







目录
一、线程间的通讯机制
1、Queue消息队列
- 消息队列是在消息的传输过程中保存消息的容器,主要用于不同线程间任意类型数据的共享。
- 消息队列最经典的用法就是消费者和生成者之间通过消息管道来传递消息,消费者和生成者是不同的线程。生产者往管道中写消息,消费者从管道中读消息,且一次只允许一个线程访问管道。
1.1、常用接口
-
from queue import Queue q =Queue(maxsize=0) # 初始化,maxsize=0表示队列的消息个数不受限制;maxsize>0表示存放限制 q.get() # 提取消息,如果队列为空会阻塞程序,等待队列消息 q.get(timeout=1) # 阻塞程序,设置超时时间 q.put() # 发送消息,将消息放入队列
1.2、演示
- 使用生产者和消费者的案例进行演示。
-
from queue import Queue import threading import time def product(q): # 生产者 kind = ('猪肉','白菜','豆沙') for i in range(3): print(threading.current_thread().name,"生产者开始生产包子") time.sleep(1) q.put(kind[i%3]) # 放入包子 print(threading.current_thread().name,"生产者的包子做完了") def consumer(q): # 消费者 while True: print(threading.current_thread().name,"消费者准备吃包子") time.sleep(1) t=q.get() # 拿出包子 print("消费者吃了一个{}包子".format(t)) if __name__=='__main__': q=Queue(maxsize=1) # 启动两个生产者线程 threading.Thread(target=product,args=(q, )).start() threading.Thread(target=product,args=(q, )).start() # 启动一个消费者线程 threading.Thread(target=consumer,args=(q, )).start()
-
- 运行结果:

2、Event事件对象
- 事件对象主要用于通过事件通知机制实现线程的大规模并发。
- 事件对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在初始情况下,事件对象中的信号标志被设置为假。如果有线程等待一个事件对象,而这个事件对象的标志为假,那么这个线程将会被一直阻塞直到该标志为真。如果一个事件对象的信号标志被设置为真,它将唤醒所有等待该事件对象的线程。如果一个线程等待一个已经被设置为真的事件对象,那么它将忽略这个事件,继续执行。
- 应用场景:多个线程逐步开始运行时,由于某个条件未满足,则它们都会被阻塞。直到条件满足后,才全部继续执行。
2.1、常用接口
-
import threading # 使用多线程必要的模块 event=threading.Event() # 创建一个evnet对象 event.clear() # 重置代码中的event对象,使得所有该event事件都处于待命状态 event.wait() # 阻塞线程,等待event指令 event.set() # 发送event指令,使得所有设置该event事件的线程执行
2.2、演示
- 创建10个线程对象,使用event事件将其全部关联起来。先把它们全部阻塞,再同时运行。
-
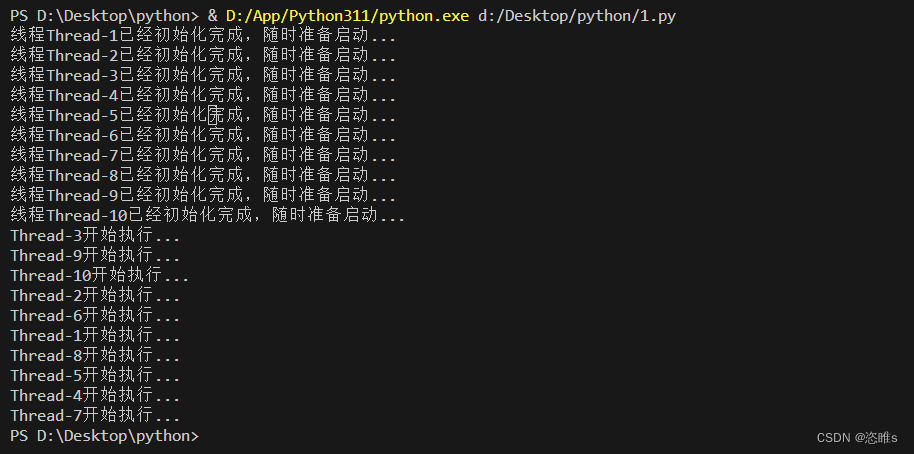
import threading,time # 自定义的线程类 class MyThread(threading.Thread): # 继承threading.Thread类 # 初始化 def __init__(self,event): super().__init__() # 调用父类的初始化方法,super()代表父类对象 self.event=event # 将传入的事件对象event绑定到当前线程实例上 # 运行 def run(self): print(f"线程{self.name}已经初始化完成,随时准备启动...") self.event.wait() # 阻塞线程,等待event触发 print(f"{self.name}开始执行...") if __name__=='__main__': event=threading.Event() threads=[] # 创建10个MyThread线程对象,并传入event。这样每个线程都与这个事件相关联 [threads.append(MyThread(event)) for i in range(1,11)] event.clear() # 使得所有该event事件都处于待命状态 [t.start() for t in threads] # 启动所有线程,由于事件未触发,线程都被锁定 time.sleep(5) event.set() # 使得所有设置该event事件的线程执行 [t.join for t in threads] # 等待所有线程结束后再继续执行主线程
-
- 运行结果:
- 多个线程可以绑定同一个事件,在事件触发时统一并发执行。
3、Condition条件对象
- 条件对象主要用于多个线程间轮流交替执行任务。
3.1、常用接口
-
import threading cond=threading.Condition() # 新建一个条件对象 self.cond.acquire() # 获取锁 self.cond.wait() # 线程阻塞,等待通知 self.cond.notify() # 唤醒其他wait状态的线程 self.cond.release() # 释放锁
3.2、演示
- 创建两个线程,轮流执行完成对话,如下图。

