







人工智能咨询培训老师叶梓 转载标明出处
大模型(LLMs)在处理复杂任务时展现出的巨大潜力,但却需要庞大的计算资源和存储空间,限制了它们在移动设备等资源受限环境中的应用。微软公司最新发布的Phi-3系列语言模型,以其卓越的性能和小巧的体积,打破了这一局限,为移动AI领域带来了革命性的变革。
Phi-3系列模型的优势在于它们能够在保持较小模型体积的同时,提供与大型模型相媲美的语言处理能力。这一成就得益于几个关键的技术突破和创新:
高效的训练数据:Phi-3系列模型采用了经过精心筛选和优化的训练数据集,这些数据不仅包括公开可用的网络数据,还结合了由LLM生成的合成数据,从而在较小的模型规模上实现了高性能。
先进的架构设计:Phi-3-mini模型采用了transformer解码器架构,并引入了LongRope技术来扩展上下文长度,使其能够处理更长的文本序列。
优化的存储和计算效率:通过量化技术和块稀疏注意力模块,Phi-3-mini能够在保持性能的同时,大幅减少模型所需的存储空间和计算资源。
强大的多模态能力:Phi-3-vision模型不仅能够处理文本,还能够理解和生成与图像相关的文本,这为图像和文本的联合理解提供了新的可能性。
负责任的AI实践:微软在Phi-3系列模型的开发中,遵循了负责任的AI原则,通过后训练阶段的安全对齐和红队测试,确保了模型的安全性和可靠性。
移动设备上的本地部署:Phi-3-mini的小巧体积使其能够轻松部署在现代智能手机上,实现完全离线运行,为用户提供了随时随地的智能助手。
Phi-3-mini 模型
Phi-3-mini 是一个具有3.8亿参数的语言模型,它在3.3万亿个token上进行了训练。这个模型采用了transformer解码器架构,具备4K的默认上下文长度,并通过LongRope技术可以扩展到128K的上下文长度。Phi-3-mini 的设计允许它在保持小巧体积的同时,实现与大型模型相媲美的性能。

模型的训练采用了一种创新的方法,使用了经过严格筛选的公开网络数据和合成数据。这种数据筛选策略专注于提升模型的通用知识和语言理解能力,同时在第二阶段的训练中融入了逻辑推理和专业技能的教学。

Phi-3-mini 进一步优化了模型的对齐,以增强其在对话格式下的鲁棒性、安全性。此外,模型使用了与Llama-2相似的块结构,并采用了相同的分词器,这使得为Llama-2开发的包可以轻松适配到Phi-3-mini。模型具备3072的隐藏维度、32个注意力头和32层,使用bfloat16精度进行了训练。
Phi-3-mini 的小巧体积使其可以量化到4位,仅占用大约1.8GB的内存。在iPhone 14的A16 Bionic芯片上进行的测试显示,该模型能够以每秒超过12个token的速度在设备上本地运行,且完全离线。为了处理长上下文任务,开发了Phi-3-mini的长上下文版本,其上下文长度限制扩展到了128K。这个版本的模型在质量上与4K长度的版本相当,但在处理长文本方面更为出色。

