








- 【参考文献】Zhao H, Li Z, Wei H, et al. SeqFuzzer: An industrial protocol fuzzing framework from a deep learning perspective[C]//2019 12th IEEE Conference on software testing, validation and verification (ICST). IEEE, 2019: 59-67.
- 【注】本文仅为作者个人学习笔记,如有冒犯,请联系作者删除。
目录
1、长短期记忆网络 (Long Short-Term Memory Network)
2、序列到序列网络模型 (Sequence-to-Sequence Network Model)
摘要
- 本文提出了一个名为SeqFuzzer的模糊测试框架,它可以自动从通信流量中学习协议框架结构,并生成虚假但可信的消息作为测试用例。
- 为了验证其可用性,本文首次将SeqFuzzer应用于EtherCAT协议,并成功检测到几个安全漏洞。
一、介绍
- 研究人员已经开发出各种模糊测试工具来揭示网络协议或工业设备中的安全漏洞。如:
- Wang T, Xiong Q, Gao H, et al. Design and implementation of fuzzing technology for OPC protocol[C]//2013 Ninth International Conference on Intelligent Information Hiding and Multimedia Signal Processing. IEEE, 2013: 424-428.
- Voyiatzis A G, Katsigiannis K, Koubias S. A modbus/tcp fuzzer for testing internetworked industrial systems[C]//2015 IEEE 20th conference on emerging technologies & factory automation (ETFA). IEEE, 2015: 1-6.
- Antrobus R, Frey S, Green B, et al. Simaticscan: Towards a specialised vulnerability scanner for industrial control systems[C]//4th International Symposium for ICS & SCADA Cyber Security Research 2016 4. 2016: 11-18.
