






诗词名句网:
URL = https://www.shicimingju.com/book/index.html
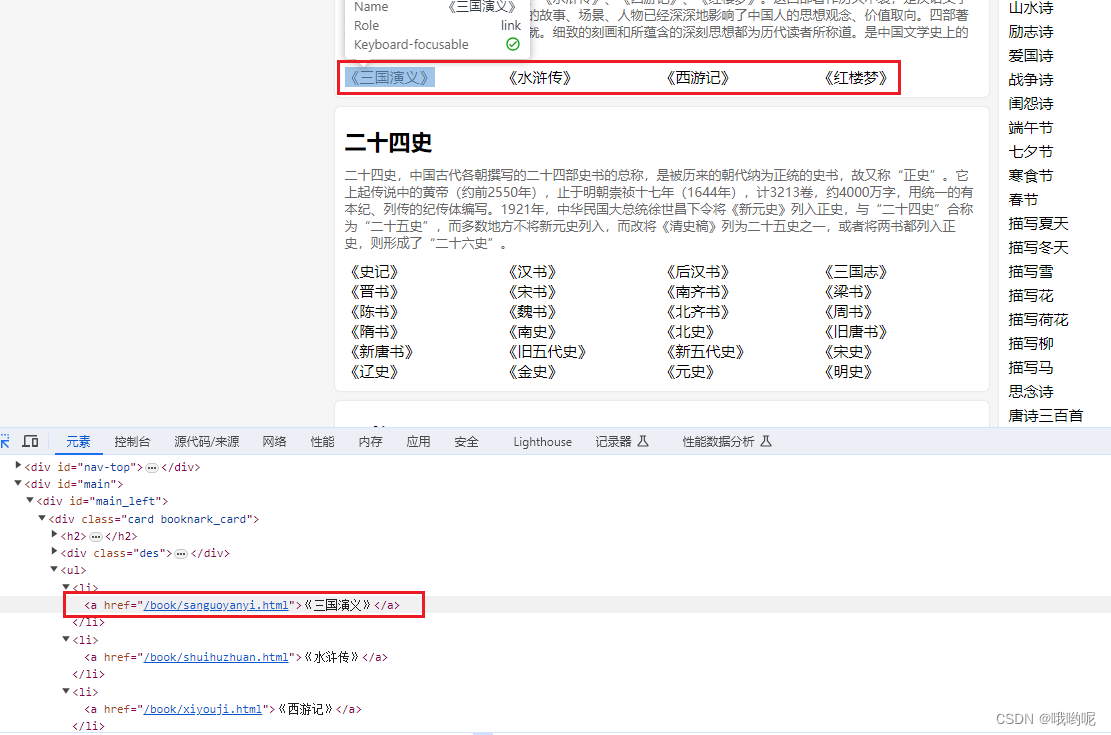
1、获取页面Html内容
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
res = requests.get(url=url, headers=headers)
res.encoding = res.apparent_encoding
# print(res.text)
soup = BeautifulSoup(res.text, "lxml")
return soup通过bs4获取到页面内容,可以从HTML中提取数据,所以将获取html封装成一个方法,返回一个soup对象
2、获取书名以及书的链接
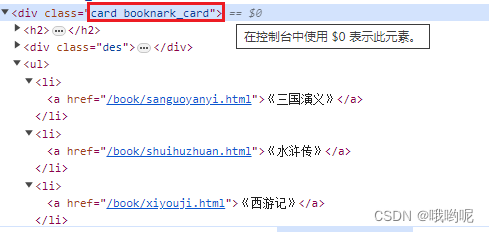
分析四个书名都在div card book_card中,直接用soup对象找到对应位置
然后再找里面li,遍历出来后去里面的;
那么a.text就为书名。
而href即为base_url + (a.attrs['href'])
定义一个空字典。书名为key,href为value
最终返回书的字典
def get_book(soup):
book_obj = soup.find(name="div", attrs={"class": "card booknark_card"})
li_list = book_obj.findAll(name="li")
book_dict = {}
base_url = "https://www.shicimingju.com/"
for li in li_list:
# print(li)
a = li.find(name="a")
book_name = a.text
book_url = base_url + (a.attrs['href'])
book_dict[book_name] = book_url
return book_dict返回字典后遍历一下:
book_dict = get_book(get_html(url))
# print(book_dict)
for book, book_href in book_dict.items():
print(book, book_href)3、获取书的目录及目录对应链接
第2步时拿到了书的链接,通过get_html方法获取页面元素,传入到get_mulu方法中
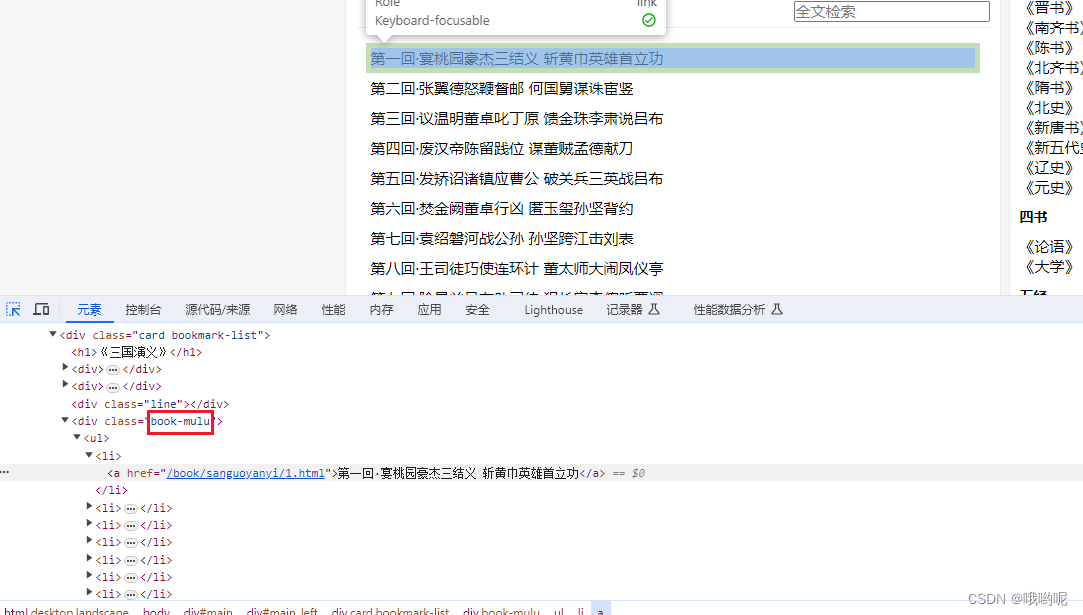
分析到目录都在class为"book-mulu"的div中。通过bs4模块找到对应内容,再存到一个名为mulu_dict的字典中,目录标题为key,目录链接为value,注意目录链接也需要拼接成完整的url;
返回该字典
def get_mulu(mulu_html):
mulu_dict = {}
book_mulu = mulu_html.find("div", class_="book-mulu")
# print(book_mulu)
mulu_list = book_mulu.find_all("a")
for mulu in mulu_list:
mulu_title = mulu.text
# print(mulu_title)
mulu_href = "https://www.shicimingju.com" + (mulu.attrs['href'])
# print(mulu_href,mulu_title)
mulu_dict[mulu_title] = mulu_href
# print(mulu_dict)
return mulu_dict4、获取章节内容
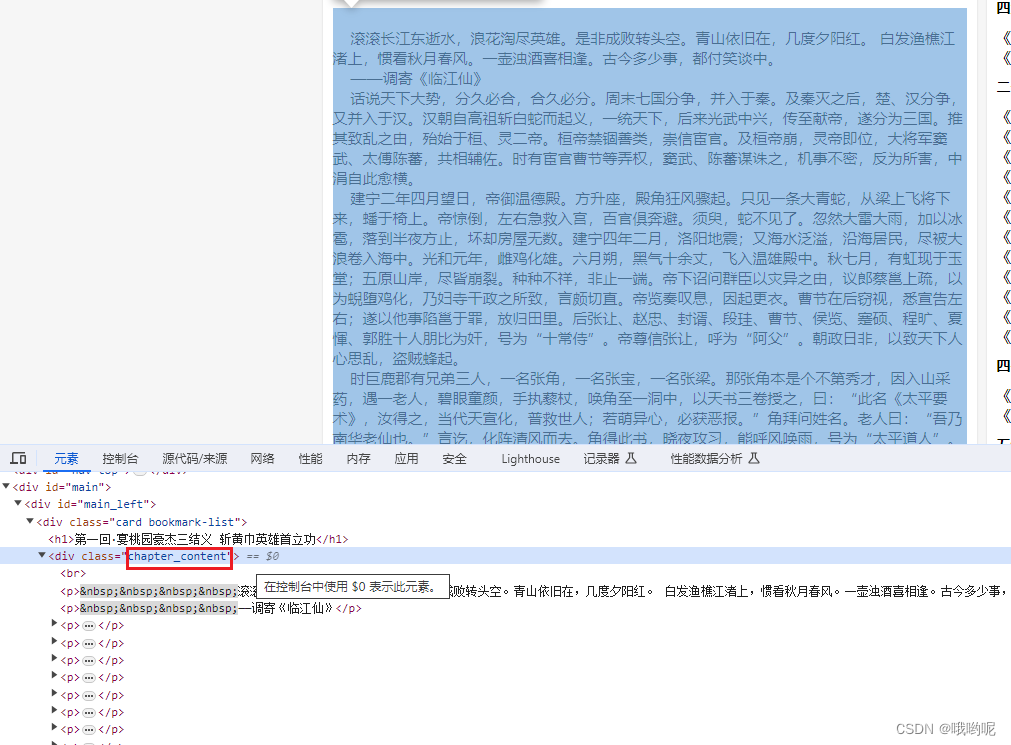
通过分析每个章节的内容都在class名为"chapter_content"的div中,通过bs4模块找到对应位置,
content_html为get_html(章节链接)获得的
接下来就是老样子,定义空字典,key存入章节标题。value存入章节内容
