







AdvFaces: Adversarial Face Synthesis
AdvFaces:对抗性人脸合成
摘要
我们提出了AdvFaces,一种自动对抗人脸合成方法,通过生成对抗网络学习在显著面部区域产生最小的扰动。一旦AdvFaces经过训练,它就可以自动产生难以察觉的扰动,从而避开最先进的人脸匹配器,攻击成功率分别高达97.22%和24.30%,用于混淆和模拟攻击。
1. introduction
我们强调对抗性人脸生成器的以下要求:
- 生成的对抗人脸图像应该在感知上是真实的,这样人类观察者就可以将图像识别为与目标主体相关的合法人脸图像。
- 人脸需要被干扰,这样他们就不能被识别为黑客(混淆攻击)或自动匹配目标对象(模拟攻击)由AFR系统。
- 扰动的量应该由黑客控制。这将允许黑客将学习模型的成功作为扰动量的函数来检验。
- 对抗性示例应该是可转移的和模型不可知的(即将目标AFR模型视为黑盒)。换句话说,生成的对抗示例在其他黑盒AFR系统上也应该具有较高的攻击成功率。
本文提出了一种自动对抗人脸合成方法AdvFaces,该方法为探测人脸图像生成对抗掩码,满足上述所有要求。然后,可以将对抗性掩码添加到探测人脸图像中,以获得一个对抗性人脸示例,该示例可用于冒充任何目标身份或混淆自己的身份(见图4)。本文的贡献可以总结如下:
-
一个GAN, AdvFaces,学习生成视觉逼真的对抗人脸图像,这些图像被最先进的AFR系统错误分类。
-
通过AdvFaces生成的对抗人脸是模型不可知的和可转移的,并且在5个最先进的自动人脸识别系统上取得了很高的成功率。
-
可视化的面部区域,其中像素是扰动和分析不同的图像分辨率对扰动量的影响。
-
一个开源的自动对抗脸生成器,允许用户控制扰动的量。
2. 相关工作
2.1 生成对抗网络(GANs)