- Zhang D, Wang J, Zhang H. Peach improvement on profinet-DCP for industrial control system vulnerability detection[C]//2015 2nd International Conference on Electrical, Computer Engineering and Electronics. Atlantis Press, 2015: 1622-1627.
- 然而,这些方法都存在一些局限性。一方面,这些模糊测试工具是针对特定协议开发的。另一方面,这些工具通常需要对目标协议的格式或框架有一定的了解,这对于私有协议来说是很困难的。如果协议是有状态的,就更加困难了。
- 为了跟踪服务器的内部状态,需要有状态网络协议,并且可以将其建模为有限状态机,其中整个通信过程由一系列状态转换组成。网络通信过程中,每种状态下的协议消息必须符合预定的格式。
- 故本文提出了一种通用的工业网络协议模糊测试方法,该方法能够自动识别协议格式,并且可以处理有状态的协议。本文的贡献如下:
- 提出了一种基于seq2seq (序列到序列网络)的模糊测试方法,可用于学习协议的格式和状态转换关系,并使用LSTM作为seq2seq的编码器和解码器。
- 提出了一个通用的工业网络协议模糊测试框架SeqFuzzer,它是独立于协议的。并且使用SeqFuzzer对以太网控制协议(EtherCAT)进行测试实验。
- 本文首次尝试将模糊测试应用于EtherCAT。EtherCAT是一种基于以太网的实时有状态工业协议,因其高速度和高效率而闻名。
二、预备知识
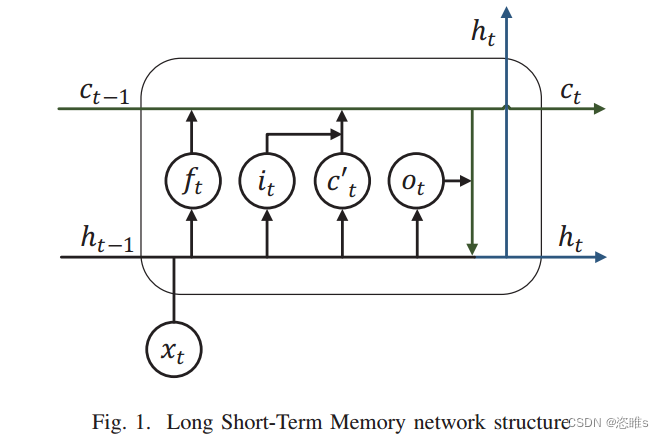
1、长短期记忆网络 (Long Short-Term Memory Network)
- 循环神经网络 (RNN)是一种用于处理序列数据的神经网络类型。它对序列中的每个元素执行相同的操作,并在每个时间步上有相同的权重参数。因此,在学习长序列时,可能会导致梯度消失或梯度爆炸的问题。
- 长短期记忆网络 (LSTM)是一种特殊的RNN,可以避免长期依赖的问题。其结构如图1所示。除了原始的隐藏单元
外,LSTM还有以下几个结构:
- 一个细胞状态
和三个控制门,分别是遗忘门
、输入门
和输出门
。
- 因此,每个LSTM单元具有不同的权重参数,且隐藏单元对下一个单元的影响是可控的。
- 一个细胞状态
- 例如,输入一个长序列 x: < x0, x1, ..., xt, ..., xn > 到LSTMs 中。在 t 时刻,
和上一个隐藏单元的输出
确定对前一个
的遗忘程度。
根据
- 与其他神经网络模型相比,细胞状态和门控制的机制使得LSTM能够更好地学习长序列关系。因此本文利用LSTM来学习和预测复杂网络协议的精确时序。
2、序列到序列网络模型 (Sequence-to-Sequence Network Model)