-
import threading # 新建一个条件对象 cond=threading.Condition() class thread1(threading.Thread): def __init__(self,cond,name): threading.Thread.__init__(self,name=name) self.cond=cond def run(self): self.cond.acquire() # 获取锁 print(self.name+":一支穿云箭") # 线程1说的第1句话 self.cond.notify() # 唤醒其他wait状态的线程(通知线程2说话) self.cond.wait() # 线程阻塞,等待通知 print(self.name+":山无楞,天地合,乃敢与君决") # 线程1说的第2句话 self.cond.notify() # 唤醒其他wait状态的线程(通知线程2说话) self.cond.wait() # 线程阻塞,等待通知 print(self.name+":紫薇") # 线程1说的第3句话 self.cond.notify() # 唤醒其他wait状态的线程(通知线程2说话) self.cond.wait() # 线程阻塞,等待通知 print(self.name+":是你") # 线程1说的第4句话 self.cond.notify() # 唤醒其他wait状态的线程(通知线程2说话) self.cond.wait() # 线程阻塞,等待通知 print(self.name+":有钱吗,借点?") # 线程1说的第5句话 self.cond.notify() # 唤醒其他wait状态的线程(通知线程2说话) self.cond.release() # 释放锁 class thread2(threading.Thread): def __init__(self,cond,name): threading.Thread.__init__(self,name=name) self.cond=cond def run(self): self.cond.acquire() # 获取锁 self.cond.wait() # 线程阻塞,等待通知 print(self.name+":千军万马来相见") # 线程2说的第1句话 self.cond.notify() # 唤醒其他wait状态的线程(通知线程2说话) self.cond.wait() # 线程阻塞,等待通知 print(self.name+":海可枯,石可烂,激情永不散") # 线程2说的第3句话 self.cond.notify() # 唤醒其他wait状态的线程(通知线程2说话) self.cond.wait() # 线程阻塞,等待通知 print(self.name+":尔康") # 线程2说的第3句话 self.cond.notify() # 唤醒其他wait状态的线程(通知线程2说话) self.cond.wait() # 线程阻塞,等待通知 print(self.name+":是我") # 线程2说的第4句话 self.cond.notify() # 唤醒其他wait状态的线程(通知线程2说话) self.cond.wait() # 线程阻塞,等待通知 print(self.name+":滚!") # 线程2说的第5句话 self.cond.release() if __name__=='__main__': thread1=thread1(cond,'线程1') thread2=thread2(cond,'线程2') # 虽然是线程1先说话,但是不能让它先启动。因为线程1先启动的话,发出notify指令,而线程2可能还未启动,导致notify指令无法接收。 thread2.start() # 线程2先执行 thread1.start()
- 运行结果:

二、线程中的消息隔离机制
1、消息隔离
- 假设有两个线程,线程A种的变量和线程B中的变量值不能共享,这就是消息隔离。
- 那变量名取不一样不就好啦?的确可以。但如果所有的线程都是由一个class实例化出来的对象呢?这样要给每个线程添加不同的变量就显得很麻烦了。
- 基于上述场景,python提供了threading.local()这个类,可以很方便的控制变量的隔离,即使是同一个变量,在不同的线程中,其值也是不能共享的。
2、演示
- 设置一个threading.local共享线程内全局变量,然后新建2个线程,分别设置这个threading.local的值,然后再分别打印这两个threading.local的值,确认是否每个线程打印出来的threading.local的值都是不同的。
-
import threading local_data=threading.local() # 定义线程内全局变量 local_data.name='local_data' # 初始名称(主线程) class MyThread(threading.Thread): def run(self): print("赋值前-子线程:",threading.current_thread(),local_data.__dict__) # local_data.__dict__:打印对象所有属性 # 在子线程中修改local_data.name的值 local_data.name=self.name print("赋值后-子线程:",threading.current_thread(),local_data.__dict__) if __name__=='__main__': print("开始前-主线程:",local_data.__dict__) # 启动两个线程 t1=MyThread() t1.start() t1.join() t2=MyThread() t2.start() t2.join() print("开始后-主线程:",local_data.__dict__)
-
- 运行结果:

- 主线程中的local_data被赋值,而子线程开始前的local_data并未赋值,故为空。
三、线程同步信号量
1、简介
- semaphore信号量是用于控制线程工作数量的一种锁。
- 我们知道,在访问文件时,一次只能有一个线程写,而可以有多个线程同时读。如果我们要控制同时读取文件的线程个数,就需要使用到同步信号量。
- 当信号量不为0时,其他线程可以获取该信号量执行任务。每增加一个线程执行任务,信号量就会减一;每减少一个线程执行任务,信号量加一。当信号量为0时,其他线程全部阻塞,直到有线程完成任务释放信号量。
2、演示
- 建立10个模拟爬取网站内容的线程,利用同步信号量控制每次只能由3个线程执行任务。
-
import threading,time # 模拟爬取网站内容的线程 class HtmlSpider(threading.Thread): def __init__(self,url,sem): super().__init__() self.url=url self.sem=sem def run(self): time.sleep(2) # 模拟网络等待 print("获取网页内容成功!") self.sem.release() # 释放信号量 # 模拟爬取网站链接的线程 class UrlProducer(threading.Thread): def __init__(self,sem): super().__init__() self.sem=sem def run(self): for i in range(20): self.sem.acquire() # 获取信号量 html_thread=HtmlSpider(f'https://www.baidu.com/{i}',self.sem) # 模拟20个网址,并爬取内容 html_thread.start() if __name__=='__main__': sem=threading.Semaphore(value=3) # 同步信号量 url_producer=UrlProducer(sem) # 创建获取链接的线程对象 url_producer.start() # 启动线程
-
- 运行结果:
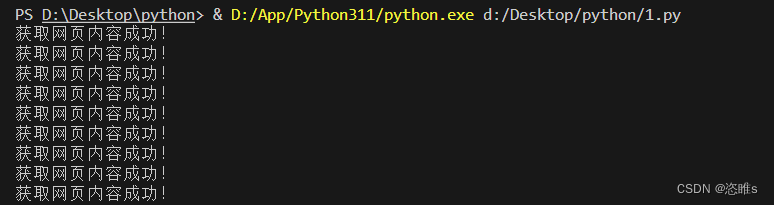
- 每三个一组完成任务。
四、线程池和进程池
1、线程池
- 线程池是一种多线程处理的形式。线程池维护着多个线程,等待着管理者分配可并发执行的任务,这些任务会被分配给空闲的线程。这避免了在处理短时间任务时创建与销毁线程的代价,让创建好的线程得到重复利用。线程池不仅能够保证内核的充分利用,还能防止过分调度。
- 不使用线程池:
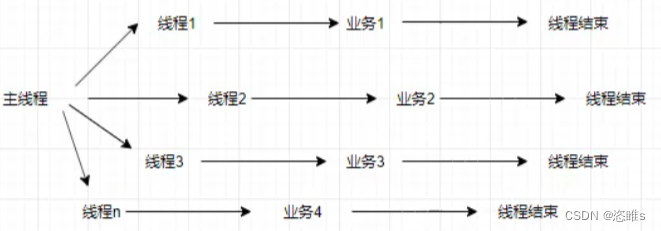
- 每个线程在创建并且执行完任务后就会被销毁。
- 使用线程池:

- 线程池中的线程会一直保留,直到程序结束。
1.1、线程池模块
-
from concurrent.futures import ThreadPoolExecutor # 线程池模块 executor = ThreadPoolExecutor(max_workers=3) # 创建线程池对象,max_worker为最大线程数 task1=executor.submit() # 提交需要线程完成的任务 - 线程池模块的特性:
- 主线程可以获取某一个线程或任务的状态,以及返回值。
- 当一个线程完成的时候,主线程能够立即知道。
- 让多线程和多进程的编码接口一致。
1.2、演示
- 创建一个线程池,其中包含3个线程,并为该线程池分配4个任务。
-
from concurrent.futures import ThreadPoolExecutor import time # 创建一个新的线程池对象,并且指定线程池中最大的线程数为3 executor = ThreadPoolExecutor(max_workers=3) def get_html(times): time.sleep(times) print(f'获取网页信息{times}完毕') return times # 通过submit方法提交执行的函数到线程池中,submit函数会立刻返回,不阻塞主线程 # 只要线程池中有可用线程,就会自动分配线程去完成对应的任务 task1=executor.submit(get_html,1) task2=executor.submit(get_html,2) task3=executor.submit(get_html,3) task4=executor.submit(get_html,2) # 多余的任务需要等待线程池中有空闲的线程
-
- 运行结果:

1.3、基本方法
1.3.1、done、cancel、result
- done():检查任务是否完成,并返回结果。但并不知道线程什么时候完成的。
- cancel():取消任务的执行,该任务没有放入线程池中才能取消。
- result():拿到任务的执行结果,该方法是一个阻塞方法。
- 演示
-
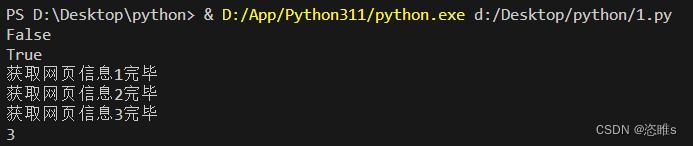
from concurrent.futures import ThreadPoolExecutor import time # 创建一个新的线程池对象,并且指定线程池中最大的线程数为3 executor = ThreadPoolExecutor(max_workers=3) def get_html(times): time.sleep(times) print(f'获取网页信息{times}完毕') return times # 通过submit方法提交执行的函数到线程池中,submit函数会立刻返回,不阻塞主线程 # 只要线程池中有可用线程,就会自动分配线程去完成对应的任务 task1=executor.submit(get_html,1) task2=executor.submit(get_html,2) task3=executor.submit(get_html,3) task4=executor.submit(get_html,2) # 多余的任务需要等待线程池中有空闲的线程 print(task1.done()) # 检查任务是否完成,并返回结果 print(task4.cancel()) # 取消任务的执行,该任务没有放入线程池中才能取消 print(task3.result()) # 拿到任务的执行结果,该方法是一个阻塞方法 - 运行结果:
-
1.3.2、as_completed
- as_completed用来检查任务是否完成,并根据任务完成的时间返回结果。
- 演示
-
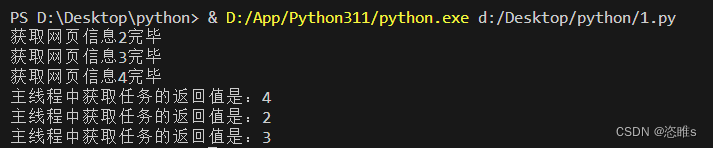
from concurrent.futures import ThreadPoolExecutor,as_completed import time # 创建一个新的线程池对象,并且指定线程池中最大的线程数为3 executor = ThreadPoolExecutor(max_workers=3) def get_html(times): time.sleep(times) print(f'获取网页信息{times}完毕') return times urls=[4,2,3] # 通过urls列表模拟要抓取的url # 通过列表推导式改造多线程任务 all_task=[executor.submit(get_html,url) for url in urls] # 按照任务完成顺序返回结果 for item in as_completed(all_task): # as_completed是一个生成器,在任务没有完成之前是阻塞的 data=item.result() print(f"主线程中获取任务的返回值是:{data}") - 运行结果:
-

