







在看Point NN分类网络时候,作者在使用Modelnet40数据集的时候下载的是这个数据集:'https://shapenet.cs.stanford.edu/media/modelnet40_ply_hdf5_2048.zip',而不是这个链接下载的数据:'https://shapenet.cs.stanford.edu/media/modelnet40_normal_resampled.zip'(这个是在训练Pointnet++时候下载的)
所以modelnet40_normal_resampled的结构是这样的(左图),modelnet40_ply_hdf5_2048的结构是这样的(右图)。
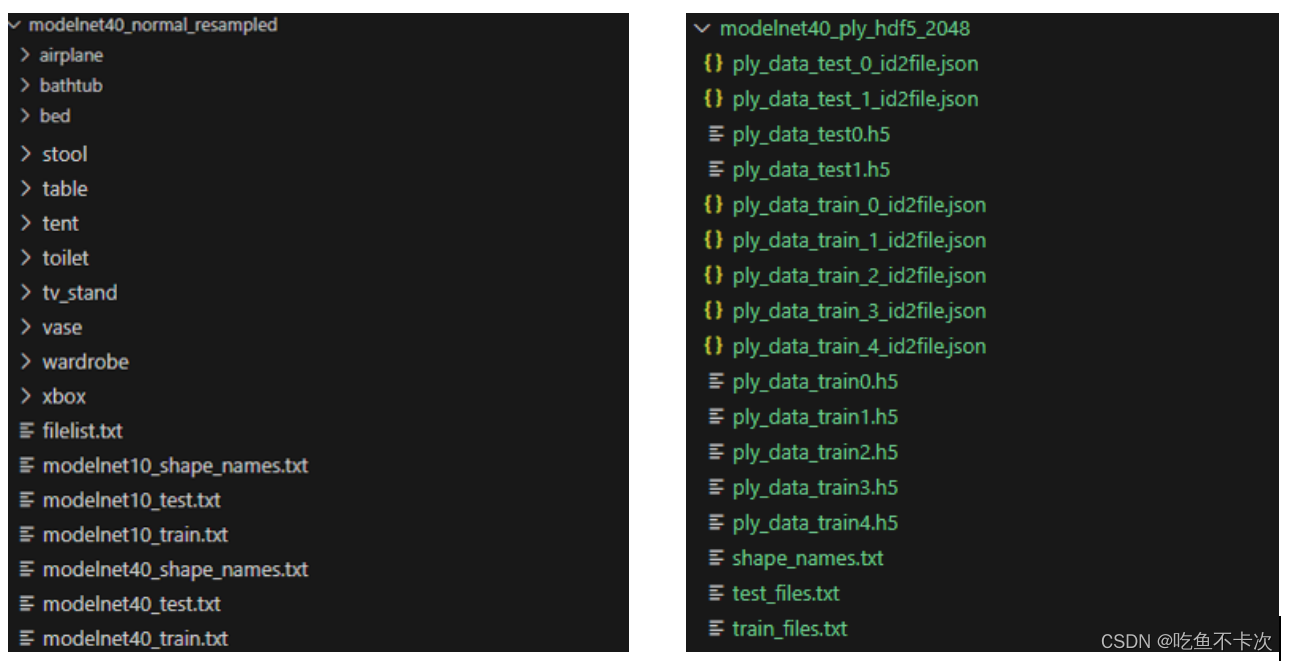
左图是以.txt格式对点云的坐标进行存储的,并且是按照一个类别一个文件进行存储的(图中只显示了部分),并且通过modelnet40_train.txt和modelnet40_test.txt来划分训练集和测试集。右图则是以.h5格式进行存储,并且将训练集分为了5个.h5格式文件,通过train_files.txt和test_files.txt来划分训练集和测试集。两个最大的区别就是存储点云数据的格式不同,也正是因为如此,两者所消耗的存储空间差别很大,以.txt格式存储的点云数据集大小为6.48 GB,而以.h5格式存储的点云数据集大小为415 MB,下面就来了解一下.h5格式是什么。
.h5格式存储的是HDF5(Hierarchical Data Format version 5) 文件,是一种用于存储和组织大量数据的文件格式和库,HDF5 支持数据压缩,以减小文件大小,这对于大型数据集的高效存储非常有用。
关于如何读取.h5文件,代码如下:这里读取到的data 的shape为(2048,2048,3),说明这里的.h5文件已经把所有的点云拼在一起了,已经是符合输入网络的一种shape了,并且每个点云包含2048个点,每个点有3个特征,分别是xyz。而label的shape为(2048, 1),代表每一个点云的类别。
import h5py
file_path=r"data/modelnet40_ply_hdf5_2048/ply_data_train0.h5"
f = h5py.File(file_path,'r')
data = f['data'][:].astype('float32')#shape: (2048, 2048, 3) shape: (1648, 2048, 3)
label = f['label'][:].astype('int64')#shape: (2048, 1) shape: (1648, 1)
f.close()关于如何存储.h5文件,代码如下:基本思想就是先把txt数据转换成numpy格式,然后通过f.create_dataset来生成对应的数据集。
import h5py
import numpy as np
import json
from tqdm import tqdm
with open(r"modelnet40_ply_hdf5_2048/ply_data_train_0_id2file.json") as f:
data=json.load(f)
path_root=r"data/modelnet40_normal_resampled"
class_name=["airplane","bathtub","bed","bench","bookshelf","bottle","bowl","car","chair","cone","cup","curtain","desk","door","dresser","flower_pot","glass_box","guitar","keyboard","lamp","laptop","mantel","monitor","night_stand","person","piano","plant","radio","range_hood","sink","sofa","stairs","stool","table","tent","toilet","tv_stand","vase","wardrobe","xbox"
]
train_list=[os.path.join(path_root,d.split(".ply")[0]+".txt") for d in data]
sorted(train_list)
point_list=[]
label_list=[]
for file in tqdm(train_list):
point=np.loadtxt(file,delimiter=',')[:2048,:]
label=np.array(class_name.index(file.split("/")[-2]),dtype=np.int32)
point_list.append(point)
label_list.append(label)
point_list=np.stack(point_list, axis=0)
label_list=np.stack(label_list, axis=0)
with h5py.File("deom.h5","w") as f:
f.create_dataset('data',data=point_list)
f.create_dataset('label',data=label_list)

















 824
824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











