






本来是做大数据的,主要走的是Python路线,但是被留在信息部门工作牵扯一些软开工作,所以学习Java软件开发,同事的态度十分嚣张看不起人,处处直言“也不看看我简历比你长两页”,遂自发学习,过程中也经历了一些困难,于此记录一下,同时也算是帮助有心上进的“同是天涯沦落人”共同进步!
我的实践主要来自大佬的教程,原文在这里,http://t.csdnimg.cn/NmUZ2,大佬的表达已经很简单明了,我这里主要是记录一下自己的学习,同时也尽可能的用通俗到非程序员也能看懂的行文来分享给正在学习框架的朋友们,希望都能尽快的掌握这个!有些实在细碎、绕不开的点,等这篇完结了,单独再开一篇记录吧,
一、创建基础项目
(1)、pom文件
从IDEA创建或者从网站创建都可以,重点在于是否生成pom.xml文件。如果没有生成的话,建议从网站生成→start.springboot.to,当然也可以自己添加。
这个文件的重点作用是里边提供了很多所谓的“依赖”,提供的功能是完全类似于单个文件的import部分的,可以通俗的理解一下就是,import导入的包,好比小麦,可以磨制面粉,可以留作麦种,可以做酒精,可以作饲料等等,功能较为基础但适用范围很大。而pom.xml里边所谓的依赖,类似于已经加工成型可以直接使用的饺子皮、馄饨皮,只适合用于包饺子,不再适合酿酒、作饲料等等。
(2)、注解爆红
在后续的编码过程中,如果出现注解飘红的情况,大概率原因是因为这个文件里边缺少了相应的依赖,解决办法有很多,最高效、准确的应该是,从网上搜索飘红报错的内容,是缺少哪个依赖,然后将提供的依赖复制粘贴进pom.xml文件,此时复制进去的内容会飘红,点击右侧的Maven管理器刷新即可。
二、分层搭建
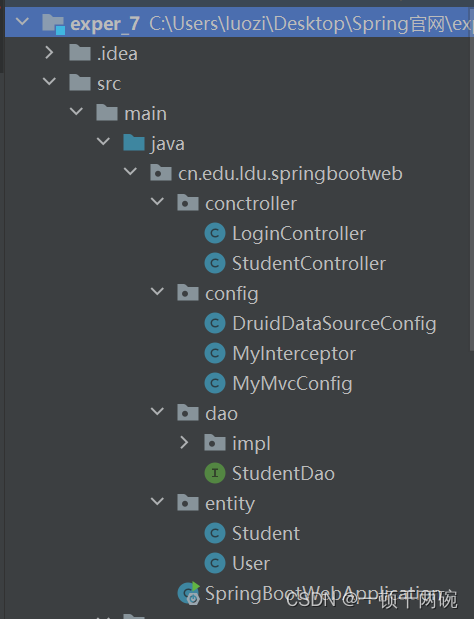
项目整体的分层如下,
(1)、创建实体类
所谓的实体类,指的是,开发的软件主要服务的对象,举个例子,开发的是餐饮行业的系统,那么实体类可能需要菜品(variety of dishes)、员工等等实体类,然后又包括不同的属性等等。
这里的例子是学生信息管理系统。那么我们有两个实体类,一个是学生本身这个类,另外一个是登录这个系统的用户,考虑到实际的场景中,学生信息管理系统,那么辅导员肯定是要有账号登录的,但是可能一部分学生(如班长等)也会有登录的需要。所以有
package cn.edu.ldu.springbootweb.entity;
import lombok.Data;
import java.math.BigInteger;
@Data
public class User {
private BigInteger userId;
private String userName;
private String pass;
}
这里的对象指的是“登录学生信息管理系统的人”,有些学生可能一次也不用登录这个系统,但他仍然作为一个Student,所以再有Student实体类如下:
package cn.edu.ldu.springbootweb.entity;
import lombok.Data;
import org.springframework.stereotype.Component;
import java.math.BigInteger;
@Data
@Component
public class Student {
private String check;
private BigInteger id;
private String username;
private String password;
private String course;
private User user;
}
到这里有些问题,提一下记录一下,
1、为什么两个实体类不需要get、和set函数?
