






spark-submit 脚本中有个 --files 属性,发现每次调用配置类要写一长串的ConfigUtils.getProperty(new FileInputStream(SparkFiles.get(filename)),key),就找到了以下2种 不需要–files指定的方法(方法二与–files过程大致相同)
–files的使用 :
获取文件数据流:
executor:inputStream = new FileInputStream(fileName)或者和driver相同
driver: inputStream = new FileInputStream(SparkFiles.get(fileName))
方法一:
本地或HDFS传入,直接使用。我们知道spark先启动Driver再将任务数据打包分发到Executor执行,spark是粗粒度的,任务下发只会执行一次,这里就引伸出一个关键问题:driver在下发的时候会下发已有数据的内存中的对象,还是未加载的配置对象的文件模板(–files采用这种方法,),如果是后者也就意味这方法本地文件并不可用,只能读取hdfs文件。
//properties对象
object prop{
private val properties = new Properties()
private var source: BufferedSource = _
//读本地文件
def getProperty(key: String): String = {
if(properties.isEmpty){
println("setkey*********************")
try {
source = Source.fromFile("lib/SparkApp.properties")
} catch {
case ex: FileNotFoundException => {
source = Source.fromFile("SparkApp.properties")
}
}
properties.load(source.bufferedReader())
}
println("getkey*********************")
properties.getProperty(key)
}
//读hdfs
def getProperty(key: String): String = {
if(properties.isEmpty){
println("setkey*************************")
try {
val hdfsPath1: String = "/user/hadoop/user/SparkApp.properties"
val conf = new Configuration()
conf.set("fs.hdfs.impl.disable.cache", "true")
val fs: FileSystem = FileSystem.get(URI.create(hdfsPath1), conf)
val stream: FSDataInputStream = fs.open(new Path(hdfsPath1))
properties.load(stream)
} catch {
case ex: FileNotFoundException => {
source = Source.fromFile("SparkApp.properties")
}
}
}
println("getkey*********************")
properties.getProperty(key)
}
object Sub03 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("Testproperties")
val ssc = new StreamingContext(conf, Durations.seconds(3))
ssc.sparkContext.setLogLevel("WARN")
println("driver初始化properties对象----"+ ConfigUtils.getProperty("kafka.group.id"))
val socketDS1: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 6666)
val socketDS2: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 7777)
val arr: ListBuffer[DStream[String]] = new ListBuffer[DStream[String]]
arr += socketDS1
arr += socketDS2
val unionDS: DStream[String] = ssc.union(arr)