- Seq2seq是一种编码器 - 解码器网络模型结构。Seq2seq的输入和输出可以是不同长度的序列。编码器模型学习输入语句 x: < x0, x1, ..., xn > 的信息,并输出包含输入语句信息的潜在向量C。解码器模型通过学习向量C来预测输出语句 y: < y0, y1, ..., yn >。
- 对于编码器和解码器模型,可以使用RNN、LSTM和其他神经网络模型。输入和输出数据可以是图像、声音、视频等形式。本文使用LSTM作为seq2seq的编码器和解码器,以学习有状态协议的语法。
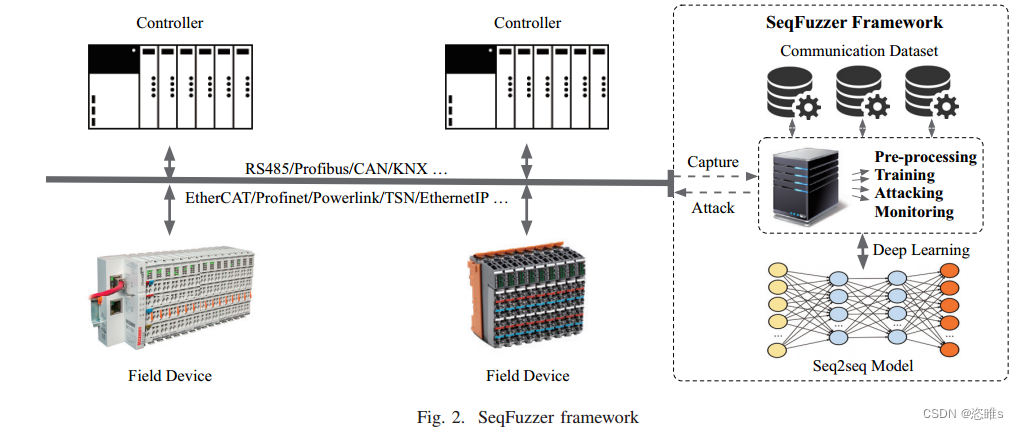
三、SeqFuzzer框架
- 本文提出了SeqFuzzer框架,如图2所示。
- SeqFuzzer的工作流程如下:
- 捕获真实工业场景中的网络流量,并对捕获的数据进行预处理。
- 构造和训练Seq2seq模型。
- 使用训练好的Seq2seq模型生成测试用例。
- 执行测试,并监控测试过程。
1、训练数据捕获和预处理
- 本工作捕获了真实的协议消息作为训练数据。在捕获了足够多的真实协议消息之后,会对其进行两次预处理操作。
- 特征数据转换
- 通过捕获工具,可以获得一个协议消息文件,其中每个序列代表一个协议消息。
- 将数字消息(一般为十六进制)转换为十进制序列,得到包含真实协议消息的十进制文件。
- 添加特殊字符
- 在数据通信中,消息长度是不同的。在使用十进制序列训练seq2seq模型之前,需要添加一些特殊字符让每个序列长度相等,以便进行标准化训练。
- 本文使用PAD(填充)来填充短的十进制序列,STA(开始)作为序列的起始标志,END(结束)作为序列的结束标志。
- 特征数据转换
2、Seq2seq模型构建和训练
- Seq2seq模型构建
- 假设S(协议消息)表示十进制序列,我们的目标是获得符合有状态协议转换关系的下一个序列。
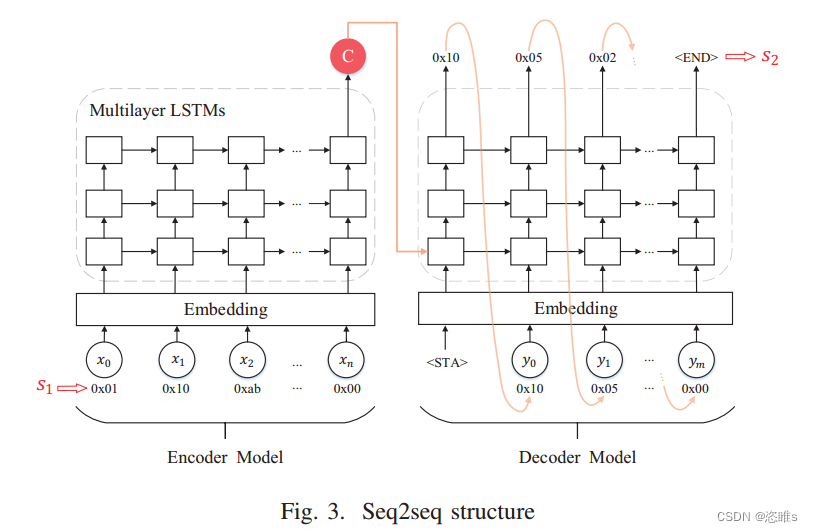
- Seq2seq模型中应用了一个三层LSTM,其中LSTM编码器模型学习协议消息的语法,LSTM解码器模型预测相应的协议序列,并输出虚假但有效的协议数据和语法结构。
- seq2seq网络结构如图3所示。它包括输入层、嵌入层、多层LSTM和输出层。输入和输出都是序列,不要求长度相等。
- 数据预处理后,每条消息被转换成了十进制特征序列,如“[1, 15, 242, 0, ...]”,在输入到LSTM之前由嵌入层转换成向量。
- 使用嵌入层处理的特征序列
作为LSTM编码器模型第一层的输入数据。LSTM的每个单元
都有两个输入,
和
,它们包含了之前协议消息的信息。
- 其中,
为非线性激活函数,如tanh、sigmoid等,
- 当LSTM层=1时,
。第一层的输出作为第二层的输入,用于传递有状态协议的状态转换关系。最终只保留最后一个神经元的输出,即潜在向量
,它表示输入协议序列X的所有状态和结构信息。
