







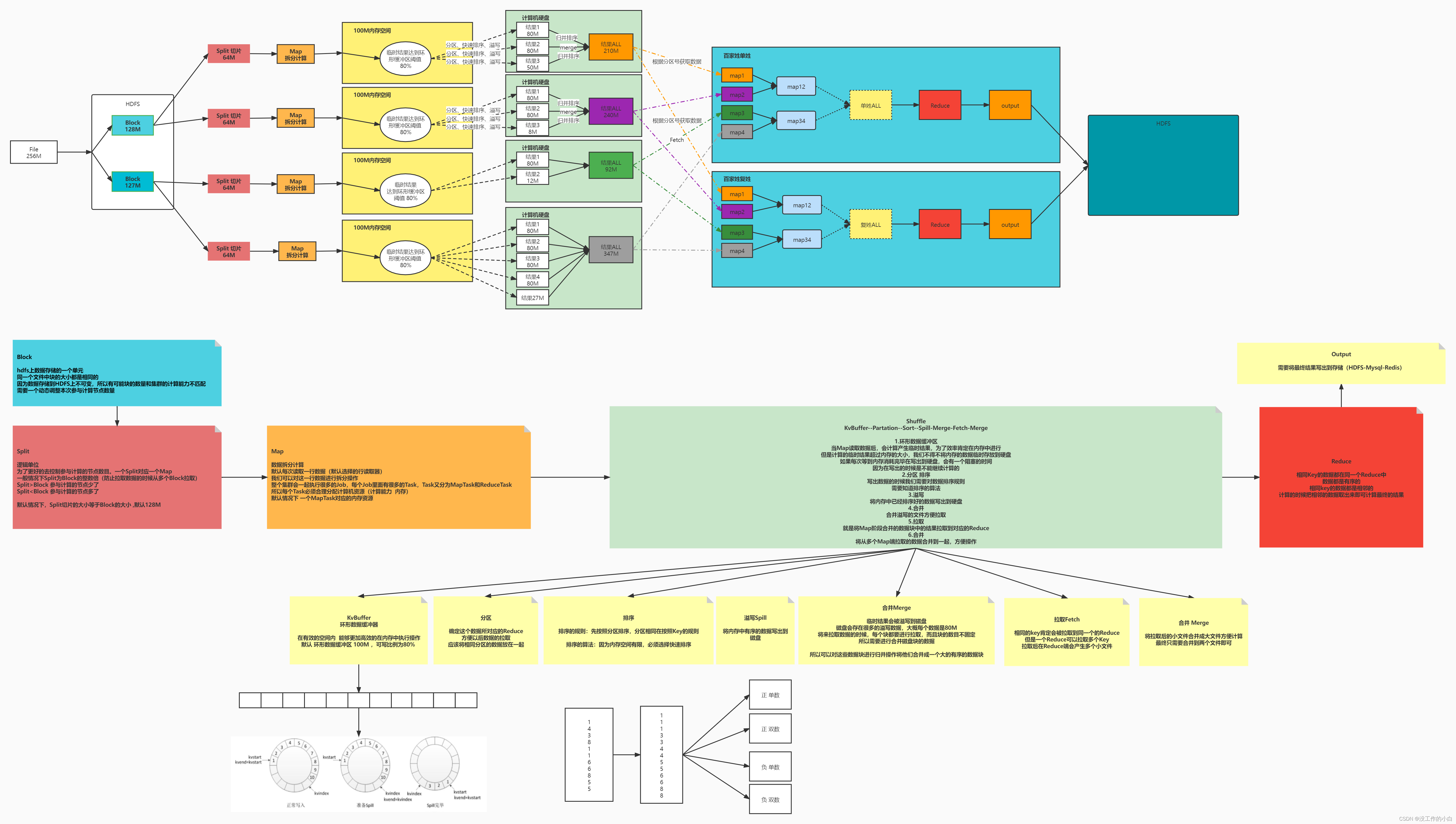
MapReduce设计理念
MapReduce是什么
map --> 映射【key value】
reduce —> 归纳
MapReduce是必须建立在HDFS之上的大数据离线计算架构,计算数据有一定的延时,如果数据量太小,使用MapReduce反而不合适【因为延迟性,计算流程复杂】,使用分布式计算【大文件切分为多个小文件,多个节点同时参与运算】
MapReduce中名词
- 原始数据
- 因为MapReduce是基于HDFS文件系统的,所以原始数据是指上传存放在HDFS上的数据块
- 数据块Block
- 一个大的文件存放在HDFS上,默认会被切分为一个一个大小为128M的文件块
- 切片Split
- 切片是一个虚拟的逻辑概念
- 因为在MapReduce计算流程中,使用Split切片控制处理的map计算节点数量【切片和计算节点数量相同】,切片大小默认和Block数据块大小一样
- 注意:!如果需要处理的数据是129M,按照切片正常是需要两个Map去处理,但是为了节省空间,会进行判断,如果最后需要处理的数据【1.1的问题】大小,小于切片大小的1.1倍数,就直接使用一个Map进行处理
- MapTask
- MpaTask是一个过程,一个切片就有一个MapTesk去处理实例
- 环形缓冲区
- 在map处理过程中,需要占用内存空间计算,但是map占用内存比较小,为了使用小部分内存计算大量数据,提高计算效率,输出内容不影响计算的功能,就使用算法,将占用的内存,作为一个【环形状】,当内存使用到80%的时候,就将之前的数据写出,在写出的时候,可以使用剩下的20%内存继续计算,在计算完后,刚刚的80%也已经处理完毕,可以继续使用了
- 分区
- 分区个数和Reduce个数是相等的
- 如果不指定分区方式,默认采用hash取余的方式进行分区
- 可以制定分区的方式,在编写代码中需要制定分区对应代码
- 溢写
- 就是在环形缓冲区中使用到80%的时候,就会将数据写出硬盘中暂存,这个步骤就是溢写
- 排序sort
- 对于溢写的数据进行排序
- 默认使用快速排序,这样每次溢写出来的小文件都是有序的
- 合并Merge
- 对于溢写出来的有序小文件,合并成为一个大文件,方便后续的拉取
- 拉取
- 是指map处理完毕数据后,Reduce获取的过程
- 写出Output
- 每个reduce将自己计算的最终数据写出到hdfs中
MapReduce计算数据流程
- 1:文件在硬盘中是被切分为多个block块保存的,然后会调用Split[【切片】把数据切分【默认情况下,分片的大小就是HDFS的blockSize】
- 2: 切分后的文件交由Map【内存中计算,map是将数据拆分的阶段】,数据会进行分区,使用快排 排序,然后溢写到硬盘中
- 3: 硬盘中会得到map处理多次溢写出来的结果,在讲多个结果 使用 归并排序 合并为一个大的结果
- 4:多个map溢写出来的结果,所以在硬盘中也对应地方存储, 在最后这些多个存储的数据会根据分区在拆分出来对应的结果
- 5:多个结果会两两合并,得到最总数据 归纳所有数据,最后数据到hdfs保存














 166
166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









