







 本文详细介绍了YOLOv8系列网络在目标检测、实例分割、关键点检测和旋转目标检测四个任务中的网络结构。YOLOv8的网络分为主干网络、Neck层和Head层,其中主干网络包含CBS、C2f和SPPF模块。Head层采用解耦方式生成预测特征图。对于实例分割,Head层额外生成了用于Mask的特征图。关键点检测任务中,Head层增加了预测人体17个关键点的特征图。旋转目标检测任务则在Head层增加了预测旋转角度的特征图。
本文详细介绍了YOLOv8系列网络在目标检测、实例分割、关键点检测和旋转目标检测四个任务中的网络结构。YOLOv8的网络分为主干网络、Neck层和Head层,其中主干网络包含CBS、C2f和SPPF模块。Head层采用解耦方式生成预测特征图。对于实例分割,Head层额外生成了用于Mask的特征图。关键点检测任务中,Head层增加了预测人体17个关键点的特征图。旋转目标检测任务则在Head层增加了预测旋转角度的特征图。
将按照YOLOv8目标检测任务、实例分割任务、关键点检测任务以及旋转目标检测任务的顺序来介绍,主要内容也是在目标检测任务中介绍,其他任务也只是Head层不相同。
如果不想看文字,可以直接观看视频,det/seg/pose/obb网络结构介绍已经全部更新完:
Bilibili视频讲解:YOLOv8网络结构介绍_哔哩哔哩_bilibili
1.YOLOv8_det网络结构
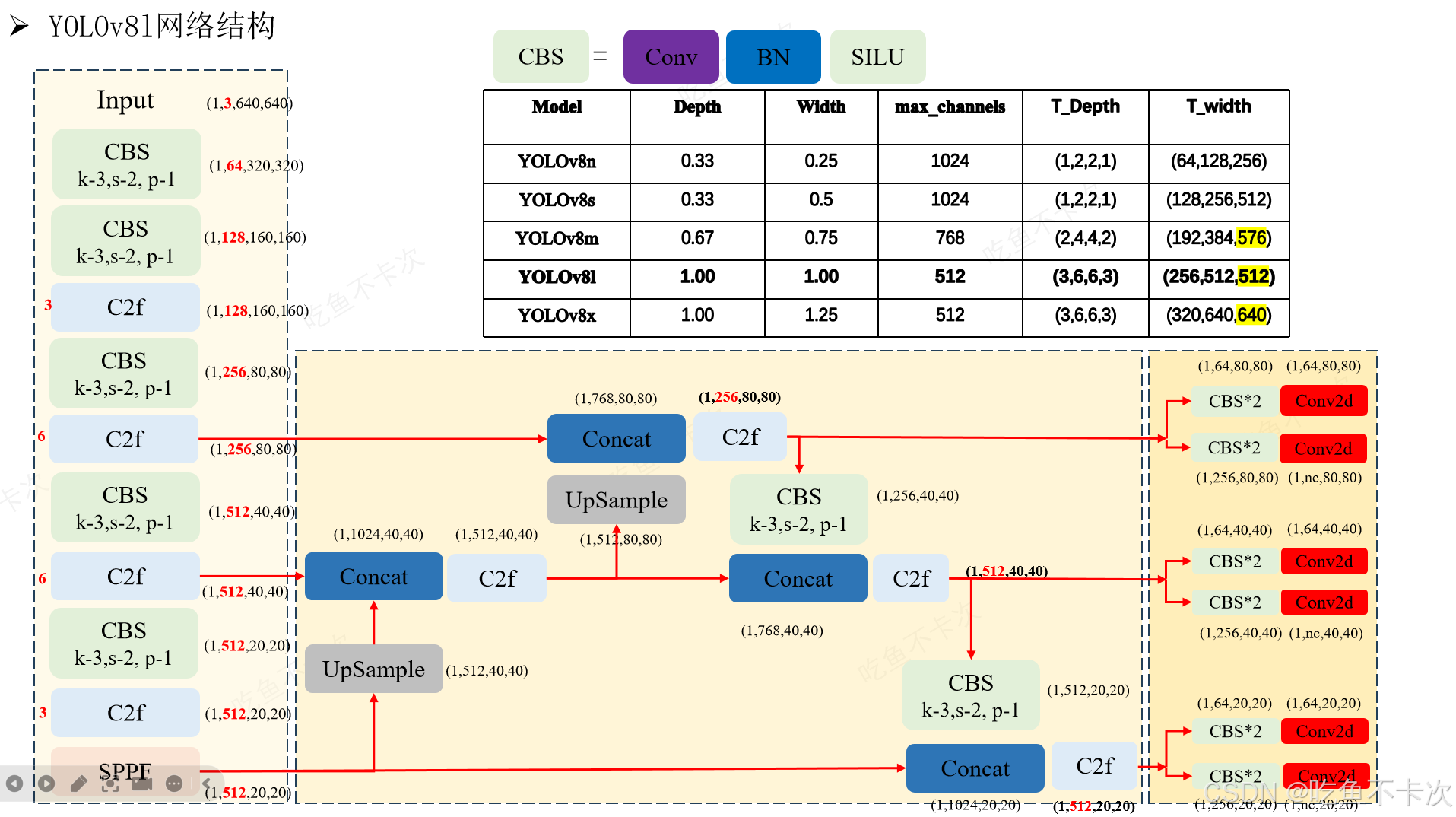
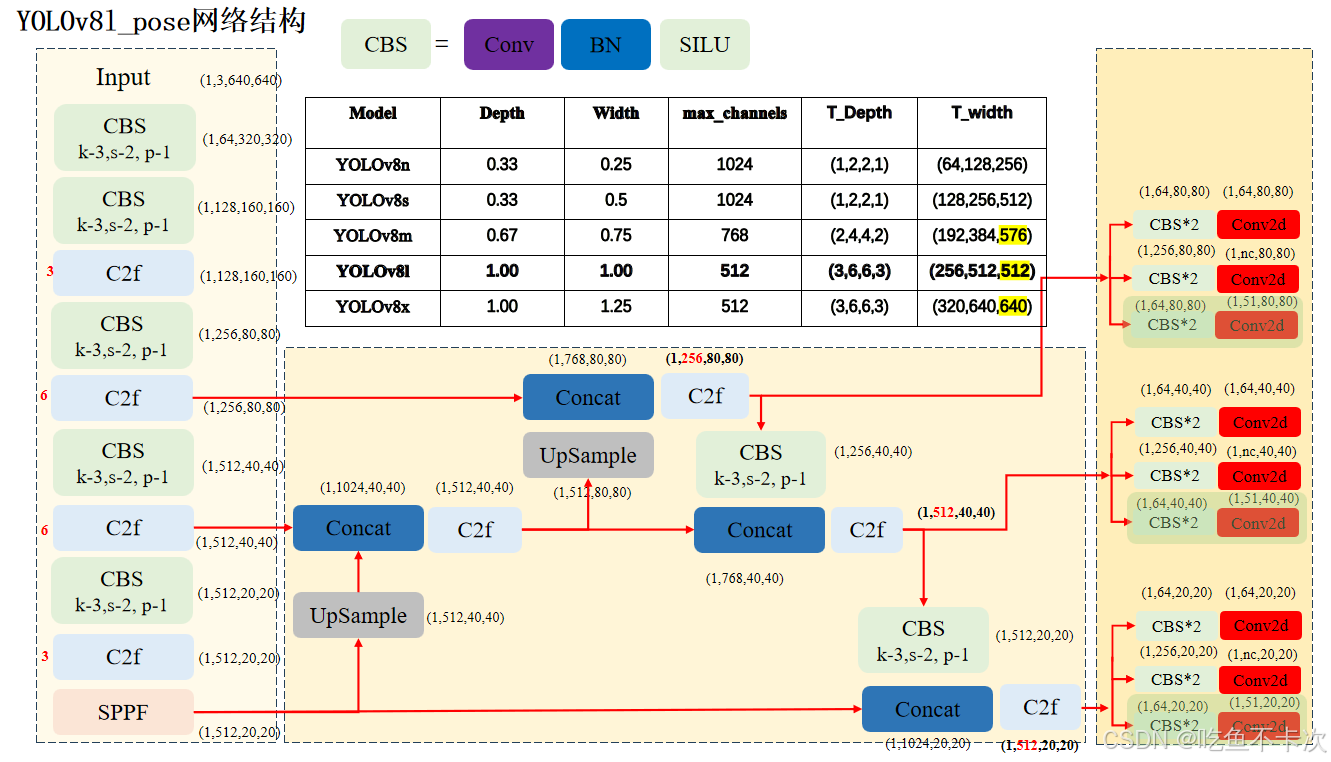
首先,YOLOv8网络分成了三部分,分别是Backbone网络、Neck层网络还有一个是Head层网络,下面将按照这三个顺序来介绍下YOLOv8的网络结构,先以YOLOv8l的网络架构来说明。
1.1Backbone网络
主干网络(Backbone) 是对输入图片进行特征提取的,特征提取的过程通常伴随着特征图分辨率的下降以及通道数的上升,输入图像分辨率从640×640变成了20×20,输入通道数从3变成了512。
