






@[TOC]1.tensorflow自带的数据集
1、列举tensorflow. 自带的4个数据集(除minist),并了解该数据集的内容。
1、CIFAR10小图像
2、CIFAR100小图像
3、IMDB电影影评情感分类
4、路透社新闻专线主题分类
5、手写数字MNIST数据集
6、时尚元素MNIST数据库
7、波斯顿房价回归数据集
2、我们将1、2、3、4、5号索引位置分别表示电视、冰箱、洗衣机、微波炉、消毒柜,写出冰箱和洗衣机的one-hot编码。
import tensorflow as tf
y = tf.constant([0,1,2,3,4]) # 数字编码
y = tf.one_hot(y, depth=5) # one-hot 编码
print(y)
3、回归问题常使用哪个损失函数?分类问题常使用哪个损失函数?
回归问题:

分类问题:

4、解释下列公式的意义,并写出第2个公式的tensorflow表达式。
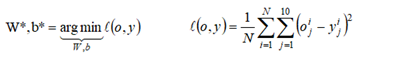
1.
找到最优的W,B使得o,y差距最小,argmin的用法
tf.reduce_sun(tf.square(out-y))/x.shape[0]
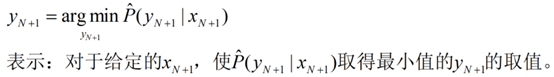

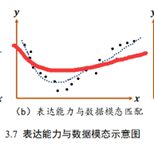
5、解释欠拟合和过拟合现象
**过拟合(OverFititing):**太过贴近于训练数据的特征了,在训练集上表现非常优秀,近乎完美的预测/区分了所有的数据,但是在新的测试集上却表现平平。
**解决过拟合的方法:**降低数据量,正则化(L1,L2),Dropout(把其中的一些神经元去掉只用部分神经元去构建神经网络)
你用追前女友的方式追新女孩,你就陷入过拟合
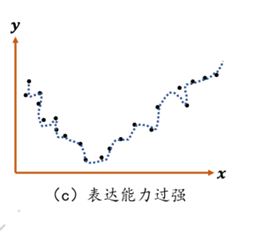
**欠拟合(UnderFitting):**样本不够或者算法不精确,测试样本特性没有学到,不具泛化性,拿到新样本后没有办法去准确的判断
你连第一个女孩都没追到你就是欠拟合
解决欠拟合的方法:增加训练数据,优化算法
6、使用tensorflow.keras.Sequential创建一个含有3层全连接网络,3层网络输出维度分别为128、64和10,前两层使用 ReLU激活函数。写出网络结构创建代码。如果输入4张16*16的图片,则网络中包含多少个训练参数。
model = keras.Sequential([ # 3 个非线性层的嵌套模型
layers.Dense(256, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(10)])(1616128+128 +
12864+64 +6710+10)

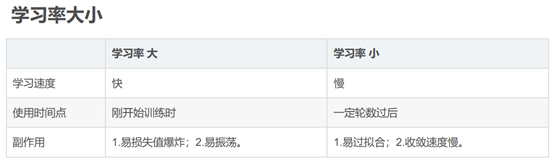
7、解释学习率在深度学习网络训练时的用途。学习率的大小对训练过程有何影响。
学习速率是指导我们该如何通过损失函数的梯度调整网络权重的超参数。学习率越低,损失函数的变化速度就越慢。虽然使用低学习率可以确保我们不会错过任何局部极小值,但也意味着我们将花费更长的时间来进行收敛,特别是在被困在高原区域的情况下。
学习率:
学习率太大,会跳过最低点,可能不收敛
学习率太小收敛速度过慢
8、给出SGD优化器的使用方法。
optimizer =optimizers.SGD(learning_rate=0.001)实例化优化器9、修改main.py,输出训练损失函数折线图。
import numpy as np
import matplotlib
from matplotlib import pyplot as plt
matplotlib.rcParams['font.family'] = ['STKaiti']
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets
(x, y), (x_val, y_val) = datasets.mnist.load_data() #获取mnist数据
x = tf.convert_to_tensor(x, dtype=tf.float32) / 255.#数值类型转换
y = tf.convert_to_tensor(y, dtype=tf.int32)
y = tf.one_hot(y, depth=10)
print(x.shape, y.shape)
train_dataset = tf.data.Dataset.from_tensor_slices((x, y))
train_dataset = train_dataset.batch(200)
model = keras.Sequential([
layers.Dense(512, activation='relu'),
layers.Dense(256, activation='relu'),
layers.Dense(10)])
# tf.keras.optimizers.SGD
optimizer = optimizers.SGD(learning_rate=0.001)
def train_epoch(epoch):#迭代
# Step4.loop
for step, (x, y) in enumerate(train_dataset):
with tf.GradientTape() as tape:
# [b, 28, 28] => [b, 784]
x = tf.reshape(x, (-1, 28*28))
out = model(x)
loss = tf.reduce_sum(tf.square(out - y)) / x.shape[0]
# Step3. optimize and update w1, w2, w3, b1, b2, b3
grads = tape.gradient(loss, model.trainable_variables)#梯度
# w' = w - lr * grad
optimizer.apply_gradients(zip(grads, model.trainable_variables))#SGD优化器对超参数进行修正
if step % 100 == 0:
print(epoch, step, 'loss:', loss.numpy())
return loss
def run(y):
x = range(0, np.size(y))
plt.plot(x, y, 'o-')
plt.xlabel('epoches')
plt.ylabel("Train loss")
plt.ylim([0, 1])#限制Y轴的刻度
plt.savefig('loss.svg')
def train():
loss_list = []
for epoch in range(30):
loss=train_epoch(epoch)
loss_list.append(loss)
run(loss_list)
if __name__ == '__main__':
train()