因为两个实体类里边都使用了@Data注解,这个注解来自于Lombok库,作用即是通过使用注解自动化模板代码的生成,除了get和set函数等还包括equals、hashCode等。所以看似缺少相应的构造函数,实际由@Data已经给出。
2、为什么Student实体类多了一个@Component注解?
这个会牵扯到后边的代码,这里在登陆系统时的账号密码是固定唯一的,不牵扯到与数据库的交互,所以User不需要@Com[onent注解,而Student类表示学生的信息,包括之后的增删改查等等功能牵扯到与数据库交互,所以需要添加@Component注解。先上代码看一下
@RequestMapping("/toLoginPage")
public String login(ModelAndView modelAndView, @Valid Student student, BindingResult bindingResult,Model model){
if(bindingResult.hasErrors()){
modelAndView.addObject("error",bindingResult.getFieldError().getDefaultMessage());
modelAndView.setViewName("login");
return "login";
}
String username = student.getUsername();
String password = student.getPassword();
if(!"root".equals(username)){
modelAndView.addObject("error","无此用户!");
modelAndView.setViewName("login");
return "login";
}
if(!"123456".equals(password)){
modelAndView.addObject("error","密码错误!");
modelAndView.setViewName("login");
return "login";
}
if("root".equals(username)&&"123456".equals(password)){
List<Student> studentList=studentDao.findAll();
model.addAttribute("studentList", studentList);
modelAndView.addObject("username",username);
modelAndView.setViewName("studentList");
return "studentList";
}这里还在“创建实体类”这一步骤,避免混乱,暂不对Control层的代码做过多的记录,看到User即登录系统的人账号是固定的即可,不需要与数据库进行交互,因而User不需要@Component注解,这里算是一个例子中还可以进一步开发的方向。
这个原因从程序员的角度来讲就是,数据实体(Entity)通常是一个用于表示数据中表的类,在ORM框架下,类的每个实例对应表中的一行数据,类的属性对应表的列。结合开发的场景,Student将作为SpringBoot的容器使用,而User暂且不是。
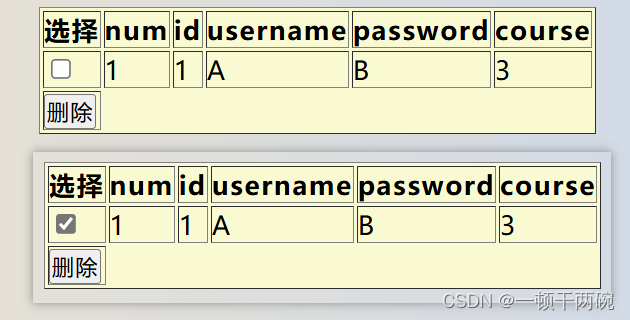
最后,至于Student实体类里边的check属性,是与前端对应的单选框,用于表示选中该条数据进行操作,看一下代码运行结果就明显了
(2)、数据访问层接口创建
这里有Dao层和Mapper层两种路线,实例选择了Dao层的路线,如果选择Mapper层的路线,那么除了建立Mapper的接口文件之外,还需要在resorces文件下创建mapper文件存储mapper.xml进行编写,同时安装MybatisX插件。先上代码看一下,之后再啰嗦两条路线的区别。
package cn.edu.ldu.springbootweb.dao;
import cn.edu.ldu.springbootweb.entity.Student;
import java.math.BigInteger;
import java.util.List;
public interface StudentDao {
int insert(Student student);
//插入、更新、删除三种情况下,返回的int是影响行数,若为0则表示操作失败
int update(Student student);
int delete(BigInteger id);
List<Student> findAll();
//这里查找所有的学生,所以返回的是一个列表(List)
Student findById(BigInteger id);
//这里是根据ID查找学生,所以接收的参数是学生的id返回一个Student类
List<Student> findByName(String username);
//这里是根据账户名称返回List,用户名并不唯一,也可改为唯一,则同样返回一个Student
}下面啰嗦一下所谓的Dao层和Mapper层的区别,主要是使用的技术和习惯
1、DAO(Data Access Object)层,
- DAO是一种设计模式,它定义了一个统一的接口,用于访问数据源,这样就可以将数据访问逻辑与业务逻辑分离
- DAO层通常包含一系列的接口和实现类,接口定义了数据访问的方法,而实现类则包含了具体的数据访问逻辑
- 在Spring应用程序中,DAO层的实现类通常会使用Spring的数据访问抽象,如JdbcTemplate或Spring Data JPA。
2、Mapper层:
- Mapper 层这术语通常与MyBatis框架一起使用,MyBatis是一个SQL映射框架,允许将SQL语句与Java方法映射
