件{指令}' 文件名
命令 | awk [选项] '条件{指令}'
awk内置变量:$1,$2,$3(第一列,第二列,第三列...)
df -h | awk '{print $4}' # 把硬盘的剩余空间打印出来(逐行处理) 查磁盘
free 查硬盘
free | awk '/内存/{print $7}' # 只取包含 内存 的行,打印第7列
uptime 电脑已经开机多长时间 几个人登录 1 5 15 分钟的 平均负载
















 25万+
25万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