- LSTM解码器模型将对潜在向量C进行解码,并预测与有状态协议的特征相匹配的下一条消息
。
- 如图3所示。有状态协议特征消息
作为LSTM编码器模型的输入,得到潜在向量C。在LSTM解码器模型中,通过对C解码,得到
,
也作为下一阶段的输入。再得到
,以此类推,最终得到
。
就是seq2seq模型根据
预测的下一个序列。
- Seq2seq模型训练
- 输入的数据分为三部分:训练集、验证集和测试集。模型采用了Adam梯度优化算法——一种有效的随机优化算法。在训练和验证阶段,使用N-gram作为判断生成数据与真实数据相似度的标准。生成的数据与真实数据共享的N-gram越多,表示生成的数据越好。
- 训练、验证和测试阶段的参数是共享的,而训练和验证阶段旨在学习理想的参数。为了有效地训练模型,我们在训练和验证阶段使用不同的LSTM解码器模型。
- 在训练阶段,真实序列
作为LSTM编码器模型的输入,使其学习序列语法。LSTM解码器模型使用下一个真实数据
- 验证阶段可以防止过拟合,使模型更加健壮。训练阶段得到的参数会用于测试阶段。测试阶段会对解码器预测的结果进行评估。
- 训练开始前随机设置seq2seq模型训练的参数。研究人员发现通过预训练设置参数比随机初始化对深度学习网络模型更好,可以显著稳定训练过程。
3、测试用例生成
- 序列X输入到LSTM编码器模型,LSTM解码器输出预测结果,也就是虚假但有效的测试消息。
四、实验
- 本文通过对EtherCAT协议进行实验来验证方法的有效性。
1、EtherCAT实时工业以太网协议
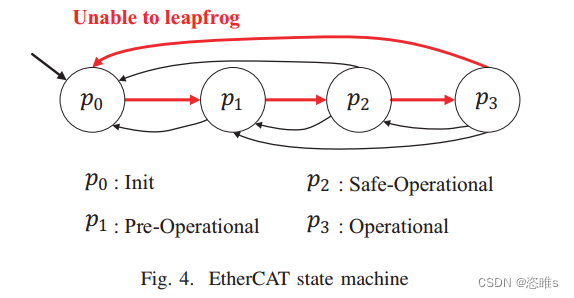
- EtherCAT协议采用主从结构,根据主设备的实现在特定的环路中发送数据。EtherCAT是有状态协议,包含4中状态:Init、Pre-Operational、Safe-Operational和Operational。它的操作必须遵循Inil -> Pre-Operational -> Safe-Operational -> Operational的顺序。状态之间的转换关系如图4。
2、EtherCAT数据捕获
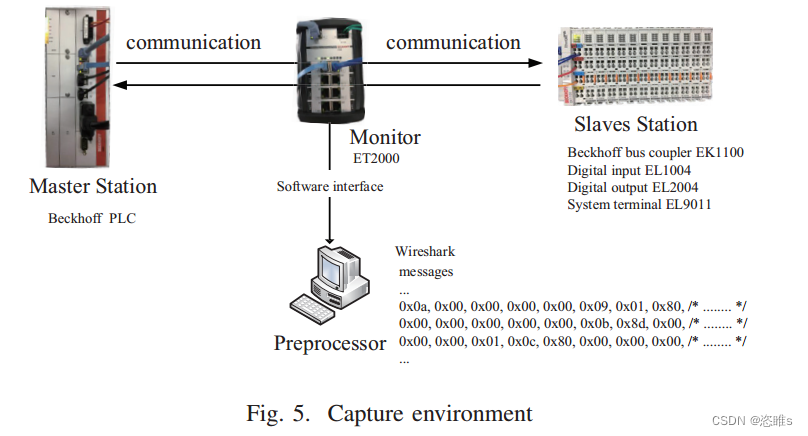
- 在本实验中,控制器是一台Beckhoff PLC,现场设备包括一台Beckhoff总线耦合器EK1100、数字输入EL1004、数字输出EL2004和系统端子EL9011。捕获工具包括Beckhoff Listener ET2000和终端捕获软件Wireshark。ET2000是一种工业以太网多通道监听器,具有一个软件界面,可以通过Wireshark软件在终端设备上显示捕获的数据包。ET2000可以支持所有实时以太网标准,如EtherCAT、Profinet等。此外,这些工具对实际的工业通信环境几乎没有影响,使它们成为捕获网络协议消息的良好选择。