Phi-3-mini 的后训练包括两个阶段:监督微调(SFT)和直接偏好优化(DPO)。SFT使用高度策划的高质量数据,涵盖多个领域,而DPO则利用聊天格式数据、推理和负责任的AI(RAI)努力,引导模型远离不良行为。
基准测试
Phi-3-mini 在多个标准的开源基准测试中进行了评估,这些测试旨在衡量模型的推理能力,包括常识推理和逻辑推理。测试结果与phi-2、Mistral-7b-v0.1、Mixtral-8x7b、Gemma 7B、Llama-3-instruct8b 和 GPT-3.5 等模型进行了比较。所有报告的数字都是通过相同的管道生成的,以确保数字的可比性。
使用了少样本提示(few-shot prompts),在温度为0的条件下评估模型。使用的提示和样本数量是微软内部用于评估语言模型的工具的一部分。特别是,对于phi-3模型,没有对管道进行优化。
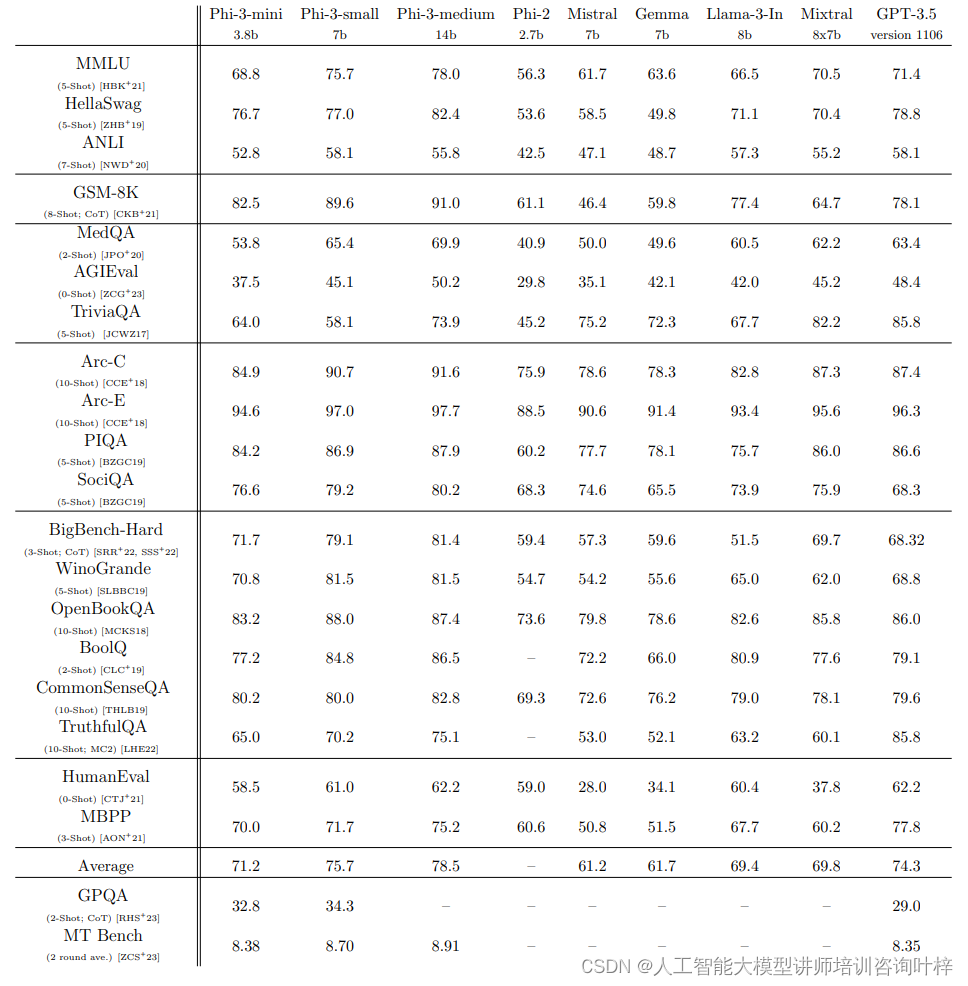
测试结果显示 Phi-3-mini 在各种基准测试中的表现与其它模型相比具有竞争力。例如,在MMLU(多项语言理解)基准测试中,Phi-3-mini 达到了68.8% 的准确率,而其他模型的准确率从56.3% 到71.4% 不等。在HellaSwag、ANLI、GSM-8K 等多个测试中,Phi-3-mini 均展现出了较高的性能。
Phi-3-mini 与其扩展模型 Phi-3-small 和 Phi-3-medium 相比,在多数基准测试中表现稍逊,这与它们的参数规模相一致。Phi-3-small 在 MMLU 中的得分为75.7%,而 Phi-3-medium 则为78.0%。类似地,在 MT-bench 测试中,Phi-3-mini 得到了8.38分,而 Phi-3-small 和 Phi-3-medium 分别得到了8.7和8.9分。
虽然在多任务学习上表现出色,但受限于规模,它在存储事实知识、多语言处理和高级推理方面存在局限。通过结合搜索引擎和多语言数据,以及针对性的后训练优化,可以缓解这些限制,但偏见和安全问题仍需进一步研究和改进。
Phi-3-Vision 模型
Phi-3-Vision 是一个多模态模型,拥有 4.2 亿参数,设计用于处理图像和文本提示,并生成文本输出。该模型由两部分组成:图像编码器(CLIP ViT-L/14)和变换器解码器(phi-3-mini-128K-instruct)。通过动态裁剪策略,模型能够适应高分辨率和不同宽高比的图像,将输入图像分割成 2D 块阵列,再将块的标记连接起来以代表整个图像。