主干网络主要由CBS模块、C2f模块和SPPF模块构成:
CBS模块 表示Conv、BN和SILU构成的卷积组,其中最重要的参数有K、S和P,K表示kernel size即卷积核大小,这里的卷积核大小都是3x3;S表示Stride表示步长,一般步长为2,都会伴随着分辨率的下降;P表示Padding,一般也是用来计算输出分辨率大小的。主干网络中一共有5个CBS模块,因此会进行5次下采样。
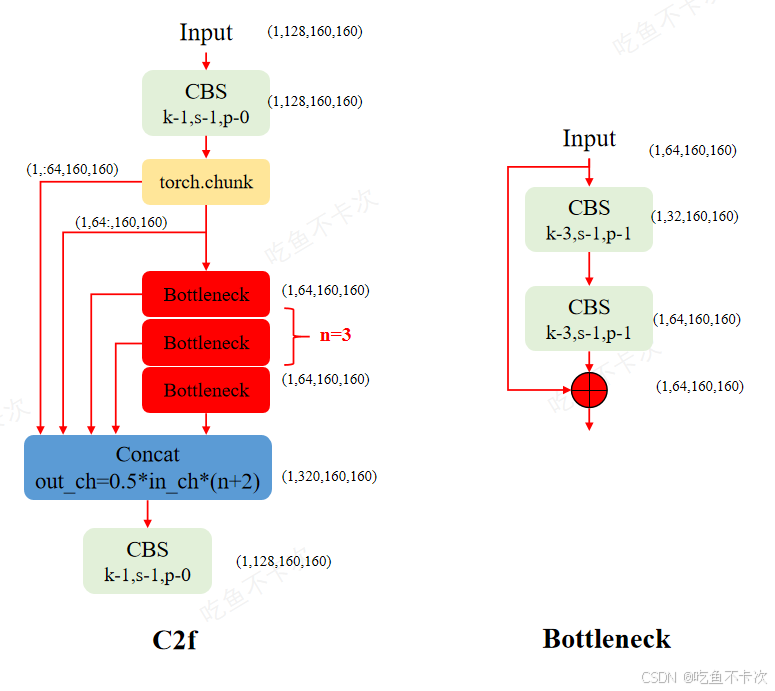
C2f模块是设计用来深度提取特征的一个模块,其输出特征图和输入特征图的大小保持不变,但是在他内部会有多个分支,如下图所示,torch.chunk将(1,128,160,160)特征图分成了两部分,前半部分,即(1,:64,160,160)输出为第一个分支;后半部分,即(1,32:,160,160)除了作为输出的第二个分支外,还会经过n个bottleneck模块,每经过一个Bottleneck都会输出一个通道为64的特征图,所以最后concat得到的通道数为0.5×in_ch×(n+2),其中in_ch表示输入的通道数,即128,n为bottleneck的个数,当n为3时,concat得到的通道数为320。
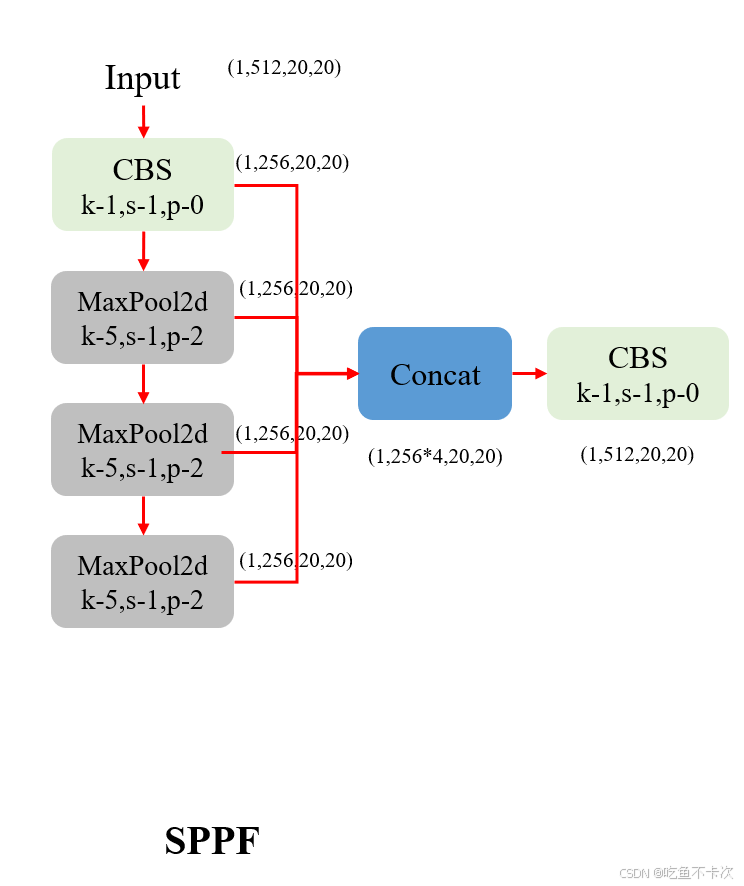
SPPF模块这里就看一下就行了,和YOLOv5中的是一样的,并且也是输出特征图和输入特征图的大小保持不变,详细可以看下图的shape表示。
1.2Neck网络
Neck层网络是用来对主干网络输出的特征图进行特征融合的,也就是把主干网络输出的三个不同尺度的特征图(80×80、40×40以及20×20)通过上采样的方式进行Concat,经过两次上采样后输出第一个特征图(80×80)给Head层,然后通过CBS模块对特征图进行下采样输出剩下两个特征图(40×40和20×20)给Head层。详细可以看YOLOv8网络结构图。
这里需要注意主干网络中的C2f和Neck中的C2f主要有两点不相同:
第一,BackBone层的c2f层的输入和输出通道数不变,而Neck层的c2f层的输出和输出通道数改变,输出通道数为主干网络输出同一尺度特征图的通道数。
第二,BackBone层的c2f模块的bottleneck含有残差分支,而Neck层的c2f模块的bottleneck不含残差分支,并且每个c2f只堆叠了一个bottleneck。
1.3Head网络
Head层网络是根据类别数来设计生成特定的特征图,YOLOv8采用的是解耦头的方式来生成,解耦的意思就是说分别生成用来预测CLs和Box的特征图,比如输入尺度为(1,256,80,80)特征图,Box分支会通过两个CBS模块以及一个Cov2d生成(1,64,80,80)的特征图,Cls分支会通过两个CBS模块以及一个Cov2d生成(1,nc,80,80)的特征图,nc表示预测的类别。
经过Head层会生成3个预测Box的特征图(1,64,80,80)、(1,64,40,40)和(1,64,20,20);以及生成3个预测CLs的特征图(1,nc,80,80)、(1,nc,40,40)和(1,nc,20,20)。详细可以看YOLOv8网络结构图。
Box分支由2个卷积组和1个卷积构成,前两个卷积组的通道数需要符合max((16,ch[0]//4,self.reg_max4)),其中ch[0]表示80x80尺度特征图的通道数,在YOLOv8l中为256,另外self.reg_max4=64,计算得到max(16,256/4,64)=64,因此三个尺度Box分支头中前两个卷积组的通道数均是64,最后一个卷积层的通道数也是64. Cls分支同样也是由2个卷积组和1个卷积层构成,前两个卷积组的通道数需要符合max(ch[0],min(self.nc,100)),其中ch[0]表示8080尺度特征图的通道数,self.nc表示预测的类别,在YOLOv8l中ch[0]为256,假设self.nc为80,计算得到max(256,min(80,100))=256,因此三个尺度的Cls分支头中前两个卷积组的通道数均是256,最后一个卷积层的通道数固定是self.nc.