- 捕获环境如图5所示。ET2000连接在主站和从站之间。PC上的Wireshark软件连接到ET2000接口,并显示监视ET2000捕获的数据。使用Wireshark,我们获得一个十六进制数组文件,其中每个数组代表一条消息。我们使用ET2000捕获数百万条协议消息,并在Wireshark上显示它们。
3、数据预处理
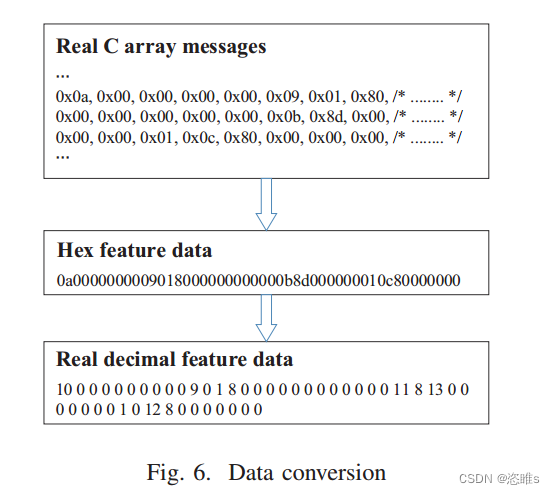
- 在Wireshark上,协议消息被导出为一个十六进制的C数组文件,然后将其处理成十六进制的特征序列。接下来,将这些数据转换为十进制。例如,0x00 → 0、0xff → 255。数据的转换如图6所示。
-
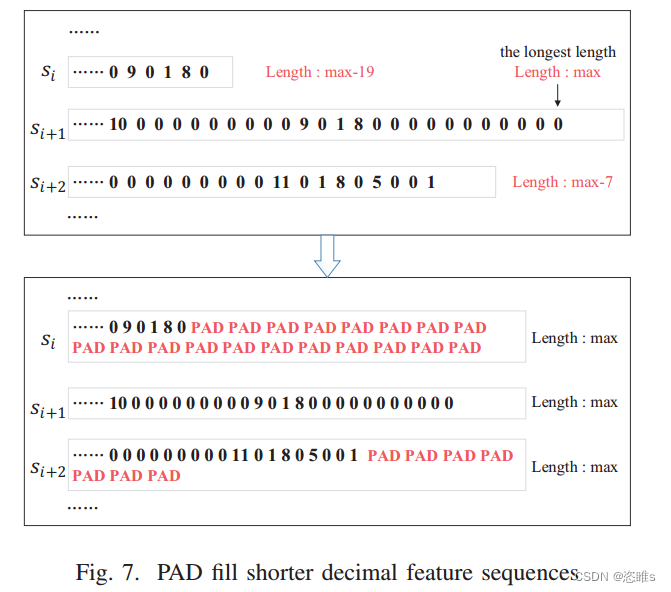
- 由于EtherCAT协议消息的长度不一致,需要插入上述提到的特殊字符PAD来填充较短的十进制特征序列,使所有消息的长度与最大长度相同。然后得到了输入特征序列,如图7所示。
-
4、训练Seq2seq和生成
- 使用批量(一次性处理的数据量)输入的特征序列对seq2seq模型进行预训练,以而获得正式训练的初始化参数。正式训练的输入特征数据被划分为:训练集、验证集和测试集。在完成训练和验证步骤后,获取了生成半有效序列所需的相关参数。
- 特殊字符STA表示预测的开始,特殊字符END表示预测的结束。我们利用Adam算法对特征数据进行多轮训练(如epoch = 1,3,8,13,18,23,28),不同轮次的训练数据被保存。
- 由于所有生成的序列长度都是最大的,所以还需要将每个序列中的特殊字符PAD被移除还原到序列的原始长度。
- SeqFuzzer改变了真实协议消息中的某些字节,如图8所示。
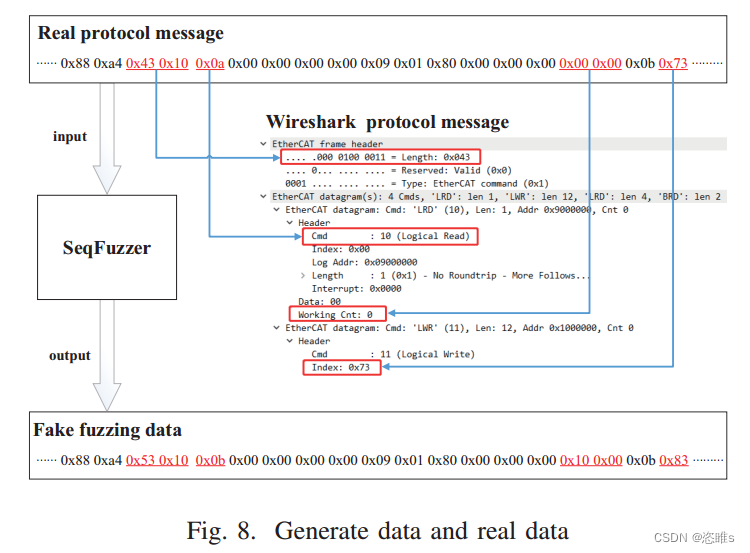
5、模糊测试和结果
- SOEM (Simple Open EtherCAT Master)是一个免费、开源的EtherCAT软件库,通过裸套接字发送和接收EtherCAT帧。基于SOEM源代码,我们在Ubuntu17 Linux操作系统上开发了EtherCAT测试主站。我们使用USB网络端口集线器作为主PC接口,以实现Beckhoff主站的硬件能力。为了保持与捕获环境相同的监视条件,ET2000被用于连接主站和从站EK1100。
- 【注】裸套接字 (Raw Socket)指的是在网络编程中,可以直接访问底层网络协议的一种套接字。通常,套接字是一个应用层与传输层之间的接口,隐藏了底层网络细节,而裸套接字则提供了更底层的访问权限,允许开发者自定义协议头部等网络层细节。
- 使用裸套接字,程序可以直接构建和解析网络数据包,而不受操作系统或高层网络库的限制。这种直接的访问权限使得开发者可以实现更灵活、更底层的网络操作,但也需要对网络协议和数据包结构有深入的了解。