def get_mulu_content(mulu_title, content_html):
content_dict = {}
chapter_content = content_html.find("div", class_="chapter_content")
content = chapter_content.text
content_dict[mulu_title] = content
# print(content_dict)
return content_dict5、下载保存
def save_book(book, content_title, content_dict):
'''
:param book: 书名,通过书名创建对应的文件夹存放章节
:param content_title: 内容名称即章节名称,用来作为文件名
:param content_dict: 内容字典,value为章节内容
:return:
'''
if not os.path.exists(book):
os.mkdir(book)
path = os.path.join(book)
with open(path + "/{}.txt".format(content_title), mode="w", encoding="utf-8") as f:
f.write(content_dict[content_title])
print(f"{book} === {content_title} 下载完成!!!!!!")6、main函数
def main(url):
book_dict = get_book(get_html(url))
# print(book_dict)
# 遍历出书名以及书的链接
for book, book_href in book_dict.items():
print(book, book_href)
# 通过传入书url进入到get_html方法获得目录的html内容
mulu_html = get_html(book_href)
# 在通过get_mulu方法,传入mulu_html获得目录字典
mulu_dict = get_mulu(mulu_html)
# 遍历目录字典
for mulu_title in mulu_dict:
# 获取章节html
content_html = get_html(mulu_dict[mulu_title])
# 获取章节内容字典
content_dict = get_mulu_content(mulu_title, content_html)
# 遍历章节内容字典,调用下载保存方法保存
for content_title in content_dict:
save_book(book, content_title, content_dict)
完整代码
import requests
from bs4 import BeautifulSoup
import os
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
res = requests.get(url=url, headers=headers)
res.encoding = res.apparent_encoding
# print(res.text)
soup = BeautifulSoup(res.text, "lxml")
return soup
# print(div_card)
def get_book(soup):
# 获取
book_obj = soup.find(name="div", attrs={"class": "card booknark_card"})
li_list = book_obj.findAll(name="li")
book_dict = {}
base_url = "https://www.shicimingju.com/"
for li in li_list:
# print(li)
a = li.find(name="a")
book_name = a.text
book_url = base_url + (a.attrs['href'])