val flatMapDS: DStream[String] = unionDS.flatMap(_.split(" "))
val pairDS: DStream[(String, Int)] = flatMapDS.map(f => {
//这里socket有数据就会执行print
println(TaskContext.get.partitionId()+"map()----"+ConfigUtils.getProperty("kafka.group.id"))
(f, 1)
})
val reduceByKeyDS: DStream[(String, Int)] = pairDS.reduceByKey((_ + _))
reduceByKeyDS.foreachRDD((r, t) => {
//此处2个配置均在driver中执行
println(s"count time:${t}, ${r.collect().toList} ++++++${ConfigUtils.getProperty("kafka.group.id")}")
println(s"count time:${t}, ${ConfigUtils.getProperty("KafkaParameter")}")
})
ssc.start()
ssc.awaitTermination()
}
}
}
在executor初始化了一半

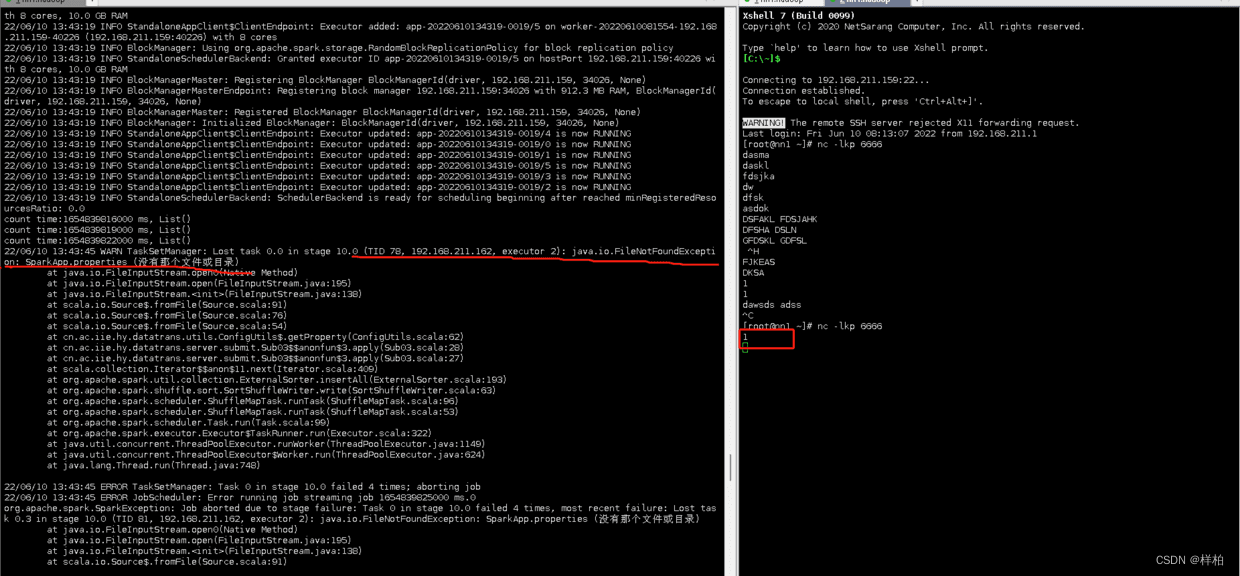
executor打印台报错
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K7NT6KFj-1654854795819)(https://upload-images.jianshu.io/upload_images/27445127-db9c79878aec101a.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)]](https://img-blog.csdnimg.cn/cf7bba58a7f54cea95175b86e02b9a72.png)
控制台报错
读取本地文件的过程
-
通过executor的日志大志顺序是先创建本地文件夹,然后将java包和运行环境放入临时文件夹等executor拉取,然后executor再执行,最后读取文件失败报错
-
报错很好理解,配置对象在初始化某个在executor上进行,worker和driver不在一台机器上时,通过io读不到本地文件SparkApp.properties报错,因为那个文件原本是在driver端!。
-
先在driver机器上初始化配置类 由driver下发任务,后面的配置类就不会初始化了
读取hdfs文件的过程
- 先在driver机器上初始化配置类 由driver下发任务,后面在executor的每台机器上都会初始化一次
输入ab和abc 按hash同台机器上,1s不到就执行完成,而w按hash第一次在另一台机器要从hdfs上初始化配置对象,用时5s

另外从driver控制台和执行节点控制台也可以看出
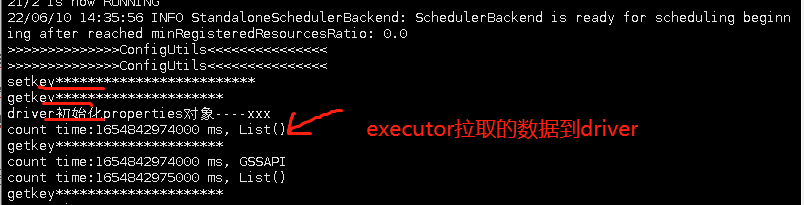
每个executor端打印台只初始化了一次后多次使用,这个很好的验证了读取hdfs在executor初始化,并且对配置对象初始化了一次
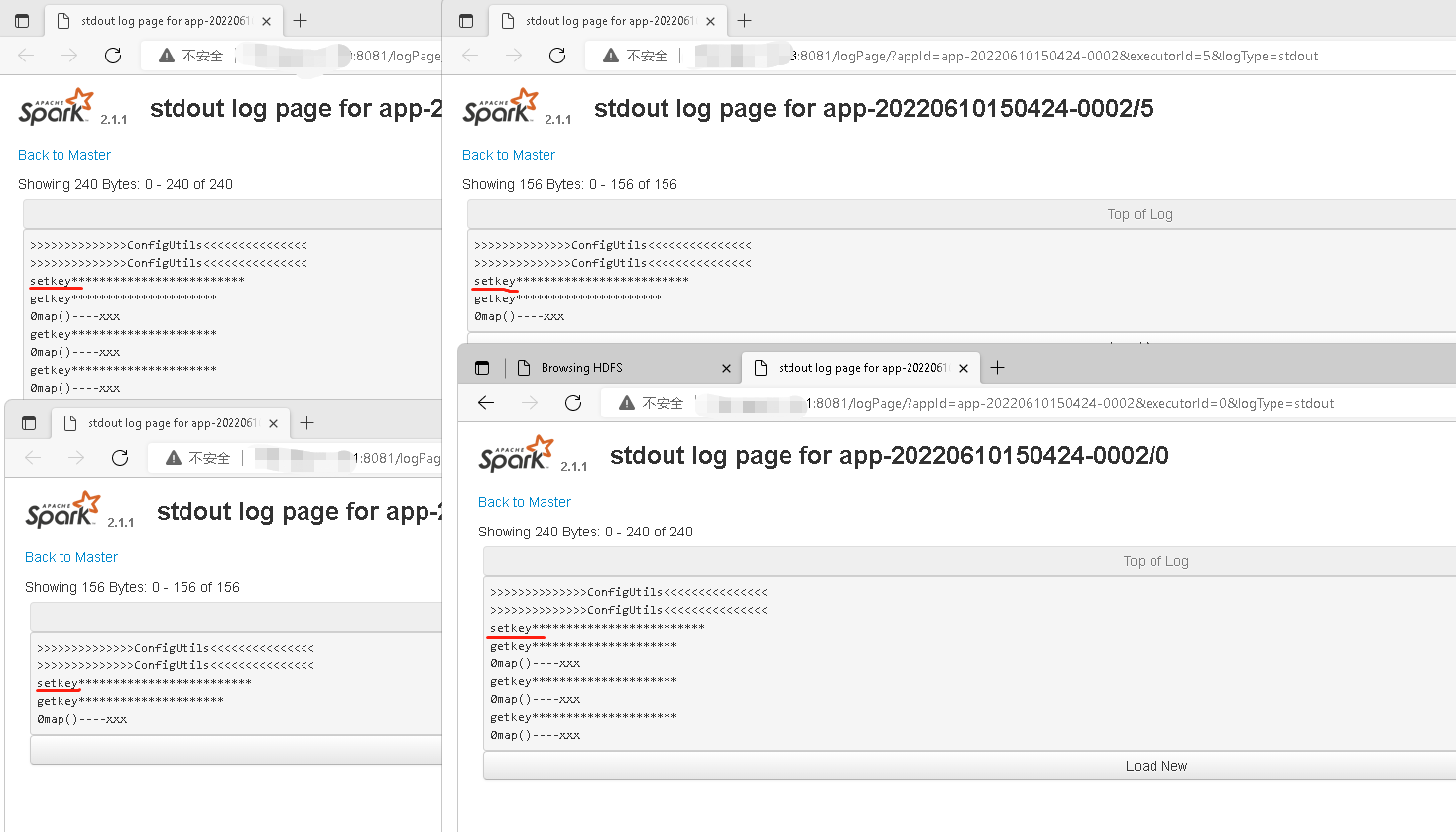
方法一结论:使用这种方法关键配置对象不论是在driver还是executor要求都必须能访问到该文件系统,就不会报错,比如HDFS
方法二:
利用sc.addFile()方法
- 本质上spark-submit脚本的 --file方法最后也是调用的addFile()方法,可以自己封装一下,但是调用配置时也是要写SparkFiles.get(filename),因为这个要依赖底层的SparkEnv,所以本质上并没有简化
/**
* Add a file to be downloaded with this Spark job on every node.
*
* If a file is added during execution, it will not be available until the next TaskSet starts.
*
* @param path can be either a local file, a file in HDFS (or other Hadoop-supported
* filesystems), or an HTTP, HTTPS or FTP URI. To access the file in Spark jobs,
* use `SparkFiles.get(fileName)` to find its download location.
*/
def addFile(path: String): Unit = {
addFile(path, false)
}
/**
