






一、背景
某电商公司非常注重自己的落地页设计,希望通过改进设计来提高转化率。以往该公司全年转化率平均在13%左右,现在希望设计的新页面能够带来更高的转化率,希望新页面的转化率能有2%的提升,达到15%。在正式推出新页面之前,该公司希望通过AB测试在小范围的用户中进行测试,以确保新页面的效果能够达到预期目标。
二、实验设计
(1)提出假设
在本案例中,我们并不能确定新页面的性能一定比当前的页面更好。所以,这里选择双尾检验。
原假设H0:新版落地页转化率与旧版落地页转化率相比没有变化
备择假设H1:新版落地页转化率与旧版落地页转化率相比有变化
(2)确定样本量
方法一:公式计算
其中=13%,
=15%,𝛼=0.05,𝛽=0.2
计算出最小样本量为4715
方法二:Python计算
import numpy as np
import pandas as pd
import scipy.stats as stats
import statsmodels.stats.api as sms#计算效果量
effect_size = sms.proportion_effectsize(0.13,0.15)
#计算样本量
sample_size = sms.NormalIndPower().solve_power(
effect_size,
power = 0.8,
alpha = 0.05,
ratio = 1
)
np.ceil(sample_size)运行结果为4720.0
方法三: 网页计算器(方便)
三、数据清洗
df = pd.read_csv('ab_data.csv')
#查看数据
df.head()

df.info()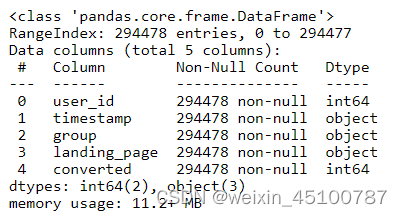
字段名称含义:
user_id:用户ID
timestamp:用户访问页面的时间
group:用户分组情况(新落地页为treatment组,旧版落地页为control组)
landing_page:每位用户看到的落地页(分为新旧两版落地页)
converted:是否成功转化(1代表成功转化,0代表未转化)
df.value_counts('group')
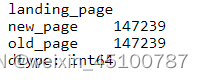
df.value_counts('landing_page')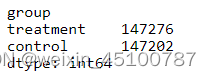
#处理时间字段
date = pd.to_datetime(df['timestamp'],format='%Y-%m-%d').dt.strftime('%Y-%m-%d')
df['timestamp']=date
df.head()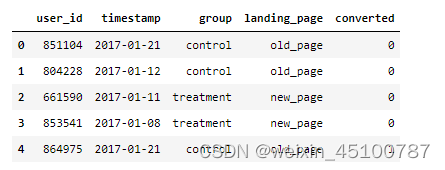
#检查缺失值
df.isnull().sum()
#检查重复值
df.duplicated().sum() #整体数据
#结果为0
#检查用户ID重复值
df['user_id'].duplicated().sum()
#结果为3894
df[df['user_id'].duplicated()]['user_id'] 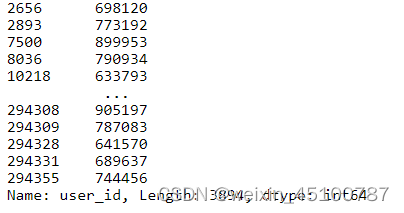
#随机抽取其中一个用户ID查看
df[df['user_id']==698120] 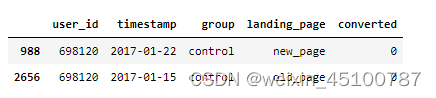
#去除重复值
del_id=df[df['user_id'].duplicated()]['user_id'].values
df2=df[-df['user_id'].isin(del_id)]
df2 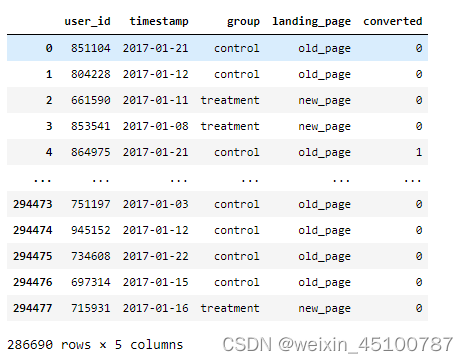
#确保control组看到旧页面,treatment组看到新页面
pd.crosstab(df2['group'],df2['landing_page']) 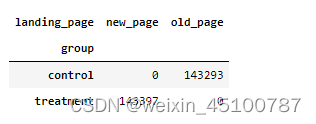
四、假设检验
由于样本非常大,所以使用Z检验
from statsmodels.stats.proportion import proportions_ztest, proportion_confint
control_group=df2[df2['group']=='control']['converted']
treatment_group=df2[df2['group']=='treatment']['converted']
n_con=control_group.count()
n_treat=treatment_group.count()
successes=[control_group.sum(),treatment_group.sum()]
nobs=[n_con,n_treat]
z_zast,pval=proportions_ztest(successes,nobs=nobs)
(lower_con, lower_treat), (upper_con, upper_treat) = proportion_confint(successes, nobs=nobs, alpha=0.05)
print(f'z statistic:{z_zast:.2f}')
print(f'p-value:{pval:.3f}')
print(f'ci 95% for control group):[{lower_con:.3f},{upper_con:.3f}]')
print(f'ci 95% for treatment group:[{lower_treat:.3f},{upper_treat:.3f}]')
print(f'置信区间:[{lower_treat - lower_con:.4f} , {upper_treat - upper_con:.4f}]')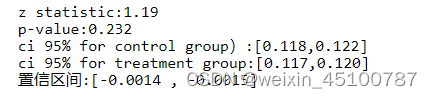
五、分析结果及建议
由于计算出来的P值0.232高于显著水平α=0.05,所以不能拒绝原假设,这意味着新版落地页与原版落地页没有明显不同。
而且置信区间为[-0.0014 , -0.0015],表明实验组指标小于对照组指标,说明新版落地页的真实转化率更有可能不如原版落地页的真实转化率。进一步证明了,新版设计并不是一个很好的改进。
















 3765
3765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