1.3.3、map
- map和as_completed都可以拿到线程执行的结果,但是map也只是按照输入顺序拿到结果,而as_completed是根据任务结束顺序拿到结果。
- 演示
-
from concurrent.futures import ThreadPoolExecutor import time # 创建一个新的线程池对象,并且指定线程池中最大的线程数为3 executor = ThreadPoolExecutor(max_workers=3) def get_html(times): time.sleep(times) print(f'获取网页信息{times}完毕') return times urls=[4,2,3] # 通过urls列表模拟要抓取的url # map是一个生成器,不需要submit,直接将任务分配给线程池 for data in executor.map(get_html,urls): print(f"主线程中获取任务的返回值是:{data}") - 运行结果:
-
1.3.4、wait
- wait可以阻塞主线程,直到满足指定的条件。 return_when指定了需要满足的条件。
- 演示
-
from concurrent.futures import ThreadPoolExecutor,wait,ALL_COMPLETED import time # 创建一个新的线程池对象,并且指定线程池中最大的线程数为3 executor = ThreadPoolExecutor(max_workers=3) def get_html(times): time.sleep(times) print(f'获取网页信息{times}完毕') return times urls=[4,2,3] # 通过urls列表模拟要抓取的url all_task=[executor.submit(get_html,url) for url in urls] # 任务列表 wait(all_task,return_when=ALL_COMPLETED) # 让主线程阻塞,ALL_COMPLETED直到线程池中的所有线程任务执行完毕 print('代码执行完毕') - 运行结果:
-

2、进程池
- 与线程池类似,进程池是一种多进程处理的形式。进程池维护着多个进程,等待着管理者分配可并发执行的任务,这些任务会被分配给空闲的进程。
2.1、进程池模块
- 可使用的进程池模块有两种,如下所示。
-
# 使用concurrent futures模块提供的ProcessPoolExecutor来实现进程池 from concurrent.futures import ProcessPoolExecutor # 使用方法与线程池的完全一致 # 使用Pool类来实现进程池 from multiprocessing multiprocessing.Pool() - 下面讲解使用Pool类来实现进程池。
2.2、演示
- 单个进程执行
-
import multiprocessing import time def get_html(n): time.sleep(n) print(f"子进程{n}获取内容成功") return n if __name__=='__main__': pool=multiprocessing.Pool(multiprocessing.cpu_count()) # 设置进程池,进程数量是电脑cpu的核心数 result=pool.apply_async(get_html,args=(3,)) # 异步方式调用 pool.close() # 这个方法必须在join前调用 pool.join() # 子进程未执行完前,会阻塞主进程代码 print(result.get()) # 拿到子进程执行的结果 print("end") - 运行结果:
-
- 【注】进程数量最好与电脑CPU的核心数相同。
- join前必须调用close方法。
- 多个进程执行
-
import multiprocessing import time def get_html(n): time.sleep(n) print(f"子进程{n}获取内容成功") return n if __name__=='__main__': pool=multiprocessing.Pool(multiprocessing.cpu_count()) # 设置进程池,进程数量是电脑cpu的核心数 for result in pool.imap(get_html,[4,2,3]): print(f"{result}休眠执行成功!") - 运行结果:
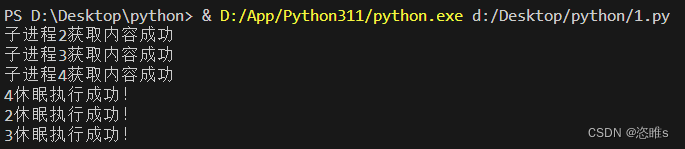
- 返回的结果是按顺序输出的。
-

















 6206
6206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











