







介绍
Flink提供了多种部署方式,本文只介绍三种常用方式,local、standalone、yarn。
安装前准备
Java8以上(必备基础环境)
Zookeeper(HA高可用需要环境)
Hadoop(YARN模式需要环境)
三台Linux机器
Flink安装包flink-1.10.0-bin-scala_2.11.tgz 官方下载地址
Flink Hadoop依赖包flink-shaded(yarn-session.sh运行需要,如果官方没有提供对应Hadoop和Flink版本依赖包,需自行下载shaded源码编译打包) 官方下载地址
Local模式
Local Cluster模式是开箱即用的,直接解压安装包,然后启动即可。
//解压
tar -zxvf flink-1.10.0-bin-scala_2.11.tgz
//进入bin目录运行启动脚本
./start-cluster.sh
打开浏览器输入http://IP:8081,查看WEBUI监控界面。
Standalone模式
Stanalone CLuster是一种独立的集群模式,集群运行不需要依赖外部系统,完全自己独立进行管理。
三台机器部署情况:
| 节点 | 服务 |
|---|---|
| 节点一 | master |
| 节点二 | worker |
| 节点三 | worker |
| 节点四 | worker |
1、解压安装包
tar -zxvf flink-1.10.0-bin-scala_2.11.tgz
2、修改配置文件,conf目录下
flink-conf.yaml文件
## jobmanager节点地址,也是master节点地址
jobmanager.rpc.address: tod1
其他使用默认配置,其中有一些HA高可用、容错、安全、HistoryServer相关配置,按需进行配置即可,HistoryServer需单独运行启动脚本来启动服务。
修改masters文件
vim masters
//添加
tod1:8081
修改slaves文件
vim slaves
//添加
tod2
tod3
3、将安装目录复制到另外两台节点
scp -r flink-1.10.0 tod2:/home/hadmin/
scp -r flink-1.10.0 tod3:/home/hadmin/
4、配置环境变量,修改/etc/profile
export FLINK_HOME=/home/hadmin/flink-1.10.0
export PATH=$PATH:$FLINK_HOME/bin
//使配置文件生效
source /etc/profile
5、启动集群
start-cluster.sh
6、打开浏览器输入http://IP:8081

YARN模式
YARN模式是使用YARN做为Flink运行平台,JobManager、TaskManager、用户提交的应用程序都运行在YARN上。
hadoop环境变量引入,在用户环境变量中添加

1、修改flink-conf.yaml配置文件
# 关于容错配置,checkpoints存储方式
state.backend: filesystem
state.checkpoints.dir: hdfs://ns/flink-checkpoints
state.savepoints.dir: hdfs://ns/flink-savepoints
2、将flink-shaded-hadoop-2-uber-2.7.5-10.0.jar上传到flink的lib目录
3、将Flink以服务形式长期运行在YARN,Job运行完也不会关闭,但是这种方式启动时资源已经指定,多个Job运行共享资源
yarn-session.sh -d -s 4 -jm 512m -tm 512m
此时在YARN监控页面启动了一个Container,里面运行Flink程序
然后用户使用flink工具脚本提交Job即可
flink run example.jar
4、Per/Single Job模式,一个Job代表一个flink集群,多个Job互不影响。直接用Flink提交到YARN,提交一个任务就生成一个Job
flink run -m yarn-cluster -yjm 1024 -ytm 2048 -ys 2 -p 3 example.jar
HA高可用
注意:此处有个坑,Standalone模式的HA必须依赖于共享存储文件系统,因为要保证JobManager的元数据信息对所有节点共享,由high-availability.storageDir参数指定JobManager存储位置。如果指定本地目录,即使启动2个JobManager也不会实现高可用,因为元数据信息不能共享。可选代替方案,使用NFS挂载远程机器JobManager信息存储目录。
HA就是JobManager高可用,在Standalone Cluster模式下,实现HA依赖于外部软件Zookeeper,因此需要添加Zookeeper相关配置
1、修改配置文件masters
tod1:8081
tod2:8081
2、修改flink-conf.yaml
high-availability: zookeeper
high-availability.storageDir: hdfs://tod1/flink/ha/
high-availability.zookeeper.quorum: tod1:2181,tod2:2181,tod3:2181
high-availability.zookeeper.path.root: /flink
# JobManager元数据存储位置,必须使用共享分布式文件系统,要保证所有节点能访问该目录
high-availability.storageDir: hdfs:///flink/recovery
3、将配置文件复制到另外两台节点,启动集群
start-clushter.sh
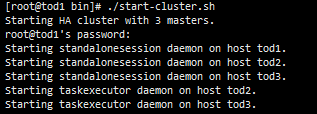
注意:此时监控页面的IP地址需要指定Zookeeper的leader节点IP
YARN模式下的HA需要注意一点,官方给出建议,必须要增加以下两项配置:
YARN配置,修改yarn-site.xml
//master(JobManager)失败重启的最大尝试次数
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>
The maximum number of application master execution attempts.
</description>
</property>
Flink配置,修改flink-conf.yaml
//用户提交作业失败时,重新执行次数
yarn.application-attempts: 4
设置Task在所有节点平均分配
注意:此参数仅作用于Standalone Cluster模式,如果不设置此参数,可能所有task会集中在某一个节点执行,不会在所有TM之间平均分配。
官方参数说明:cluster.evenly-spread-out-slots :默认 false。Enable the slot spread out allocation strategy. This strategy tries to spread out the slots evenly across all available TaskExecutors.
cluster.evenly-spread-out-slots: true
水平一般,能力有限,大数据小学生一枚。文章主要用于个人学习和总结,如果能给他人带来帮助,纯属意外。














 3824
3824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