* Add a file to be downloaded with this Spark job on every node.
*
* If a file is added during execution, it will not be available until the next TaskSet starts.
*
* @param path can be either a local file, a file in HDFS (or other Hadoop-supported
* filesystems), or an HTTP, HTTPS or FTP URI. To access the file in Spark jobs,
* use `SparkFiles.get(fileName)` to find its download location.
* @param recursive if true, a directory can be given in `path`. Currently directories are
* only supported for Hadoop-supported filesystems.
*/
def addFile(path: String, recursive: Boolean): Unit = {
val uri = new Path(path).toUri
val schemeCorrectedPath = uri.getScheme match {
case null | "local" => new File(path).getCanonicalFile.toURI.toString
case _ => path
}
val hadoopPath = new Path(schemeCorrectedPath)
val scheme = new URI(schemeCorrectedPath).getScheme
if (!Array("http", "https", "ftp").contains(scheme)) {
val fs = hadoopPath.getFileSystem(hadoopConfiguration)
val isDir = fs.getFileStatus(hadoopPath).isDirectory
if (!isLocal && scheme == "file" && isDir) {
throw new SparkException(s"addFile does not support local directories when not running " +
"local mode.")
}
if (!recursive && isDir) {
throw new SparkException(s"Added file $hadoopPath is a directory and recursive is not " +
"turned on.")
}
} else {
// SPARK-17650: Make sure this is a valid URL before adding it to the list of dependencies
Utils.validateURL(uri)
}
val key = if (!isLocal && scheme == "file") {
env.rpcEnv.fileServer.addFile(new File(uri.getPath))
} else {
schemeCorrectedPath
}
val timestamp = System.currentTimeMillis
if (addedFiles.putIfAbsent(key, timestamp).isEmpty) {
logInfo(s"Added file $path at $key with timestamp $timestamp")
// Fetch the file locally so that closures which are run on the driver can still use the
// SparkFiles API to access files.
Utils.fetchFile(uri.toString, new File(SparkFiles.getRootDirectory()), conf,
env.securityManager, hadoopConfiguration, timestamp, useCache = false)
postEnvironmentUpdate()
}
}
这里源码可以看出支持local,http,https,ftp,最后调用了postEnvironmentUpdate()方法进行提交。














 622
622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