10、使用Sequential、Dense和SGD优化器实现第2章2.3节回归问题实例。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import numpy as np
import matplotlib
from matplotlib import pyplot as plt
matplotlib.rcParams['font.family'] = ['STKaiti']
matplotlib.rcParams['font.size']=30
matplotlib.rcParams['figure.titlesize']=30
matplotlib.rcParams['figure.figsize']=[9,7]
matplotlib.rcParams['axes.unicode_minus']=False
model = keras.Sequential([layers.Dense(1,)])
# tf.keras.optimizers.SGD
optimizer = optimizers.Adam(learning_rate=0.001)
points=np.genfromtxt("data.csv",delimiter=",")
# (x, y), (x_val, y_val) = datasets.mnist.load_data()
x = tf.constant(points[:,0], dtype=tf.float32)
y = tf.constant(points[:,1], dtype=tf.float32)
# y = tf.convert(y, dtype=tf.int32)
# y = tf.one_hot(y, depth=10)
x=tf.reshape(x,[x.shape[0],1])
y=tf.reshape(y,[y.shape[0],1])
# print(x.shape, y.shape)
# train_dataset = tf.data.Dataset.from_tensor_slices((x, y))
# train_dataset = train_dataset.batch(200)
def train_epoch(epoch):#迭代
# Step4.loop
with tf.GradientTape() as tape:
# [b, 28, 28] => [b, 784]
# x = tf.reshape(x, (-1, 28*28))
# Step1. compute output
# [b, 784] => [b, 10]
out = model(x)
# Step2. compute loss
loss = tf.reduce_sum(tf.square(out - y)) / x.shape[0]
# x = [i for i in range(0, 1000)]
# plt.plot(x, loss, 'C1', label="均方误差")
# plt.ylim([0, 6000])
# plt.xlabel('迭代次数')
# plt.ylabel('损失值')
# plt.legend()
# plt.savefig('lose.svg')
# Step3. optimize and update w1, w2, w3, b1, b2, b3
grads = tape.gradient(loss, model.trainable_variables)#梯度
# w' = w - lr * grad
optimizer.apply_gradients(zip(grads, model.trainable_variables))#SGD优化器对超参数进行修正
# if step % 100 == 0:
print(epoch, 'loss:', loss.numpy())
return loss
def run(y):
epochs=[i for i in range(1000)]
# x = range(0, np.size(y))
plt.plot(epochs, y,color='C2',label='loss_list')
plt.xlabel('次数')
plt.ylabel("损失值")
plt.legend()
# plt.ylim([0, 1])#限制Y轴的刻度
plt.savefig('LR-loss.svg')
plt.show()
def train():
# num_iterations=1000
loss_list = []
for epoch in range(1000):
loss=train_epoch(epoch)
loss_list.append(loss)
run(loss_list)
if __name__ == '__main__':
train()



Units:输出节点个数
















 4824
4824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