book_dict[book_name] = book_url
return book_dict
def get_mulu(mulu_html):
mulu_dict = {}
book_mulu = mulu_html.find("div", class_="book-mulu")
# print(book_mulu)
mulu_list = book_mulu.find_all("a")
for mulu in mulu_list:
mulu_title = mulu.text
# print(mulu_title)
mulu_href = "https://www.shicimingju.com" + (mulu.attrs['href'])
# print(mulu_href,mulu_title)
mulu_dict[mulu_title] = mulu_href
# print(mulu_dict)
return mulu_dict
def get_mulu_content(mulu_title, content_html):
content_dict = {}
chapter_content = content_html.find("div", class_="chapter_content")
content = chapter_content.text
content_dict[mulu_title] = content
# print(content_dict)
return content_dict
def save_book(book, content_title, content_dict):
'''
:param book: 书名,通过书名创建对应的文件夹存放章节
:param content_title: 内容名称即章节名称,用来作为文件名
:param content_dict: 内容字典,value为章节内容
:return:
'''
if not os.path.exists(book):
os.mkdir(book)
path = os.path.join(book)
with open(path + "/{}.txt".format(content_title), mode="w", encoding="utf-8") as f:
f.write(content_dict[content_title])
print(f"{book} === {content_title} 下载完成!!!!!!")
def main(url):
book_dict = get_book(get_html(url))
# print(book_dict)
# 遍历出书名以及书的链接
for book, book_href in book_dict.items():
print(book, book_href)
# 通过传入书url进入到get_html方法获得目录的html内容
mulu_html = get_html(book_href)
# 在通过get_mulu方法,传入mulu_html获得目录字典
mulu_dict = get_mulu(mulu_html)
# 遍历目录字典
for mulu_title in mulu_dict:
# 获取章节html
content_html = get_html(mulu_dict[mulu_title])
# 获取章节内容字典
content_dict = get_mulu_content(mulu_title, content_html)
# 遍历章节内容字典,调用下载保存方法保存
for content_title in content_dict:
save_book(book, content_title, content_dict)
if __name__ == '__main__':
url = "https://www.shicimingju.com/book/index.html"
main(url)


















 1345
1345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