生成对抗网络[12]在多种图像合成应用中取得了成功[27,7],如风格迁移[37,18,11]、图像到图像的翻译[17,46]和表示学习[28,30,23]。Isola等人表明,图像到图像的条件GAN可以极大地改善合成结果[17]。在我们的工作中,我们采用了类似的对抗损失和图像到图像的网络架构,以学习从输入人脸图像到扰动输出图像的映射,从而使扰动图像无法与真实人脸图像区分开来。然而,与之前在gan上的工作不同,我们的目标是合成不仅在视觉上逼真而且能够逃避AFR系统的人脸图像。
2.2 图像分类中的对抗性攻击
大多数已发表的论文都集中在白盒攻击上,黑客可以完全访问被攻击的目标分类模型[36,13,4,43,22]。给定图像,Goodfellow等人提出了快速梯度符号方法(Fast Gradient Sign Method, FGSM),该方法通过目标模型[13]反向传播生成一个对抗示例。Madry等人提出了投影梯度下降法(PGD),一种FGSM[22]的多步变体。其他工作集中在通过最小化目标函数来优化对抗性扰动,同时满足某些约束b[4]。然而,这些白盒方法在人脸识别领域是不可行的,因为攻击者可能对部署的AFR系统没有任何了解。此外,优化过程可能需要对目标系统进行多次查询,直到收敛为止。相反,我们提出了一种前馈网络,它可以在推理过程中不需要任何AFR系统的知识,通过单次前向传递自动生成对抗图像。
事实上,前馈网络已被用于合成对抗性攻击。Baluja和Fischer提出了一种深度自动编码器,可以学习将输入图像转换为对抗图像[2]。在他们的工作中,使用L2范数损失来约束生成的对抗实例在L2像素空间中接近原始图像。相比之下,我们使用深度神经网络作为区分真实和合成人脸图像的鉴别器,以保持生成的对抗性示例的感知质量。通过gan合成对抗实例的研究在文献中是有限的[42,39,35]。这些方法需要softmax概率来逃避图像分类器。然而,AFR系统不使用softmax分类层,因为类(身份)的数量不是固定的。相反,我们提出了一个身份损失函数,更适合使用从人脸匹配器获得的人脸嵌入来生成对抗人脸。
2.3 人脸识别的对抗性攻击
在文献中,对人脸识别领域中生成对抗样例的研究相对有限。Bose等人通过求解约束优化来制作对抗性示例,使得人脸检测器无法检测到人脸[3]。