具体可以参考下图。

1.4网络Depth设计
最后再来对比一下n/s/m/l/x的Backbone和neck层的差异,n是最小的版本,x是最大的版本,目标检测、实例分割、关键点检测和旋转目标检测的主干网络都是一样的。
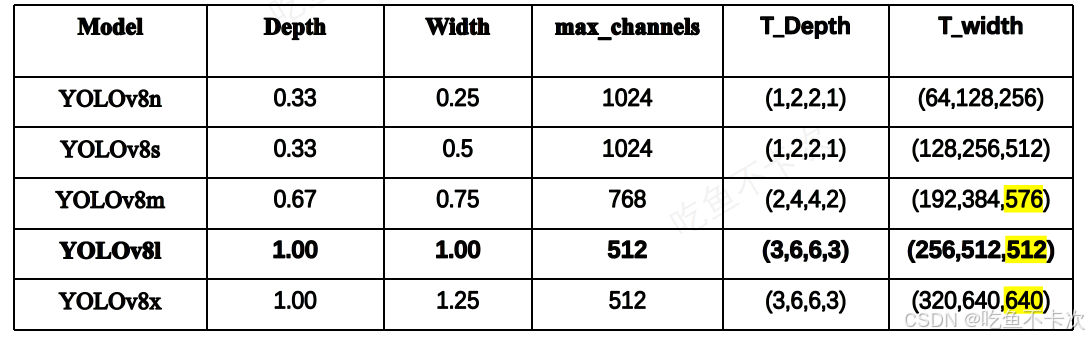
先来看主干网络中的C2f层的Bottleneck个数:
n:[1,2,2,1],s:[1,2,2,1],m:[2,4,4,2],l:[3,6,6,3],x:[3,6,6,3]
通过Depth来控制其大小,比如YOLOv8n的Depth为0.33,那么以[3,6,6,3]为标准的话,n的个数就应该为[1,2,2,1],同理m的个数为[2,4,4,2]。
1.5网络Width设计
另外还有主干网络中每一层的输出特征图通道数:
n:[3,16,32,32,64,64,128,128,256,256]
s:[3,32,64,64,128,128,256,256,512,512]
m:[3,48,96,96,192,192,384,384,576,576]
l:[3,64,128,128,256,256,512,512,512,512]
x:[3,80,160,160,320,320,640,640,640,640]
通过Width和max_channels来控制输出特征图的最大值,比如YOLOv8-L的Width为1,max_channel为512,输出的三个特征图中通道数最大不能超过max_channels*Width(代码中的公式是min(c2,max_channels)*width,化简得到就可以得到max_channels *Width),即512×1.00=512;YOLOv8x中最大不能超过512×1.25=640;YOLOv8m中最大不能超过768×0.75=576。


YOLOv8目标检测网络的更多内容可以看下面的文章:
YOLOv8预测流程-原理解析[目标检测理论篇]![]() https://blog.csdn.net/weixin_45144684/article/details/138455119YOLOv8训练流程-原理解析[目标检测理论篇]
https://blog.csdn.net/weixin_45144684/article/details/138455119YOLOv8训练流程-原理解析[目标检测理论篇]![]() https://blog.csdn.net/weixin_45144684/article/details/138589894
https://blog.csdn.net/weixin_45144684/article/details/138589894
2.YOLOv8_seg网络结构
实例分割的Backbone、Neck网络和目标检测的完全一致,只是Head层会有区别,区别有两点:
第一点, 三个尺度的特征图在head层除了生成3个预测Box的特征图(1,64,80,80)、(1,64,40,40)和(1,64,20,20);以及3个预测CLs的特征图(1,nc,80,80)、(1,nc,40,40)和(1,nc,20,20);还会另外生成3个通道数均为32用来当成Mask系数的特征图mask_coefficients(1,32,80,80)、(1,32,40,40)和(1,32,20,20);如下图中浅紫色分支所示。
第二点 ,通过80×80尺度的特征图生成一个大小为(1,32,80,80)Prototype Mask特征图,作为原生分割的特征图。如下图中深紫色分支所示。
