







SSD: Single Shot MultiBox Detector
一、网络结构
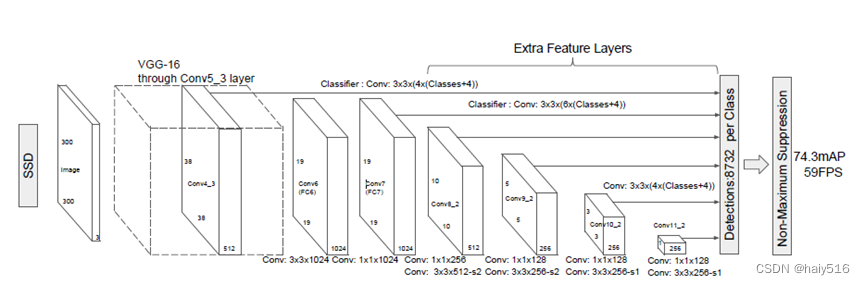
SSD网络是在VGG16的基础上修改得到的,首先将VGG16的全连接层替换为卷积层进行分类与回归,其次在原卷积层的基础上添加新的卷积层,以此实现在在多个尺度下进行检测,此处是具体的修改过程。
上图中Conv4,Conv7,Conv8,Conv9,Conv10和Conv11都有指向后面的8732分类和最后的非极大值抑制。以Conv4为例,Conv4后得到的特征图尺寸为38x38x512,对该38x38的特征图上的每个像素类似前面Faster-RCNN中的anchor一样,映射到输入图片上产生4个候选框,总共产生38x38x4=5776个候选框,然后对每个候选框进行分类和回归,而该分类和回归是通过一个3x3x(4x(Classes+4))的卷积操作完成的。其他类似,比如对Conv7,Conv8和Conv9特征图中每个像素产生6个候选框,对Conv10和Conv11特征图中的每个像素产生4个候选框。总计产生8732个候选框,对每个候选框逐级分类和回归之后进行非极大值抑制操作,即得出目标检测结果。
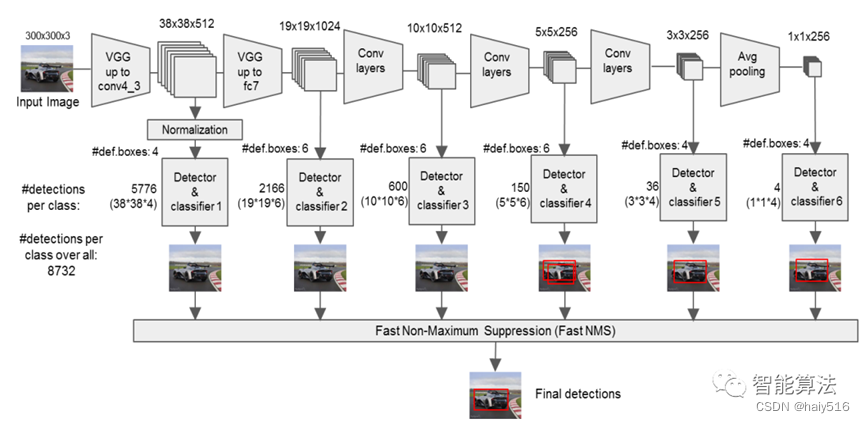
下图可以给出SSD的预测过程:
二、模型设计
1、多尺度特征映射
在Backbone末端添加多个卷积层,获取多个不同尺度的特征层,并使用多个特征层(6个)进行检测,以此检测不同尺度的目标。
2、使用卷积进行检测
针对每一个特征层,都通过卷积进行分类和回归。
3、使用default boxes
在特征图中每一个像素点处设置多个(4个或6个)不同宽高比的default boxes,对于每一个default boxes,映射到原图都会对应一个边界框,然后将这些边界框与标签进行匹配,成功匹配的边界框为正例,不成功的为负例。使用匹配好的边界框进行训练。
在进行预测时,可以根据每一个default boxes进行预测,然后通过NMS算法进行筛选,选择出效果最好的预测结果。
三、模型训练
1、匹配策略
(1)原则一:由groundtruth出发,为每一个groundtruth匹配一个IOU最大的default box;
(2)原则二:从default box出发,对剩余的还没有配对的default box与任意一个ground truth box尝试配对,只要两者之间的IOU大于阈值(一般是0.5),那么该default box也与这个ground truth进行匹配。
这就意味着一个groundtruth可以对应多个default box,但一个default box只能对应一个groundtruth。
2、损失函数

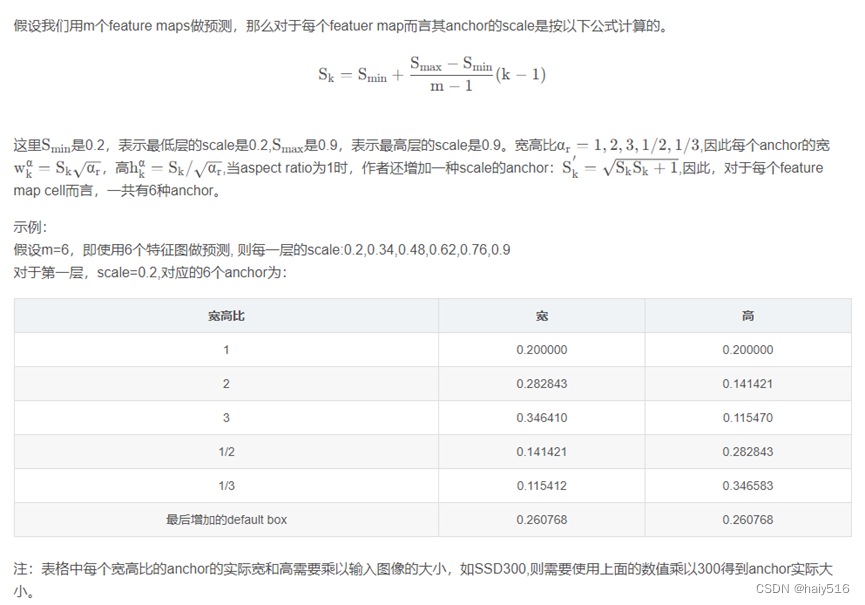
3、default boxes的确定
4、难分样本挖掘
值得注意的是,一般情况下negative default boxes数量>>positive default boxes数量,直接训练会导致网络过于重视负样本,从而loss不稳定。为了保证正负样本尽量平衡,SSD在训练时采用了hard negative mining,即依据confidience loss对default box进行排序,挑选其中confidience loss高的box进行训练,将正负样本的比例控制在positive:negative=1:3。显而易见,用来训练网络的负样本为提取的负样本的子集,那么,我们当然选择负样本中容易被分错类的困难负样本来进行网络训练这样会取得更好的效果。有下面一种说法:SSD采用了hard negative mining,就是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。
四、参考链接
1、SSD代码实现1-pytorch
2、SSD代码实现2-pytorch
3、SSD论文翻译
4、SSD详解
5、SSD算法源码与论文















 2164
2164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