在[32]中,扰动被限制在人脸的眼镜区域,并通过基于梯度的方法生成对抗图像。这种对抗性眼镜也可以通过生成网络来合成。然而,这些方法依赖于人脸识别模型的白盒操作,这在现实场景中是不切实际的。
Dong等人提出了一种黑盒环境下生成对抗人脸的进化优化方法[9]。
然而,在合成真实的对抗人脸之前,它们需要对目标AFR系统进行至少1000次查询。Song等人采用条件变化自编码器GAN在半白盒设置[34]中制作对抗性人脸图像。然而,他们只关注模仿攻击,并且需要至少5张目标主体的图像来进行训练和推理。相比之下,我们训练了一个可以执行混淆和模拟攻击的GAN,并且需要目标对象的单一面部图像。
3. AdvFaces
我们的目标是合成一个在视觉上看起来属于目标人物的人脸图像,然而自动人脸识别系统要么不正确地将合成图像与另一个人匹配,要么与真人的画廊图像不匹配。图5概述了建议的框架。
AdvFaces由生成器G、鉴别器D和人脸匹配器F组成(参见图5和算法1)。
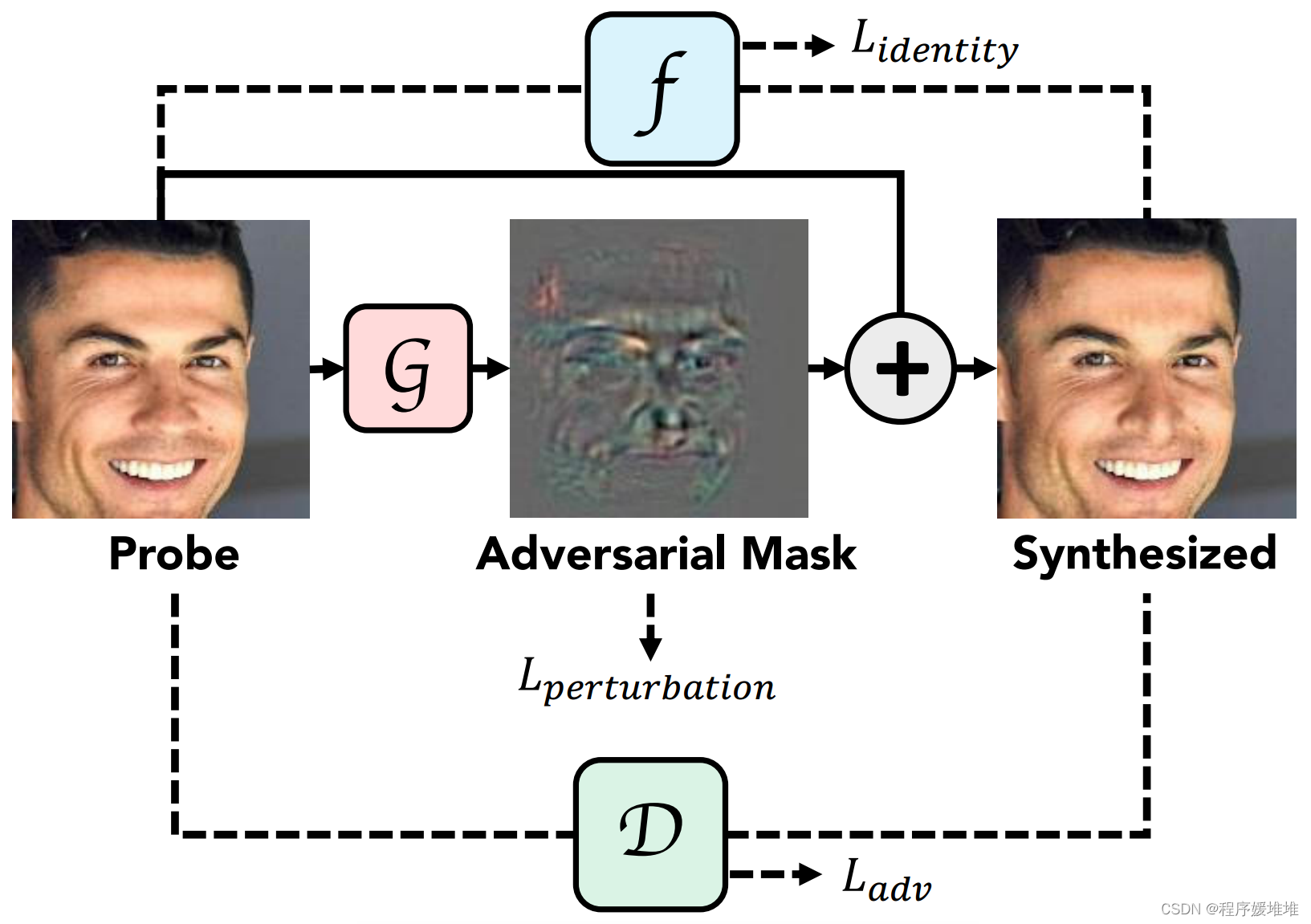
图5:在混淆设置中提出的对抗性生成方法的概述。给定探测人脸图像,AdvFaces自动生成一个对抗掩码,然后将其添加到探测中以获得对抗人脸图像。
算法1

生成器G:所建议的生成器接受一个输入人脸图像x∈X,并输出一个图像G(x)。生成器以输入图像x为条件;对于不同的输入人脸,我们将得到不同的合成图像。
由于我们的目标是获得一个度量上接近原始输入图像x的对抗图像,因此我们不希望干扰原始图像中的所有像素。出于这个原因,我们将生成器的输出视为加性掩模,对抗人脸为x + G(x)。如果G(x)中像素的大小最小,则对抗图像主要由探针x组成。在这里,我们将G(x)表示为“对抗掩模”。为了限定对抗性掩模的大小,我们通过最小化L2范数在训练过程中引入一个扰动铰链损失:
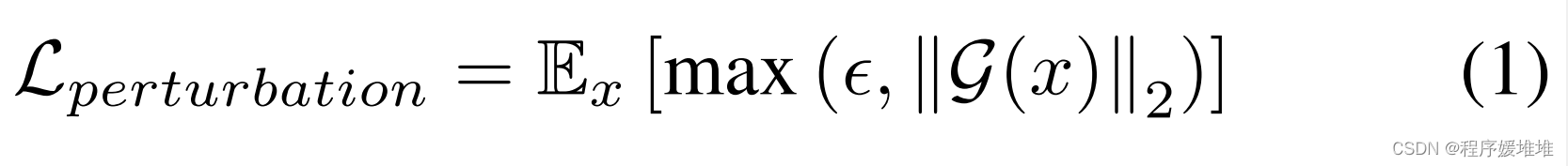
式中∈ [0;1)是控制允许的最小扰动量的超参数。