Phi-3-Vision 模型的预训练使用了多样化的数据集,包括图像-文本文档、图像-文本对、从 PDF 文件的光学字符识别(OCR)派生的合成数据,以及图表/表格理解的数据集。预训练的目标是在文本标记上预测下一个标记,而忽略与图像标记相关的任何损失。
Phi-3-Vision 包含两个后训练阶段:监督微调(SFT)和直接偏好优化(DPO)。SFT 利用文本 SFT 数据集、公共多模态指导调整数据集以及我们自己构建的大规模多模态指导调整数据集,覆盖自然图像理解、图表/表格/图解理解/推理、PowerPoint 理解以及模型安全性等多样化领域和任务。
基准测试
Phi-3-Vision 模型在九个学术基准测试中进行了评估,这些测试覆盖科学、图表和通用知识三个领域,旨在衡量模型对视觉和文本输入的推理和感知能力。与多个基线模型相比,Phi-3-Vision 展现了其竞争力。评估采用了公平的设置,模拟了普通用户与多模态模型的交互,未使用特定提示或图像预处理。尽管评估条件一致,但由于不同的评估参数,Phi-3-Vision 的结果可能与已发布的基线模型结果有所差异。这为模型的实际应用提供了有价值的见解,并指出了进一步优化的方向。
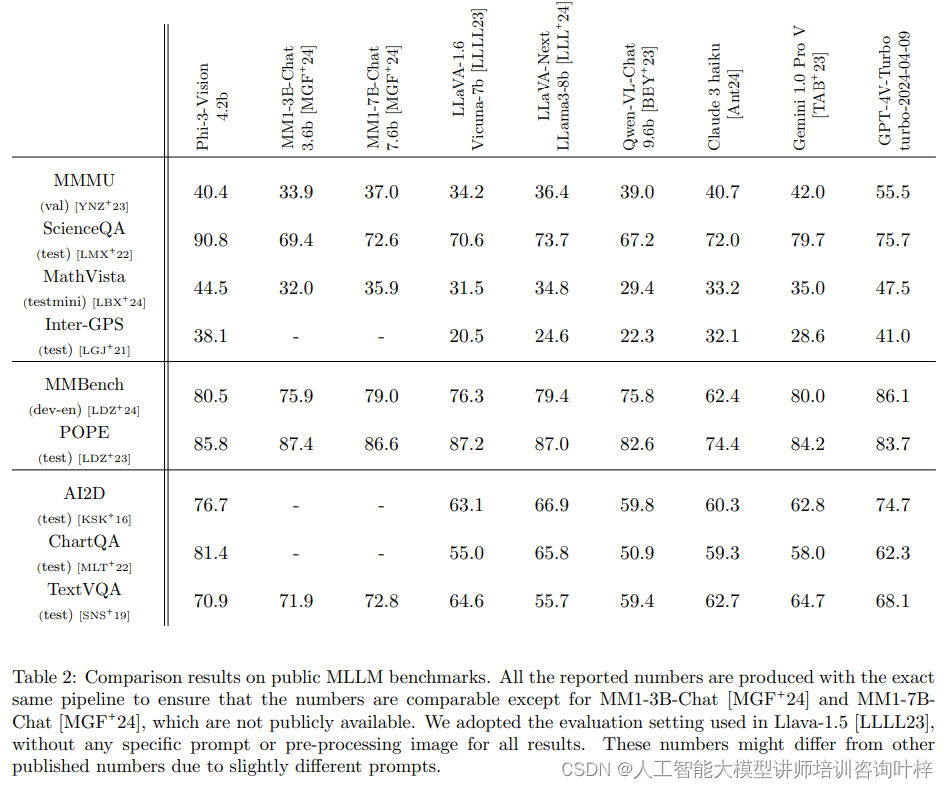
尽管 Phi-3-Vision 在多个领域表现出色,但已识别出某些限制,特别是在需要高水平推理能力的问题上。此外,模型有时会生成无根据的输出,使其在金融等敏感领域可能不可靠。为了解决这些问题,研究者计划在未来的后训练中纳入更多关注推理和幻觉相关的 DPO 数据。从负责任的 AI 角度来看,尽管安全后训练取得了显著进展,Phi-3-Vision 偶尔未能避免回答有害或敏感的查询,例如解读特定类型的验证码和描述包含虚假信息或幻觉的诈骗图像。这个问题部分源于在正常指导调整数据集的训练过程中获得的能力,如 OCR,这可以被视为帮助性和无害性之间的权衡。
论文链接:https://arxiv.org/abs/2404.14219
















 2677
2677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









