






数据处理-THUCNews
简要来说文本分类为什么要进行数据处理:
- 有些数据中的样本特征来源和尺度不同,不同的机器学习对于数据特征尺度的敏感程度不一样,但不同的尺度输入特征会增加训练难度,我们一般使用归一化的方法将数据特征转换为相同尺度。
- 有一些数据集中含有一些词频很高但是对于确定其文本类别无关的词语,比如“的”、“和”、“中”、“得"等,他们还拉低了关键词的贡献度;而有些数据集没进行清洗的话,会带有“@”、”&"等特殊符号,占用大量篇幅,需要去除。
- 我们的中文文字、英文单词不能直接输入模型进行训练,要表示成计算机可以处理的特征向量、tensor才能进行数学运算(有些机器学习算法(比如决策树)不需要向量形式的特征)。
- 机器学习是通过“学习”样本规律,拟合数据的真实分布或者逼近一个函数,在文本分类中,对数据进行预处理,即用向量化、相似度计算等方法更好地帮助模型去认识、学习到样本规律。
- 数据一般要经过数据集划分,分为训练集、和测试集(有时需要开发集),训练集中的样本用来训练模型,测试集中的样本用来检验模型的好坏。
在此部分需要完成的功能为:
读取数据、提取文本类别、数据预处理(分词、one-hot、数据集划分)、提取 tfidf 特征参数、迭代器(将数据分批传入模型)
使用到的工具:scikit-learn、jieba、numpy
处理架构:
data_process.py 为 数据的预处理文件
- read_data():读取数据
- save_categories():提取分类目录,转换成{类别1|类别2…}表示,写入本地;
- pre_data():数据预处理,去停词、分词、编码(Bag of Word、One Hot)
- get_tfidf():提取 tfidf 特征
- provide_data():提供数据,保存数据向量
- batch_iter():为模型的训练准备经过shuffle的批次的数据。
读取数据
首先读取数据data、停词表stopwprds,utf-8格式。
def read_data(self):
'''
读取数据data、停词表stopwprds,utf-8格式,
'''
stopwords = list()
with open(self.dataset_path,encoding = 'uft-8') as f1:
data = f1.readlines()
with open(self.dataset_path,encoding = 'uft-8') as f1:
temp_stopwords = f2.readlines()
for word in tem_stopwords:
stopwords.append(word[:-1])
return data,stopwords
局部数据集:

数据预处理
接下来,建立词典,将词典中词语的词向量单独存入文件。这些词应该具有一定的重要性,我们通过词频排序,选择前N个词。但在这之前,应该去停用词
def pre_data(self,data,stopwords,test_size = 0.2):
'''
数据预处理
'''
label_list = list()
text_list = list()
##先切分类别和数据,再分词
for line in data:
label,text = line.split('\t',1)
seg_text = [word for word in jieba.cut(text) if word not in stopwords]
text_list.append(' ',join(seg_text))
label_list.append(label)
## 文字 → 数字
encoder_nums = LabelEncoder()
label_nums = encoder_num.fit_transform(label_list)
categories = list(encoder_nums.classes_)
##存储类别
self.save_categories(categories,config.categories_save_path)
label_nums = np.array([label_nums]).T
##数字 → OneHot 编码
encoder_one_hot = OneHotEncoder()
label_one_hot = encoder_one_hot.fit_transform(label_nums)
label_one_hot = label_one_hot.toarray()
return model_selection.train_test_split(test_list, label_one_hot,test_size = test_size, random_state = 1024)
classes 分成十个类别:

类别数字编码:
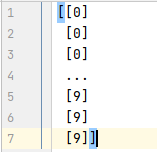
类别OneHot编码:
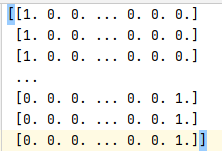
TF-IDF
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。这里直接调用的 sklearn 中的TfidfVectorizer ,若想深入了解该算法,请看 TF-IDF算法详解与应用。
def get_tfidf(self,X_train,X_test):
vectorizer = TfidfVectorizer(min_df = 100)
vectorizer.fit_transform(X_train)
X_train_vec = vectorizer.transform(X_train)
X_test_vec = vectorizer.transform(X_test)
return X_train_vec, X_test_vec,vectorizer
提供数据
提供处理后的数据集
def provide_data(self):
'''提供数据'''
data, stopwords = self.read_data()
## 1、提取bag of word参数
## 2、提取tf-idf特征参数
X_train,Xtest,y_train,y_test = self.pre_data(data,stopwords,test_size = 0.2)
X_train_vec, X_test_vec,vectorizer = self.get_tfidf(X_train,X_test)
return X_train_vec,X_test_vec,y_train,y_test
文本类别写入本地
将文本的类别写入本地的函数,由 pre_data 函数 调用。在这里传入的数据data应该是数据集的类别classes
def save_categories(self, data, save_path):
"""
将文本的类别写到本地
"""
with open(save_path, 'w', encoding='utf-8') as f:
f.write('|'.join(data))
迭代器
将数据划为num_batch批,初始化并随机索引序列,每次 shuffle 批量数据集。
def batch_iter(self,x,y,batch_size = 64):
'''迭代器,将数据分批传给模型'''
data_len = len(x)
num_batch = int((data_len-1)/batch_size)+1
indices = np.random.permutation(np.arange(data_len))
x_shuffle = x[indices]
y_shuffle = y[indices]
for i in range(num_batch):
start_id = i*batch_size
end_id = min((i+1)*batch_size,data_len)
yield x_shuffle[start_id:end_id],y_shuffle[start_id:end_id]
Reference:https://github.com/duguiming111/tensorflow-logistics-regression、数学之美 吴军















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