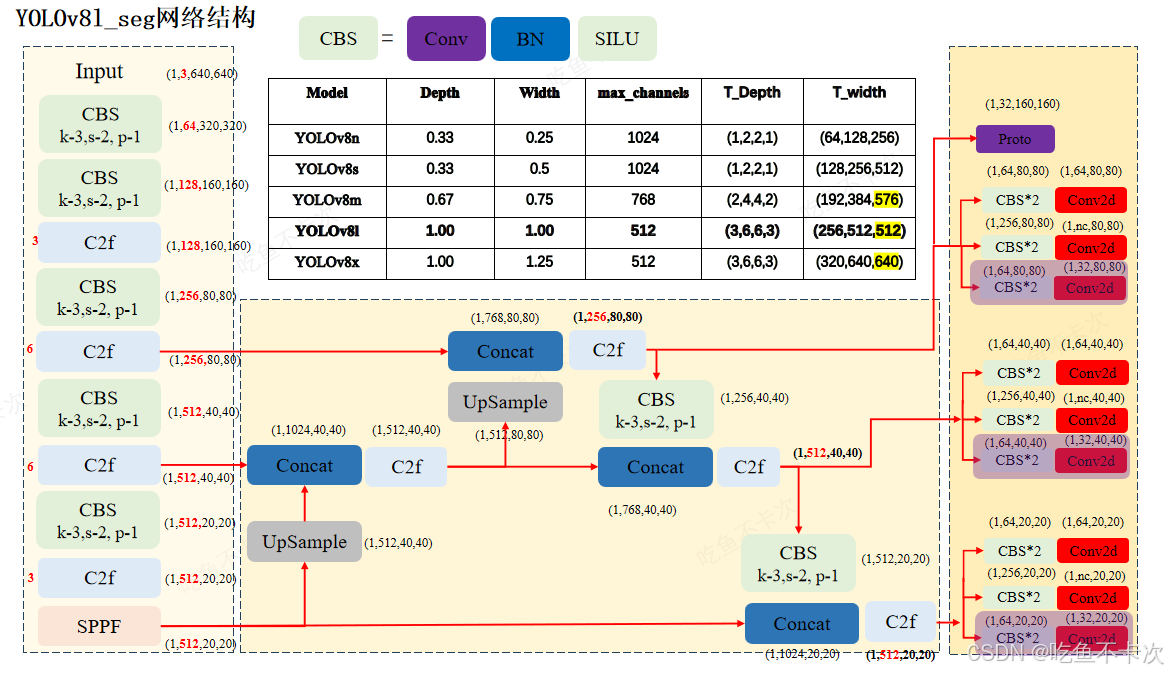
2.1mask_coefficients分支
先来了解下mask_coefficients分支的具体结构,如下图蓝色框区域内所示。该分支是由2个卷积组和1个卷积层构成,前两个卷积组的通道数需要符合 max(ch[0] // 4, self.nm),ch[0]表示80*80尺度特征图的通道数,self.nm为固定值32。
由图可知,YOLOv8L中80 * 80尺度特征图的通道数是256,因此计算得到该分支头中前两个卷积层的通道数均是64,最后一个卷积输出通道数是32,这个是和Proto分支的通道数是保持一致的。
下图右边还展示了其他几个版本(n/s/m/x)的头部网络输出通道数变化,可以根据上述公式进行验证一下。
这里需要注意一点,网络输出的三个尺度特征图,mask_coefficients分支的三个尺度下的通道数变化是一样的,比如L版本网络中的80*80尺度下计算得到输出通道数分别为64、64和32,那么40 *40 和20 *20尺度下三个卷积输出的通道数也是64、64和32。同样的前面在说目标检测网络的时候也提到过,Box分支和Cls分支也是如此。

2.2Prototype分支
生成Prototype Mask特征图的Prototype分支结构如下所示,结构很简单,主要是通过一个上采样层,将特征图由80×80分辨率上采样得到160×160尺度。那么为什么要选择80×80尺度特征图,而不选择其他尺度呢?是因为80×80相比其他尺度特征图更接近原图尺寸,上采样到160×160像素损失会更少,因而会有更好的分割效果。
下图是不同网络各卷积层的张量变化情况,由下可知,最后输出的特征图shape都是一样的,即CBS2的输出结果均为(1,32,160,160),接下来就是CBS1和CBS2的通道数计算,需要满足min(args[2],max_channels)* width,但是可以直接化简为256* width,为什么呢?因为args[2]是yolov8-seg.yaml文件中一个固定值,为256,而n/s/m/l/x这五个版本的max_channel均大于256,所以可以直接进行化简。比如在YOLOv8L-seg中,前两个卷积组的输出通道数为256* 1=256,同理可以使用n/s/m/x等版本去验证。
最后看一下UpSample,这是通过nn.ConvTranspose2d来实现的。
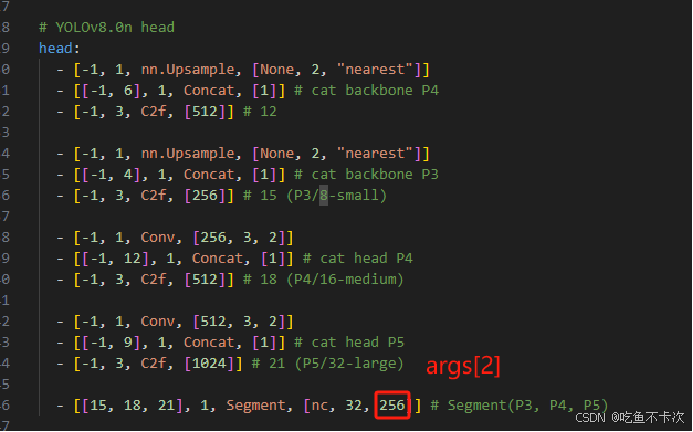
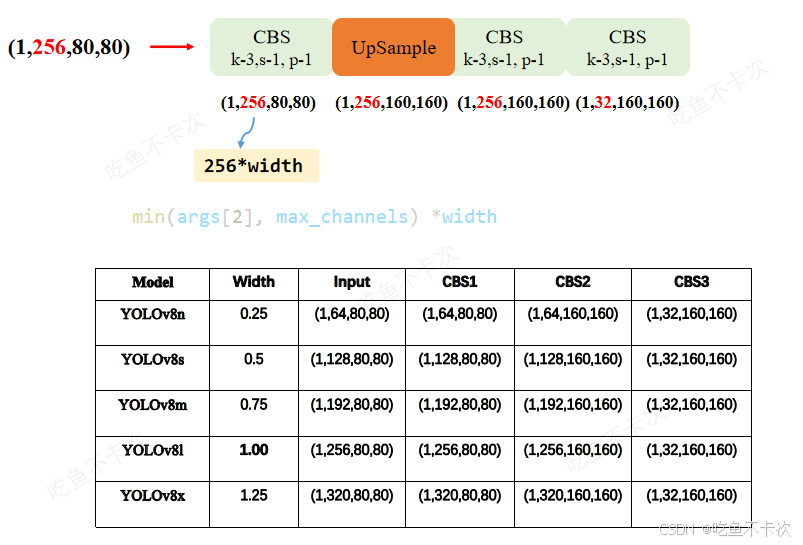
2.3Seg实现基本原理
YOLOv8_seg采用的是YOLACT的方法,详细可以看一下这篇文章轻松掌握 MMDetection 中常用算法(八):YOLACT - 知乎 (zhihu.com),我在这里大概说一下YOLACT实例分割的原理:
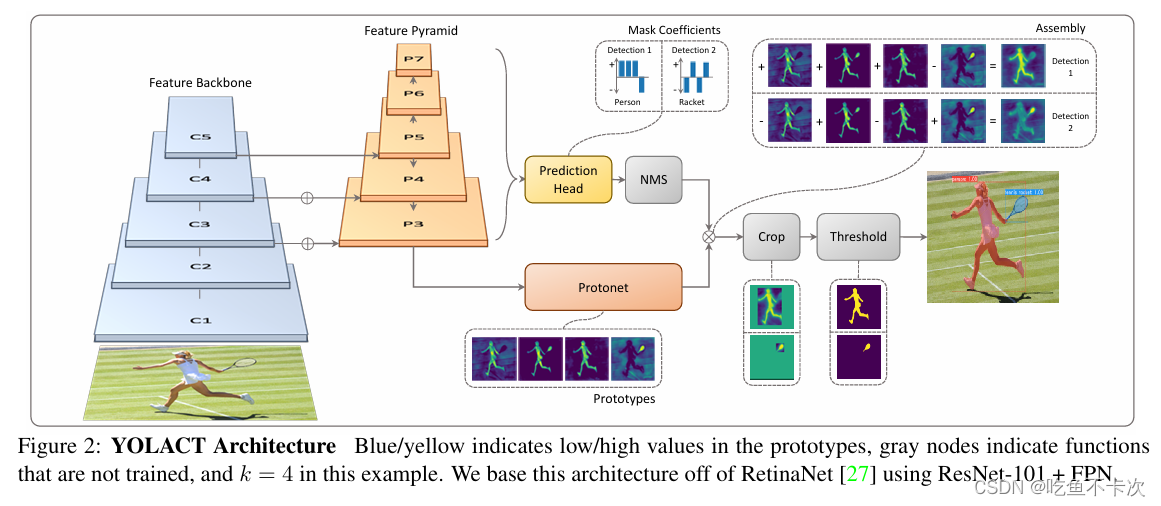
上面是YOLACT的网络结构图,YOLOv8也是按照上面的原理来实现的,具体如下:
(1)主干网络(Feature Backabone)以及特征图金字塔(Feature Pyramid)都是用来提取特征的,然后将P3(即分辨率最大的特征图)作为Protonet的输入,Prototypes是Protonet的输出,作为网络预测的一个原生掩码;
(2)预测头除了用来生成预测框的位置、类别,还会生成Mask ceofficients作为Prototypes的掩码系数;
