






认知诊断–KSCD模型学习

动机:通过考虑知识概念之间的内在关系,解释性地推断出学生对非交互式知识概念(即与他/她的做题记录无关的知识概念)的掌握。PS:知识点有很多,但是学生做的题中涉及到的知识点并不一定很多,有可能就很少,因此,对那些没有涉及到的知识点的诊断成了一个问题,因为做的题中没有涉及到它们,但是确实还是要诊断他们,本文因此提出。
贡献:1.从学生的反应日志中学习知识概念之间的内在关系,整合起来进而推断学生对所有知识概念(包括非交互知识概念)的掌握程度,显著提高了预测学生对非交互式知识概念的掌握的性能。
2. 设计了一个新的诊断范式。
模型:
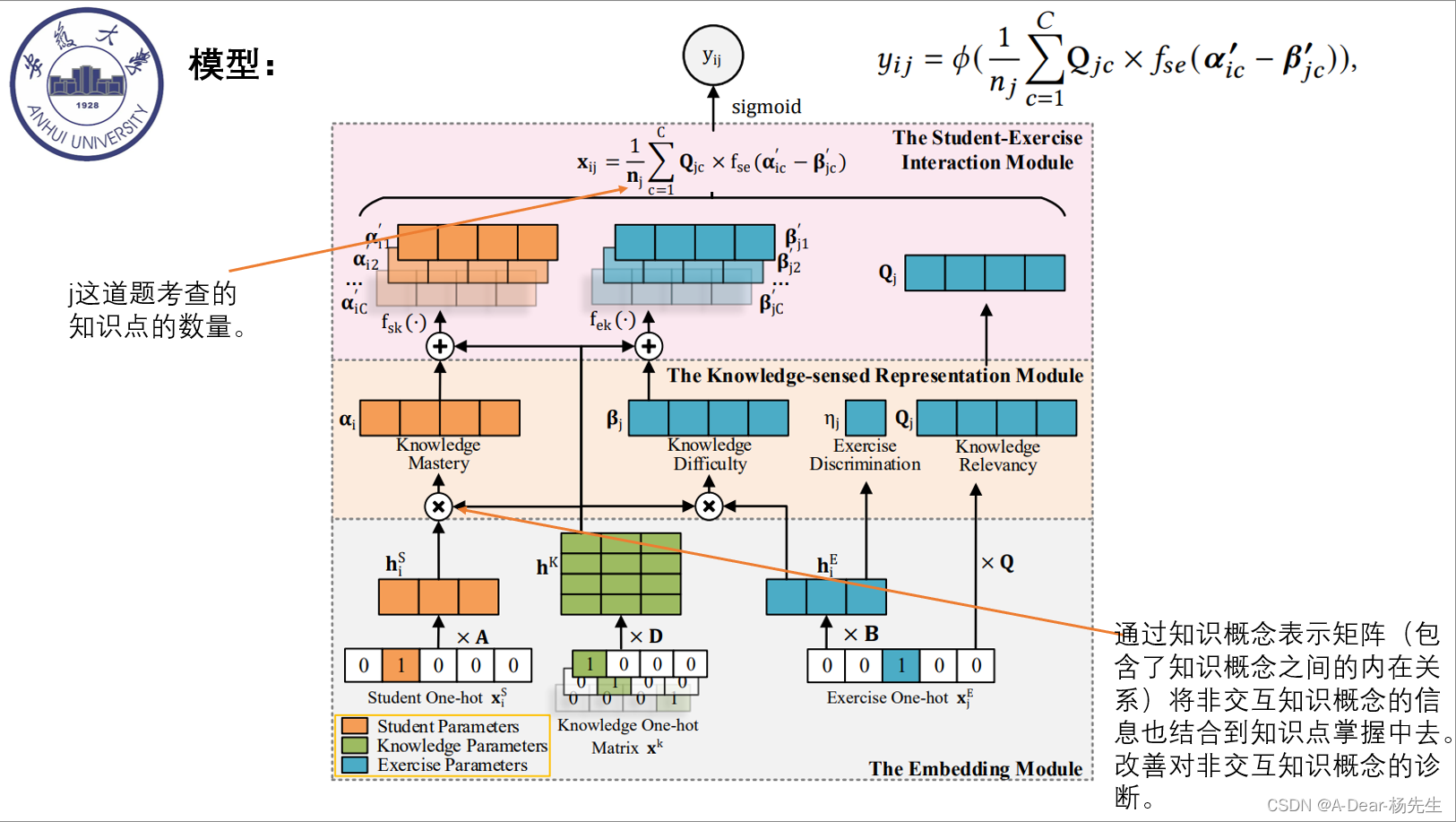
模型分为三个模块:嵌入模块、知识感知表示模块、学生-试题交互模块
1.嵌入模块:通过我对torch里面的嵌入层的学习之后,我终于算是明白了这个embeding的过程,调用embeding的过程中他会把输入编程若干个独热编码,然后会乘以一个可训练的矩阵,得到每个独热编码对应的tensor的嵌入表示,在训练的过程中,这个可训练矩阵会不断的调整,不断的变化去更好适应新的输入,从而给出更加准确的结果。好了这样讲完之后下面就很好懂了,通过嵌入,就得到了学生、试题、知识点的嵌入表示。
2.知识感知表示模块
2.1它把学生的嵌入和知识概念表示矩阵相乘,将这个得到的结果作为知识掌握向量,就是这个学生对所有试题的掌握向量,每一个分量表示他对对应题目的掌握。我觉得这个应该是最重要的,通过知识概念表示矩阵(包含了知识概念之间的内在关系)将非交互知识概念的信息也结合到知识点掌握中去。改善对非交互知识概念的诊断。
2.2把试题的嵌入和知识概念表情欧式矩阵相乘,将这个得到的结果作为知识难度向量。
2.3再通过对试题的嵌入进行非线性化操作得到试题的区分
2.4然后再用试题的独热编码乘以Q矩阵得到知识相关向量。
其实这个模块之后就可以把得到的一些向量运用到其他先用的模型中去。
这篇文章提出了一个新的诊断范式如下:
3.学生-试题交互模块
3.1 将2中得到知识掌握向量和知识概念表示矩阵hk中的每一行做一个拼接,在运用一个效用函数,把每一次拼接加运算得到的结果座位这个学生对这个试题的掌握向量。这样就得到了新的试题个数的知识掌握向量a’ij。
3.2 和上面的操作一样,通过对试题难度向量和hk的拼接和效用操作得到了新的每个题目的难度向量。
新的诊断范式:
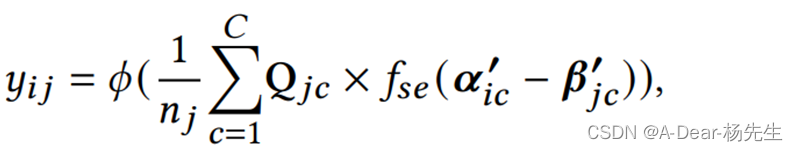
nj是说j这道题考察的知识点的数量,他这个诊断范式是说,把这个学生涉及到的题目中涉及到的知识点进行一个运算,因为Q矩阵只有0和1,没有涉及到的知识点不添加到计算中。然后把这道题涉及到的知识点得到的运算结果除以涉及到的知识点总数,就是求一个平均,在运用一个激活函数得到这个学生对这个题掌握程度yij。
好了,剩下的就是主题实验、超参实验、知识相关性实验和case study。














 860
860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









