







1、创建scrapy项目
一般使用 scrapy startproject firstblood(项目名称) 创建。创建完以后的结果如图:

2、爬虫文件的创建
创建完项目,我们可以看到一个spiders的文件夹,爬虫文件都是创建在这个文件夹下,创建爬虫文件一般也使用命令scrapy genspider first www.xxx.com,创建完成以后的基本页面如图,我们一般将allowed_domains = ['www.xxx.com']这行代码注释掉,原因是因为,我们可能爬取的文件并不是以www.xxx.com为地址的,可能会解析不到想要的数据

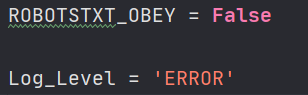
除此之外,我们还将settiing.py文件中的ROBOTSTXT_OBEY = False改为False
当我们运行文件时,使用scrapy crawl first运行爬虫文件,我们也可以使用scrapy crawl first --nolog过滤掉日志信息,当我们不想看日志文件,也可以在setting.py文件中加入Log_Level = 'ERROR'















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