(3)经过NMS筛选出两个目标,Detection1和Detection2,接下来将借助原生掩码和掩码系数生成这两个目标的预测掩码,然后对预测掩码根据预测框进行Crop裁剪,再利用Threshold进行二值化得到最后的结果。
那么怎么使用Mask ceofficients和Prototypes mask呢?
可以简单得去理解:
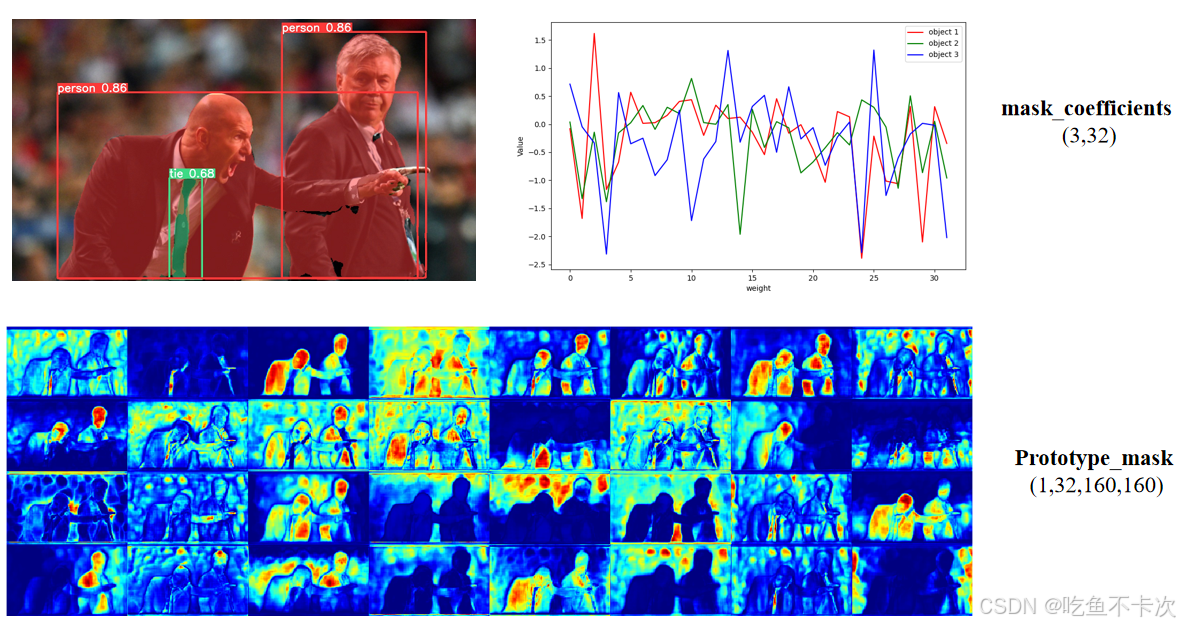
(1)prototype_mask可以看成是32张颜色有深有浅的图片,并且每张图片的分辨率为160 * 160,如下所示。
(2)mask_coefficients可以看成32个数字,对应着32张图片的权重,如下所示。
(3)32个权重和对应的32张图片相乘再相加,得到的就是预测结果;
(4)如果一张图片有多个目标,比如下图中有3个目标,那么3个目标就会对应着3组32个权重,最后得到3个预测结果。
如果对YOLOv8_seg网络感兴趣,更多内容可以关注下面的文章:
YOLOv8_seg预测流程-原理解析[实例分割理论篇]_yolov8seg模型推理数据怎么解析-CSDN博客![]() https://blog.csdn.net/weixin_45144684/article/details/138756878?spm=1001.2014.3001.5502YOLOv8_seg训练流程-原理解析[实例分割理论篇]_yolov8 seg-CSDN博客
https://blog.csdn.net/weixin_45144684/article/details/138756878?spm=1001.2014.3001.5502YOLOv8_seg训练流程-原理解析[实例分割理论篇]_yolov8 seg-CSDN博客![]() https://blog.csdn.net/weixin_45144684/article/details/138824034?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22138824034%22%2C%22source%22%3A%22weixin_45144684%22%7D
https://blog.csdn.net/weixin_45144684/article/details/138824034?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22138824034%22%2C%22source%22%3A%22weixin_45144684%22%7D
3.YOLOv8_pose网络结构
关键点检测的Backbone、Neck网络和目标检测的完全一致,只是Head层会有区别,区别有一点:
三个尺度的特征图在head层除了生成3个预测Box的特征图(1,64,80,80)、(1,64,40,40)和(1,64,20,20);以及3个预测CLs的特征图 (1,nc,80,80)、(1,nc,40,40)和(1,nc,20,20);还会另外生成3个用来预测key_point关键点的特征图,以人体17个关键点为例,该分支生成三个尺度特征图分别为(1,51,80,80)、(1,51,40,40)和(1,51,20,20),用来预测人体17个关键点位置和置信度的特征图 ,即网络结构图中浅绿色Head部分。
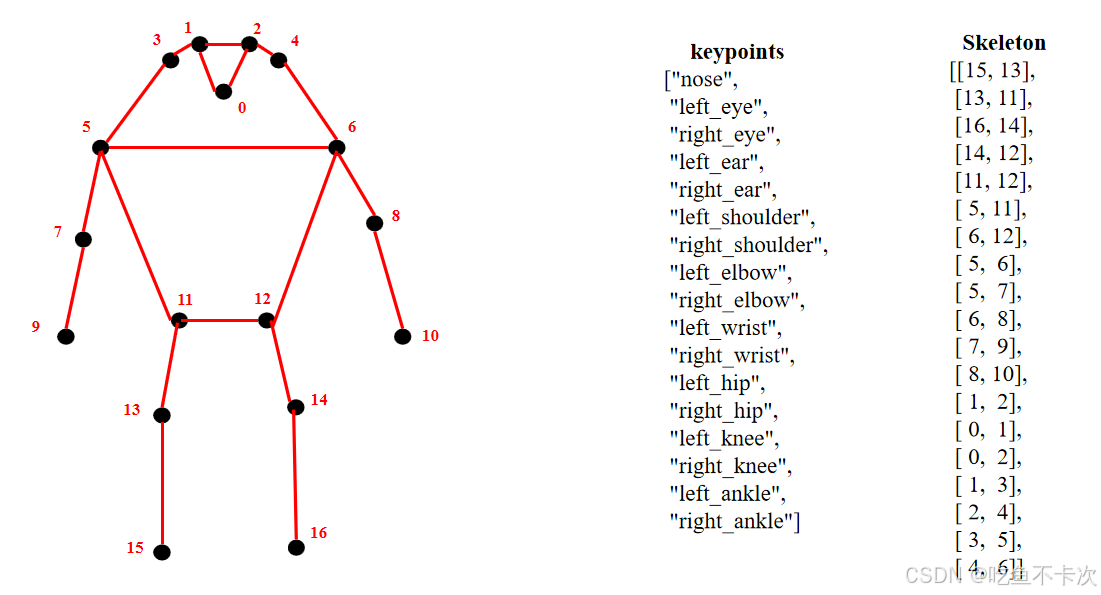
3.1人体关键点