- Mapper层包含了一系列耳朵接口,这些接口的方法通常与数据库操作一一对应,MyBatis会动态生成这些接口的实现类
- Mapper接口的SQL语句通常写在XML文件中或直接作为注解放在接口上方。
总结,DAO是一个更通用的概念,它可以用于任何数据访问技术,而Mapper层通常特指MyBatis框架中的数据访问层,一般视具体情况选择。
(3)、接口实现类编写
上边也提到过,DAO路线下,接口需要有实现类,直接上代码,注释都在里边了
package cn.edu.ldu.springbootweb.dao.impl;
import java.math.BigInteger;
import java.util.List;
import cn.edu.ldu.springbootweb.dao.StudentDao;
import cn.edu.ldu.springbootweb.entity.Student;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.RowMapper;
import org.springframework.stereotype.Repository;
@Repository
public class StudentDaoImpl implements StudentDao {
@Autowired
// 这个注解用于自动注入JdbcTemplate实例,这个实例是Spring提供的
// 用于简化JDBC操作的模板类,它包含了执行SQL语句、查询、更新等操作的方法
private JdbcTemplate jdbcTemplate;
// 声明了一个JdbcTemplate声明了一个JdbcTemplate类型的私有成员变量(属性),
// 用于后续的数据库操作
@Override
public int insert(Student student) {
/*String sql = "insert into student(id,username,password,course) " +
"values(:Id,:Username,:Password,:Course)";
Map<String, Object> param = new HashMap<>();
param.put("Id", student.getId());
param.put("Username", student.getUsername());
param.put("Password", student.getPassword());
param.put("Course", student.getCourse());
return (int) jdbcTemplate.update(sql, param);*/
//上边是另外一种执行方法,通过Map绑定参数,这种方式使用命名参数(如id,Username),而不是占位符
//重写接口,并提供具体的实现
String sql = "insert into student(id,username,password,course) value(?,?,?,?)";
//value(?,?,?,?)是SQL语句中的占位符,用于后续绑定具体的参数值
Object[] params = new Object[]{
student.getId(),
student.getUsername(),
student.getPassword(),
student.getCourse()
};
//创建了一个对象数组,包含了要插入的学生记录的所有字段值
//这个数组按照SQL语句中占位符的顺序排列,确保插入操作时每个字段都能接收到正确的值
return jdbcTemplate.update(sql,params);
//调用JdbcTemplate的update方法执行SQL语句。
//update方法执行插入操作,并返回受影响的行数,插入成功则返回1
}
@Override
public int delete(BigInteger id) {
String sql = "delete from student where id=?";
return jdbcTemplate.update(sql, id);
}
@Override
public int update(Student student) {
String sql = "update student set username=?,password=?,course=? where id=?";
return jdbcTemplate.update(sql,student.getUsername(),student.getPassword(),student.getCourse(), student.getId());
}
@Override
public List<Student> findAll() {
String sql = "select * from student";
RowMapper<Student> rowMapper = new BeanPropertyRowMapper<Student>(Student.class);
return this.jdbcTemplate.query(sql, rowMapper);
}
@Override
public Student findById(BigInteger id) {
String sql = "select * from student where id=?";
RowMapper<Student> rowMapper = new BeanPropertyRowMapper<Student>(Student.class);
