









引言
假设肿瘤发生的概率和肿瘤大小及发现时间这2个特征有关,用欧拉距离计算样本1和样本2之间的距离,可以看出距离被发现时间这一特征所主导,这显然是不合理的,如果不对数据进行合理处理,最终计算的结果很有可能是有偏差的,不能反映出每一个特征的重要程度,因此要对数据进行归一化处理。所谓归一化处理就是将所有数据映射到同一尺度中。

最值归一化
最简单的方式称之为最值归一化,即将所有数据映射到0-1之间
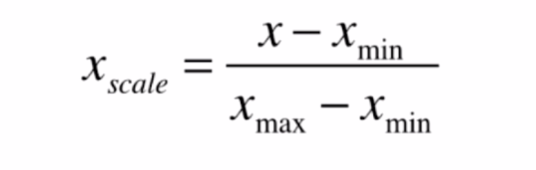
这种方法适用于分布有明显边界的数据,例如,考试成绩,但这个方法受outline影响较大,例如工资普遍在1W以内,如果某个样本点为100W,这时大部分样本点都集中在0-0.01之间,这种情况映射的结果就不够好。
因此就引出了另一种方法,均值方差归一化。
均值方差归一化
均值方差归一化是吧所有数据映射到均值为0,方差为1的分布中。同时适用于分布没有明显边界以及有明显边界的数据。
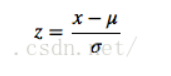
其中,μ、σ分别为原始数据集的均值和方法。
x_data = (x_data-np.mena(x_data))/np.std(x_data)
















 2276
2276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