其中51表示17个关键点的位置(x和y坐标值)和置信度(conf),即17*3=51。人体17个关键点keypoints、关键点间的连接线Skeleton如下所示,比如noise会和左眼、右眼有连接,所以skeleton中会包含(0,1)和(0,2)。
3.2key_point分支
key_point分支的具体结构,如下图蓝色框区域内所示。该分支是由2个卷积组和1个卷积层构成,前两个卷积组的通道数需要符合max(ch[0] // 4, self.nk),ch[0]表示80*80尺度特征图的通道数,self.nk为关键点数量 * 3,比如前面说的人体关键点个数为17,那么key_point分支最后输出的通道数为17 * 3 =51。
由图可知,YOLOv8L中80 * 80尺度特征图的通道数是256,因此计算得到该分支头中前两个卷积层的通道数均是64,还是以人体关键点为例的话最后一个卷积输出通道数是51。
下图右边还展示了其他几个版本(n/s/m/x)的头部网络输出通道数变化,可以根据上述公式进行验证一下,通过公式计算,可以看到如果n/s/m版本前两个卷积组输出的通道数均为51。

3.3KeyPoint实现基本原理
YOLOv8关键点检测网络借鉴于YOLO PoseMaji_YOLO-Pose_Enhancing_YOLO_for_Multi_Person_Pose_Estimation_Using_Object,
大概聊聊其基本思想:
(1)一个目标检测框对应一组关键点。
(2)关键点可能会由于截断或者遮挡而无法预测出来,导致关键点漏检。
(3)关键点也有可能预测在目标检测框外。


YOLOv8_pose网络的实现也基本满足上面的原理,如果对YOLOv8_Pose网络感兴趣,更多内容可以看下面的文章:
YOLOv8_pose预测流程-原理解析[关键点检测理论篇]_yolov8pose原理-CSDN博客![]() https://blog.csdn.net/weixin_45144684/article/details/139077739?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22139077739%22%2C%22source%22%3A%22weixin_45144684%22%7DYOLOv8_pose训练流程-原理解析[关键点检测理论篇]_yolov8关节点含义-CSDN博客
https://blog.csdn.net/weixin_45144684/article/details/139077739?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22139077739%22%2C%22source%22%3A%22weixin_45144684%22%7DYOLOv8_pose训练流程-原理解析[关键点检测理论篇]_yolov8关节点含义-CSDN博客![]() https://blog.csdn.net/weixin_45144684/article/details/139196865?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22139196865%22%2C%22source%22%3A%22weixin_45144684%22%7D
https://blog.csdn.net/weixin_45144684/article/details/139196865?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22139196865%22%2C%22source%22%3A%22weixin_45144684%22%7D