- 【注】裸套接字 (Raw Socket)指的是在网络编程中,可以直接访问底层网络协议的一种套接字。通常,套接字是一个应用层与传输层之间的接口,隐藏了底层网络细节,而裸套接字则提供了更底层的访问权限,允许开发者自定义协议头部等网络层细节。
- 由SeqFuzzer生成的半有效测试数据通过SOEM主站发送到从站,消息在Wireshark上显示,同时ET2000监听。在实验过程中,我们在Wireshark中发现了红色数据帧错误标志。此外,为了确定是否接收到传输的消息,使用了两个标准:EtherCAT现场总线的诊断LED和EtherCAT子消息中的WKC (工作计数器)处理标志。
- 【注】EtherCAT帧通常包含一个主消息("Process Data")和零个或多个子消息。子消息是主消息的一部分,其中包含实际的应用数据。
- 用以下标准来判断实验结果:
- 识别率:发送的消息是否被Wireshark识别为EtherCAT协议。
- 录取率:从机处理的消息的比例。
- 检测能力:检测EtherCAT协议漏洞的能力。
5.1、识别率
- 在Wireshark的“protocol”语法列中显示协议标志。
- 传输的消息数据的帧类型为0x88A4,但部分失败数据会被错误地识别。
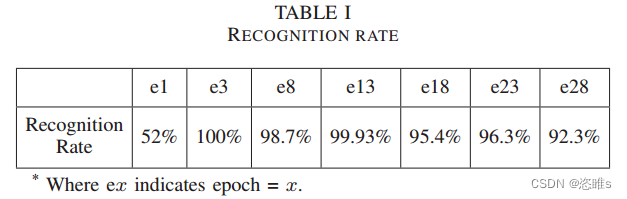
- 不同epoch的识别率如表1所示。当epoch等于1时,识别率很低,大量的数据包没有被识别为EtherCAT消息。这可能是由于LSTM的训练不足。
- 当epoch为e3、e8或e13时,获得了理想的识别率。这表明SeqFuzzer是高度自动化且易于访问的,因为数据生成过程不需要人工参与,不需要先前对协议的了解,并且不依赖于特定的协议。
5.2、录取率
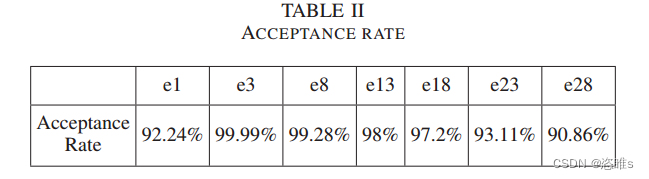
- 根据子消息(EtherCAT数据帧中的一部分)中的索引字段,获取传输和接收消息对。通过计算消息对中WKC (工作计数器)字段的变化次数,得到了接录取率,如表2所示。
- 结果表明,生成的数据满足EtherCAT的状态转换关系。表明SeqFuzzer能够为有状态的协议生成测试数据。当epoch在3到13之间时,接受率良好。随着epoch的增加,接受率下降。
5.3、检测能力
- 现工业协议有许多已知的漏洞,例如中间人攻击 (MITM)、MAC地址欺骗、从站地址攻击、数据包注入等,其中MAC地址对于协议检测是重要的。
- 对于EtherCAT,我们发现在发送不同的MAC地址时,Wireshark和现场LED会表现出不同的行为。为了更好地分析,我们讨论两种情况下的检测能力:
- 真实的MAC地址加上构造的内容:真实MAC地址代替MAC地址,再与SeqFuzzer构造的协议数据内容结合,作为模糊测试的数据。
- 构造的MAC地址加上构造内容:利用SeqFuzzer构建的协议数据来测试MAC地址欺骗漏洞。
