1、通过f12分析到每个详情页的图片地址在li标签内

url = 'https://pic.netbian.com/'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
res = requests.get(url=url, headers=headers)
res.encoding = 'gbk'
# 创建tree对象
tree = etree.HTML(res.text)
# 通过xpath找到对应标签
li_list = tree.xpath('//div[@class="slist"]/ul[@class="clearfix"]/li/a/@href')
print(li_list)

2、拼接完整url
# 拼接url获取详情页完整地址
for base_url in li_list:
# print(base_url)
detail_url = url + base_url
print(detail_url)

3、获取详情页的图片的地址
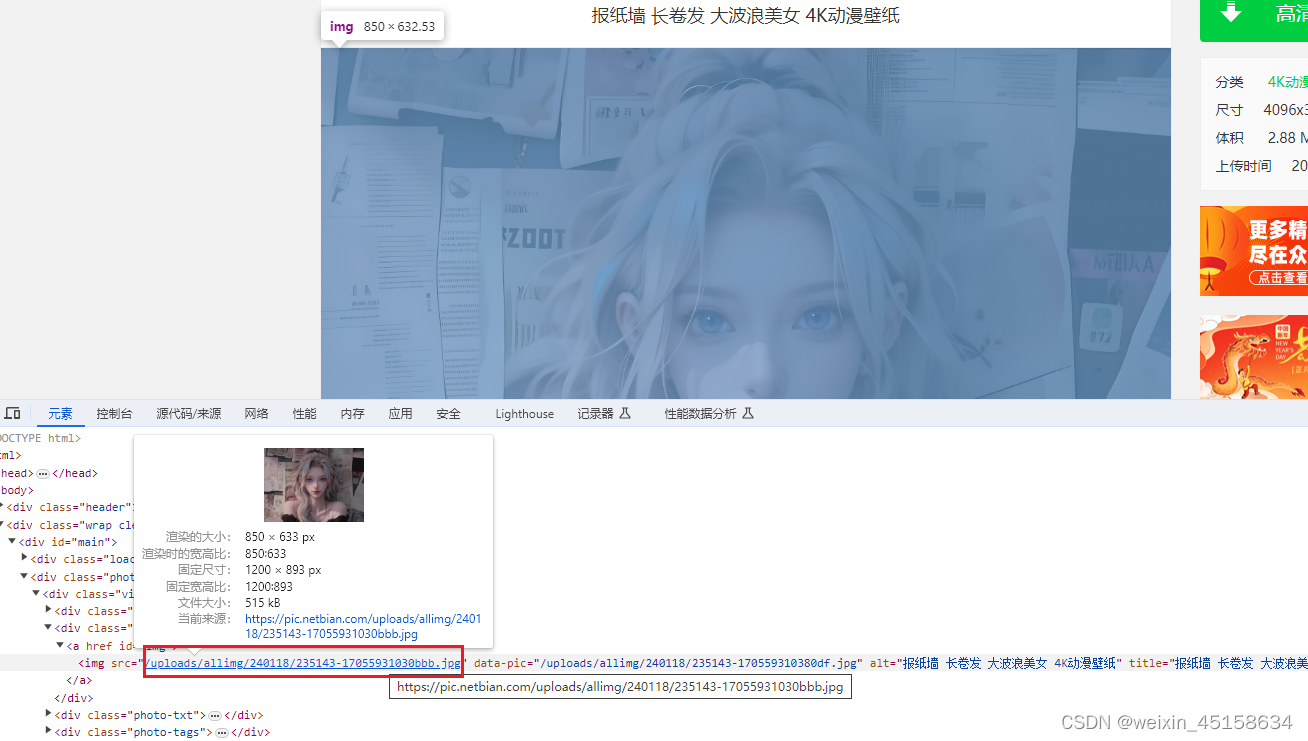
# 拼接url获取详情页完整地址
for base_url in li_list:
# print(base_url)
detail_url = url + base_url
# print(detail_url)
# 再创建一个请求各个detail_url
res1 = requests.get(detail_url,headers=headers)
res1.encoding = 'gbk'
# print(res1.text)
# 创建一个tree_img对象去获取到对应详情页的图片的xpath对象
tree_img = etree.HTML(res1.text)
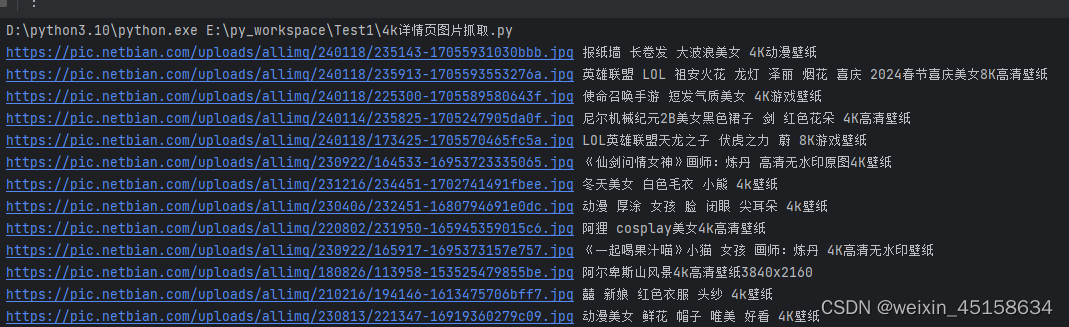
img_src = tree_img.xpath('//div[@class="photo-pic"]//img/@src')
# 创建一个tree_img对象去获取到对应详情页的图片的标题对象
img_title = tree_img.xpath('//div[@class="photo-pic"]//img/@alt')
for img in img_src:
print(url+img,img_title[0])
4、创建图片保存路径
# 创建图片保存路径
path = '4k高清详情页图片'
if not os.path.exists(path):
os.mkdir(path)
5、写入图片
# 拼接url获取详情页完整地址
for base_url in li_list:
# print(base_url)
detail_url = url + base_url
# print(detail_url)
# 再创建一个请求各个detail_url
res1 = requests.get(detail_url, headers=headers)
res1.encoding = 'gbk'
# print(res1.text)
# 创建一个tree_img对象去获取到对应详情页的图片的xpath对象
tree_img = etree.HTML(res1.text)
img_src = tree_img.xpath('//div[@class="photo-pic"]//img/@src')
# 创建一个tree_img对象去获取到对应详情页的图片的标题对象
img_title = tree_img.xpath('//div[@class="photo-pic"]//img/@alt')
for img in img_src:
# 拼接完整的图片地址
detail_href = url + img
# 标题取列表第一个
img_title = img_title[0]
print(detail_href, img_title)
with open(path + "\{}.jpg".format(img_title), mode='wb') as d_img:
img_res = requests.get(detail_href)
d_img.write(img_res.content)
完整代码:
import os
import time
import requests
from lxml import etree
url = 'https://pic.netbian.com'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
res = requests.get(url=url, headers=headers)
res.encoding = 'gbk'
# 创建tree对象
tree = etree.HTML(res.text)
# 通过xpath找到对应标签
li_list = tree.xpath('//div[@class="slist"]/ul[@class="clearfix"]/li/a/@href')
# print(li_list)
# 创建图片保存路径
path = '4k高清详情页图片'
if not os.path.exists(path):
os.mkdir(path)
# 拼接url获取详情页完整地址
for base_url in li_list:
# print(base_url)
detail_url = url + base_url
# print(detail_url)
# 再创建一个请求各个detail_url
res1 = requests.get(detail_url, headers=headers)
res1.encoding = 'gbk'
# print(res1.text)
# 创建一个tree_img对象去获取到对应详情页的图片的xpath对象
tree_img = etree.HTML(res1.text)
img_src = tree_img.xpath('//div[@class="photo-pic"]//img/@src')
# 创建一个tree_img对象去获取到对应详情页的图片的标题对象
img_title = tree_img.xpath('//div[@class="photo-pic"]//img/@alt')
for img in img_src:
# 拼接完整的图片地址
detail_href = url + img
# 标题取列表第一个
img_title = img_title[0]
print(detail_href, img_title)
with open(path + "\{}.jpg".format(img_title), mode='wb') as d_img:
img_res = requests.get(detail_href)
d_img.write(img_res.content)







 本文介绍如何使用Python的requests和lxml库抓取网页上的图片链接,通过XPath解析获取详情页图片地址,然后下载并保存到指定路径中。
本文介绍如何使用Python的requests和lxml库抓取网页上的图片链接,通过XPath解析获取详情页图片地址,然后下载并保存到指定路径中。
















 3197
3197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