4.YOLOv8_obb网络结构
旋转目标检测的Backbone、Neck网络和目标检测的完全一致,只是Head层会有区别,区别有一点:
三个尺度的特征图在head层除了生成3个预测Box的特征图(1,64,80,80)、(1,64,40,40)和(1,64,20,20);以及3个预测CLs的特征图(1,nc,80,80)、(1,nc,40,40)和(1,nc,20,20);还会另外生成3个通道数均为1,用来预测旋转角度的特征图Angle(1,1,80,80)、(1,1,40,40)和(1,1,20,20),Angle分支为下图中浅蓝色部分。
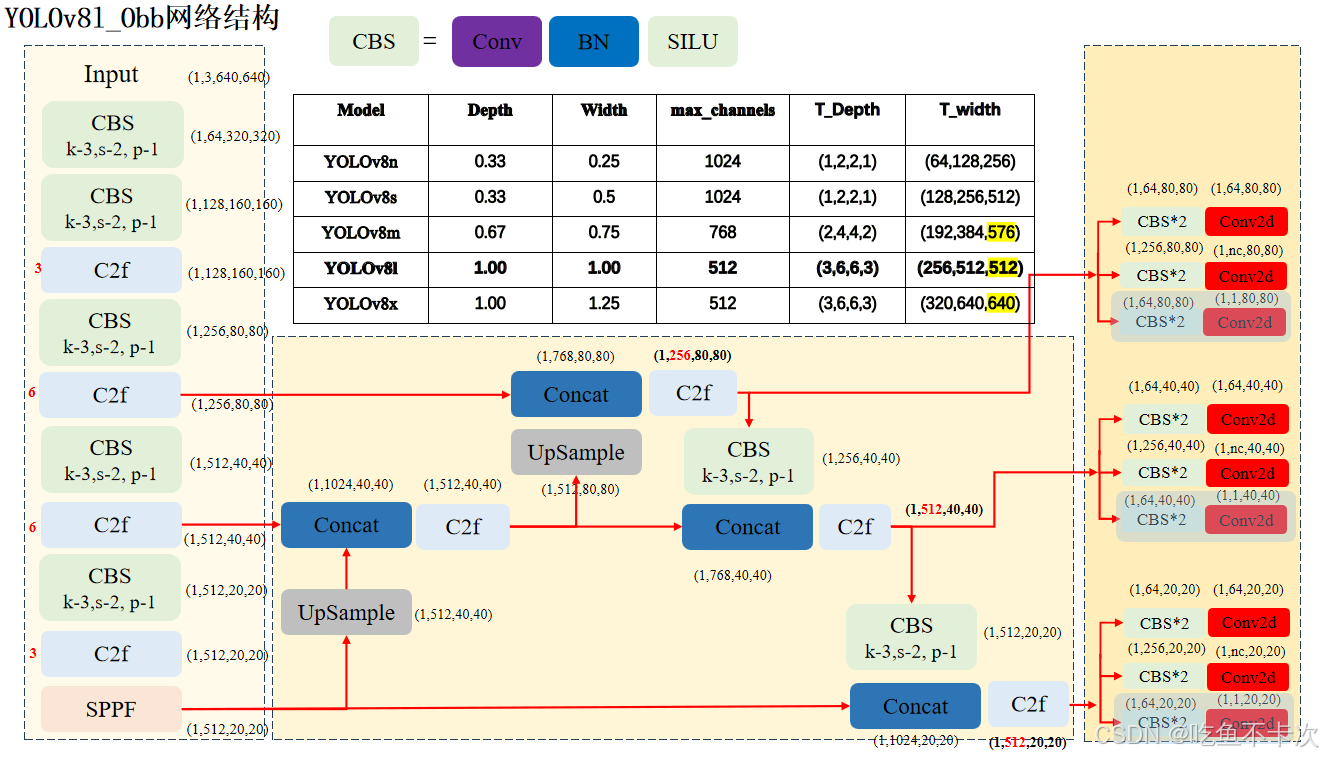
4.1Angel分支
先来了解下Angel分支的具体结构,如下图蓝色框区域内所示。该分支是由2个卷积组和1个卷积层构成,前两个卷积组的通道数需要符合max(ch[0] // 4, self.ne),ch[0]表示80*80尺度特征图的通道数,self.ne表示number of extra parameters,默认设置为1,这里是指只使用一个维度来预测角度(还有其他旋转框预测算法会使用三个维度的值来预测角度)。
由图可知,YOLOv8L中80 * 80尺度特征图的通道数是256,因此计算得到该分支头中前两个卷积层的通道数均是64,最后一个卷积输出通道数是1。
下图右边还展示了其他几个版本(n/s/m/x)的头部网络输出通道数变化,可以根据上述公式进行验证一下。

网络结构上还是很好理解的,只是在正常目标检测网络上添加了角度这个维度,并且这个角度是基于目标检测框中心进行旋转的角度。
YOLOv8_obb网络的更多内容可以看下面的文章:
高斯分布、GBB和Prob IoU[旋转目标检测理论篇]_probiou原理-CSDN博客![]() https://blog.csdn.net/weixin_45144684/article/details/139280640?spm=1001.2014.3001.5501YOLOv8_obb训练流程-原理解析[旋转目标检测理论篇]_yolov8obb 顶点顺序-CSDN博客
https://blog.csdn.net/weixin_45144684/article/details/139280640?spm=1001.2014.3001.5501YOLOv8_obb训练流程-原理解析[旋转目标检测理论篇]_yolov8obb 顶点顺序-CSDN博客![]() https://blog.csdn.net/weixin_45144684/article/details/139399075YOLOv8_obb预测流程-原理解析[旋转目标检测理论篇]_yolov8obb旋转框原理-CSDN博客
https://blog.csdn.net/weixin_45144684/article/details/139399075YOLOv8_obb预测流程-原理解析[旋转目标检测理论篇]_yolov8obb旋转框原理-CSDN博客![]() https://blog.csdn.net/weixin_45144684/article/details/139399445
https://blog.csdn.net/weixin_45144684/article/details/139399445


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