- 真实的MAC地址加上构造的内容
- 将生成的协议数据的MAC地址替换为实际MAC地址,以获得消息对。经过分析,我们检测到以下漏洞:
- 数据包注入 (Packet injection attack)
- SeqFuzzer修改了子消息的数据字段,但EtherCAT帧头中的长度字段与子消息中的字节数不匹配。
- 尽管存在长度字段不匹配的情况,消息仍然被接收,表明发生了成功的数据包注入攻击。
-
中间人攻击 (MITM attack)
- 在消息对中,SeqFuzzer仅改变了数据字段,但从站处理了修改后的消息。
- 如果主站被操纵以使用与PLC相同的MAC地址并修改消息数据,一旦从站接受它,将导致中间人攻击。这种攻击危害了主站和从站之间通信的完整性。
-
未知攻击 (Unknown attacks)
- 还存在其他潜在的危机,例如数据字段发生变化,但工作计数器 (WKC)未受影响。
- 数据包注入 (Packet injection attack)
- 将生成的协议数据的MAC地址替换为实际MAC地址,以获得消息对。经过分析,我们检测到以下漏洞:
- 构造的MAC地址加上构造内容
- 通过SOEM主站将SeqFuzzer生成的协议数据发送到从站。观察现场LED的闪烁并查看工作计数器 (WKC)的变化,以确定从站是否收到来自未知MAC地址的消息。如果收到了消息,就存在MAC地址欺骗漏洞。
- DetectEcat是一个为检测漏洞统计而开发的程序。程序算法如下:
-
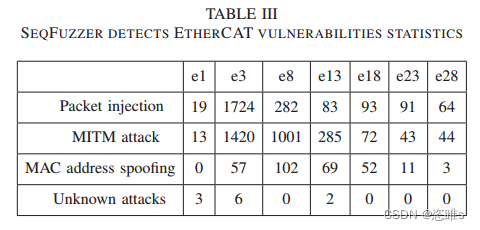
- 在发送132,200条生成的虚假消息之后,攻击的统计数据显示在表3中。其中,数据包注入攻击和中间人攻击的数量相对较高。当eopch范围从5到13时,结果显示出良好的检测能力。
- 在这个实验中,SeqFuzzer自动学习了EtherCAT负载帧结构,即使在EtherCAT格式未知的情况下,生成具有高接收率和检测能力的模糊数据,并成功检测到了几个安全漏洞。

五、总结
- 本文提出了一个模糊测试框架SeqFuzzer,它可以自动从网络流量中学习协议格式,并生成虚假但可信的消息作为测试用例。
- 我们使用SeqFuzzer测试EtherCAT协议。SeqFuzzer在EtherCAT消息格式未知的情况下,自动生成具有高接收率和检测能力的模糊数据,并成功检测出EtherCAT的多个安全漏洞。
- 在未来的工作中,我们首先计划将SeqFuzzer与其他深度学习模型(如卷积神经网络和生成对抗网络)结合起来,以实现更好的协议特征学习。其次,我们计划测试更多的工业协议,如Powerlink和Profinet,以便将来评估SeqFuzzer。
















 1216
1216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