Student student = jdbcTemplate.queryForObject(sql,rowMapper,id);
return student;
}
@Override
public List<Student> findByName(String username) {
String sql = "select * from student where username = ?";
RowMapper<Student> rowMapper = new BeanPropertyRowMapper<Student>(Student.class);
//创建了一个RowMapper对象,用于将查询结果集中的每一行数据映射到Student对象
//这是Spring提供的一个RowMapper实现,它可以根据数据库列名和Java对象属性名之间的映射关系自动进行映射
List<Student> studentList = this.jdbcTemplate.query(sql,rowMapper,username);
//调用JdbcTemplate的query方法执行SQL查询
//query方法接受SQL语句、RowMapper对象和一个参数(此处即username)执行查询并返回一个student对象列表
return studentList;
//方法返回查询到的学生列表,若查询结果为空,则返回一个空列表
}
}(4)、编写配置类,定义认证和授权逻辑
考虑提高应用的安全性和灵活性,接下来编写拦截器以在Spring应用程序中添加自定义的认证和授权逻辑,并提供一种机制来添加额外的请求属性以及潜在的错误处理和日志记录功能,
package cn.edu.ldu.springbootweb.config;
import org.springframework.lang.Nullable;
import org.springframework.stereotype.Component;
import org.springframework.web.servlet.HandlerInterceptor;
import org.springframework.web.servlet.ModelAndView;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.util.Calendar;
// 使用@Component注解将MyInterceptor标记为Spring的一个Bean,使其能够被Spring容器自动发现和注册
@Component
public class MyInterceptor implements HandlerInterceptor {
// preHandle方法在请求处理之前调用
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 获取请求的URI(路径)
String uri = request.getRequestURI();
// 从会话中获取名为"username"的属性,用于检查用户是否已登录
Object loginUser = request.getSession().getAttribute("username");
// 如果URI以"/root"开头,并且会话中没有"username"属性(即用户未登录)
if (uri.startsWith("/root") && null == loginUser) {
// 将用户重定向到登录页面"/toLoginPage"
response.sendRedirect("/toLoginPage");
// 返回false以阻止后续处理
return false;
}
// 如果用户已登录或者请求的URI不是以"/root"开头,则返回true,允许请求继续处理
return true;
}
// postHandle方法在请求处理之后,但在视图渲染之前调用
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response,
Object handler, @Nullable ModelAndView modelAndView) throws Exception {
// 获取当前年份
int currentYear = Calendar.getInstance().get(Calendar.YEAR);
// 将当前年份设置为一个请求属性"currentYear",这样可以在视图层使用这个属性
request.setAttribute("currentYear", currentYear);
}
// afterCompletion方法在整个请求完成后调用,即在视图渲染之后
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse
response, Object handler, @Nullable Exception ex) throws Exception {
// 这个方法当前为空,可以用于执行清理工作或记录日志等操作
}
}
这个拦截器的作用如下:
- 用户认证拦截:
检查用户是否已经登录,特别是对于访问以/root开头的路径,如果用户未登录(则会话中没有username属性),则拦截器将会重新将用户定向到登录页面/toLoginPage,确保必须经过登录才能访问特定的资源 - 权限控制:
通过检查请求的URI,拦截器可以限制对特定路径的访问,实例中,任何以/root开头的路径都会被认为是需要特殊权限的,这种权限控制可以扩展到不同的角色或者权限,以实现更细粒度的访问控制,也是这个例子可以继续开发的一个方向。 - 请求属性的添加:
在处理请求之后,拦截器将当前月份添加到请求属性中,这使得这个信息可以在后续的处理流程中使用,比如在视图渲染时显示当前的年份。这个实例中作演示用途。 - 潜在的处理错误或日志记录:
在afterCompletion方法中,可以继续开发关闭资源或者记录请求处理等相关信息,也可以添加日志记录等等,主要起到调试和监控应用程序的作用。
(4)、数据库连接配置类的编写
有了这个配置类,将允许自定义和配置以及初始化数据源,而不是只能使用SpringBoot的默认配置,@Bean注解用于指示一个方法产生一个Bean,这个Bean会被Spring容器管理,并且可以在其他地方通过@Autowired注解注入,这里将duridDataSource()方法被标记为@Bean,意味着将调用这个方法,并将返回的DuridDataSource实例作为一个Bean注册到容器中
package cn.edu.ldu.springbootweb.config;
import com.alibaba.druid.pool.DruidDataSource;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import javax.sql.DataSource;
public class DruidDataSourceConfig {
@Bean
//这里指示一个方法返回一个对象,这个对象应该被Spring容器管理,并且可以在其他地方通过@Autowired注入
@ConfigurationProperties(prefix = "spring.datasource")
//将配置文件的属性绑定到一个固定的属性上,prefix指定了配置文件中属性的前缀,这意味着所有以Spring.datasource开头的属性将被映射到druidDataSource对象的相应字段上
//下边这个方法将返回druidDataSource对象将作为"@Bean"被Spring容器管理
public DataSource druidDataSource() {
return new DruidDataSource();
}
//DruidDataSource是由阿里巴巴开源的一个数据库连接池,它提供了强大的监控和扩展功能,被调用时,Spring容器会创建一个DruidDataSource的实例,并将其作为Bean注入到容器中
}
这里白话讲一下,意思就是,定义的实体类,学生,比如他可以有年龄、爱好、技能等等属性,但这是一个空泛的类,一个概念,到学校里边去拉出来一个实实在在,看得见摸得到的学生,这个学生就是实体类的Bean,或者总要有一个固定的方式到学校里边去拉一个学生出来,也就是说,实际业务里边不会随便去拉一个学生出来,这个拉的方式,也可以是Bean,总之要有一个具体的“实现”,而不是只停留在对学生这个类的定义(类似于画像的概念)。
(5)、控制层逻辑
经过前边的铺垫终于是来到了控制层逻辑。这里举例删除的情况,代码如下:
// @ResponseBody 注解表示这个方法的返回值将直接作为HTTP响应体返回,而不是作为视图名称。
// @GetMapping 注解用于将HTTP GET请求映射到特定的处理器方法上。这里的"/delete/{id}"表示URL路径,其中{id}是一个路径变量。
@ResponseBody
@GetMapping("/delete/{id}")
public String delete(@PathVariable BigInteger id) {
// @PathVariable 注解用于从URL路径中提取变量。在这里,它将提取{id}的值并将其作为参数传递给方法。
// 注释掉的代码 id = BigInteger.valueOf(521); 表示原来有一个硬编码的ID值,但是它被注释掉了,所以现在使用从URL中提取的ID。
// 调用 studentDao 的 delete 方法,传入从URL路径中提取的ID,尝试从数据库中删除对应的Student记录。
// delete 方法返回一个整数,表示受影响的行数。如果删除成功,它应该返回大于0的值。
if (studentDao.delete(id) > 0) {
// 如果删除操作影响了至少一行,返回"删除成功!"作为HTTP响应。
return "删除成功!";
} else {
// 如果删除操作没有影响任何行,返回"删除失败!"作为HTTP响应。
// 这可能意味着没有找到具有指定ID的Student记录。
return "删除失败!";
}
}注释直接放在里边了,主要还是回去了DAO层的方法,再贴一遍相关的代码好对应
int delete(BigInteger id); @Override
public int delete(BigInteger id) {
String sql = "delete from student where id=?";
return jdbcTemplate.update(sql, id);
}student是实体类对应的数据库表的表名,也可以往上翻翻上边更详细一些。至此,基本的注释已经完成,我会尽力的使用白话来解释。
最后我要“狗叫”几下,
这个东西并没有很难,当然了也不是1+1=2的难度,也是需要花一点心思的,真的不理解为什么几个同事好特么大的优越感,当着众人的面,红口白齿的就说出来了“也不看看我简历比你长两页”,我特么今天就用白话来表达,哪里还不够白话,可以踢我,我会尽可能的白话来解释,因为专业的人不需要看我这篇文章,是能看下来的,就是外行或者基础比较薄弱的,大白话比较好理解和接受的,也祝每个同行都能工作顺利,早日开上帕拉梅拉,身边从来没有这种自觉高人一等的同事!!!















 5083
5083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