为了实现我们模仿目标对象或混淆自己身份的目标,我们需要一个人脸匹配器F来监督AdvFaces的训练。对于混淆攻击,目标是生成一个与任何主体的图库图像不匹配的对抗图像。在每次训练迭代中,AdvFaces试图通过恒等损失函数最小化输入探针x和生成图像x + G(x)的人脸嵌入之间的余弦相似度:
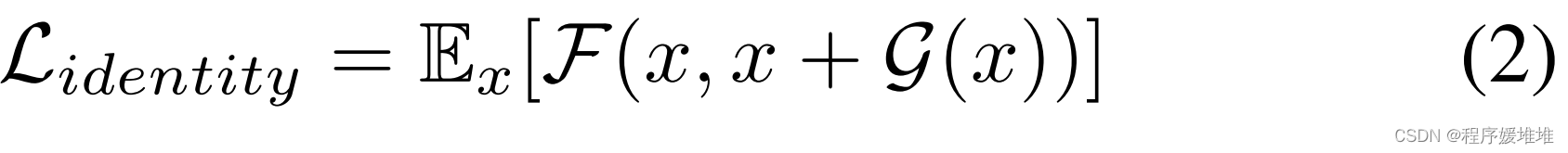
对于模拟攻击,AdvFaces通过以下方式最大化随机选择目标探针y的人脸嵌入与生成的对抗人脸x + G(x)之间的余弦相似度:
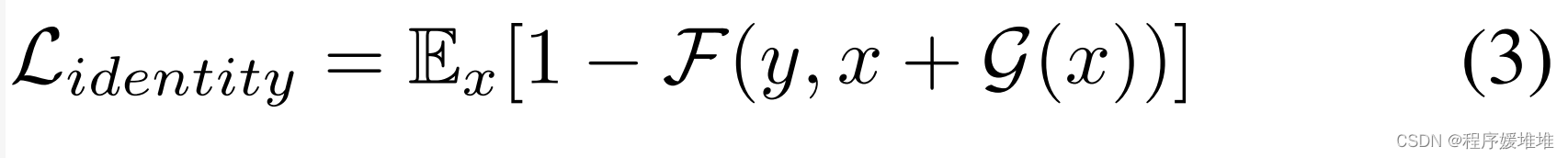
微扰和身份损失函数强制网络学习可以最小扰动的显著面部区域,以逃避自动人脸识别系统。
鉴别器:类似于之前关于gan的研究[12,17],我们引入了一个鉴别器,以促进生成图像的感知真实感。我们使用全卷积网络作为基于patch的鉴别器[17]。
这里,鉴别器D旨在通过GAN损失来区分探针x和生成的对抗人脸图像x + G(x):
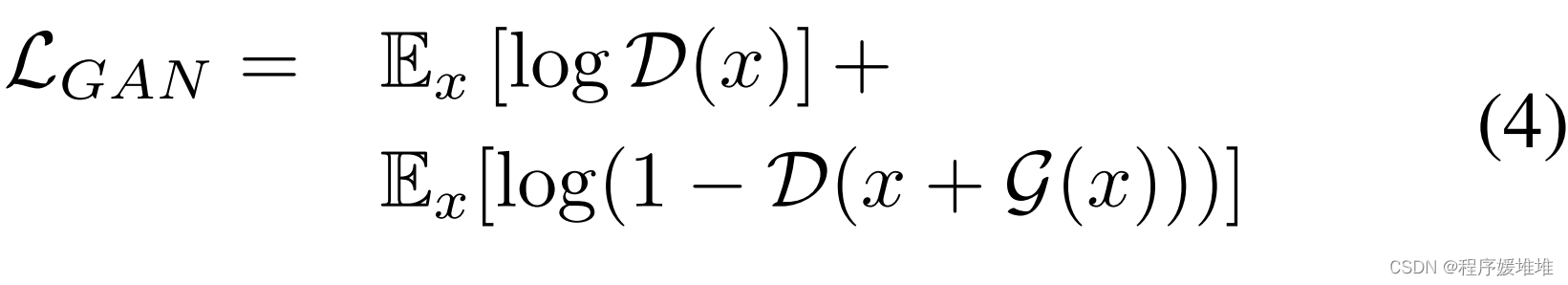
最后,AdvFaces以端到端方式进行训练,目标如下:
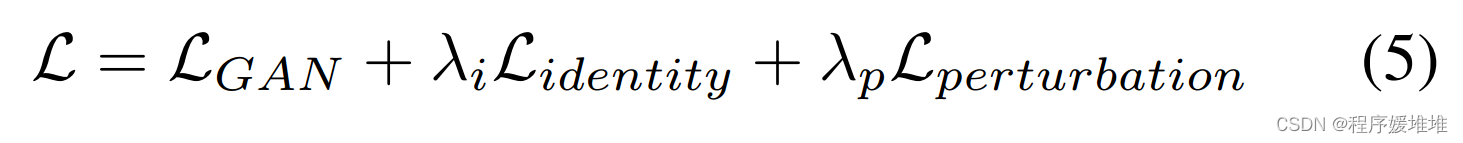
其中λi和λp分别是控制恒等损失和微扰损失相对重要性的超参数。请注意,LGAN和l摄动鼓励生成的图像在视觉上与原始人脸图像相似,而liidentity则优化了高攻击成功率。我们通过farg minGmaxDLg将AdvFaces训练为最小化游戏。经过训练,生成器G可以对任何输入图像生成对抗的人脸图像,并且可以在任何黑箱人脸识别系统上进行测试。
4. 实验结果
评估指标:我们通过(i)攻击成功率和(ii)结构相似性(SSIM)来量化AdvFaces和其他最先进基线产生的对抗性攻击的有效性。
混淆攻击的攻击成功率计算为:
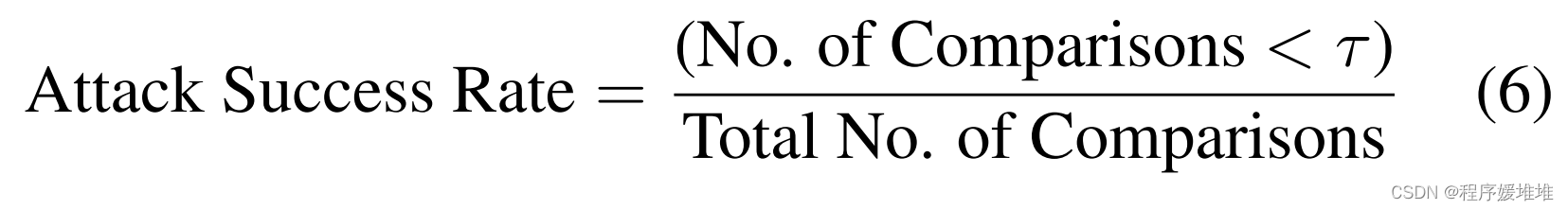
每次比较包括受试者的对抗探针和登记图像。这里,τ是一个预先确定的阈值,例如,在0.1% FAR4处计算。定义模拟攻击的攻击成功率为:
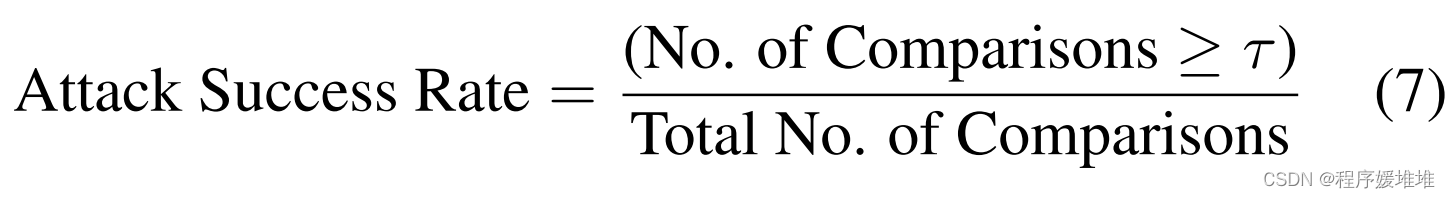
在这里,比较包括与目标探针合成的对抗性图像,并与目标的登记图像相匹配。 我们通过 10 倍交叉验证来评估模拟设置的成功率,其中每倍都包含一个随机选择的目标。
与之前的研究[34]类似,为了衡量对抗样本与输入人脸之间的相似度,我们计算了图像之间的结构相似指数(SSIM)。SSIM是−1(完全不同的图像对)到1(相同的图像对)之间的归一化度量:
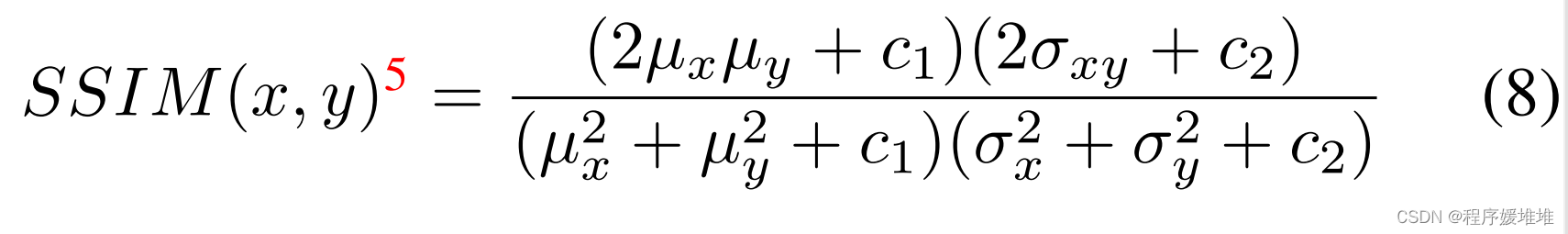
数据集:我们在CASIA-WebFace上训练AdvFaces,然后在LFW上进行测试。
-
CASIA-WebFace由属于10,575个不同主题的494,414张人脸图像组成。
-
LFW包含5,749个不同主题的13,233张网络收集图像。为了计算攻击成功率,我们只考虑至少有两张人脸图像的受试者。经过筛选,共有1680名受试者的9614张人脸图像可供评估。
我们在Tensorflow中使用ADAM优化器,整个网络的β1 = 0.5和β2 = 0.9。每个小批由32张人脸图像组成。我们训练AdvFaces 20万步,固定学习率为0:0001。由于我们的目标是生成高成功率的对抗性面孔,因此身份丢失是至关重要的。我们经验地设λi = 10.0, λp = 1.0。我们训练了两个独立的模型,并分别为混淆和模拟攻击设置 = 3.0和 = 8.0。所有实验均使用Tensorflow r1.12.0和NVIDIA Quadro M6000 GPU进行。具体实现见附录A。
面部识别系统:在我们所有的实验中,我们使用了5个最先进的面部匹配器。其中三个是公开的,分别是FaceNet [31], spheres[20]和ArcFace[6]。我们还报告了两种商用现货(COTS)面部匹配器,COTS- a和COTS- b8的结果。在训练过程中,我们使用FaceNet[31]作为白盒人脸识别模型F。本文中所有的测试图像都是由同一模型生成的(仅使用FaceNet进行训练),并在不同的匹配器上进行测试。
4.1 与最先进的比较
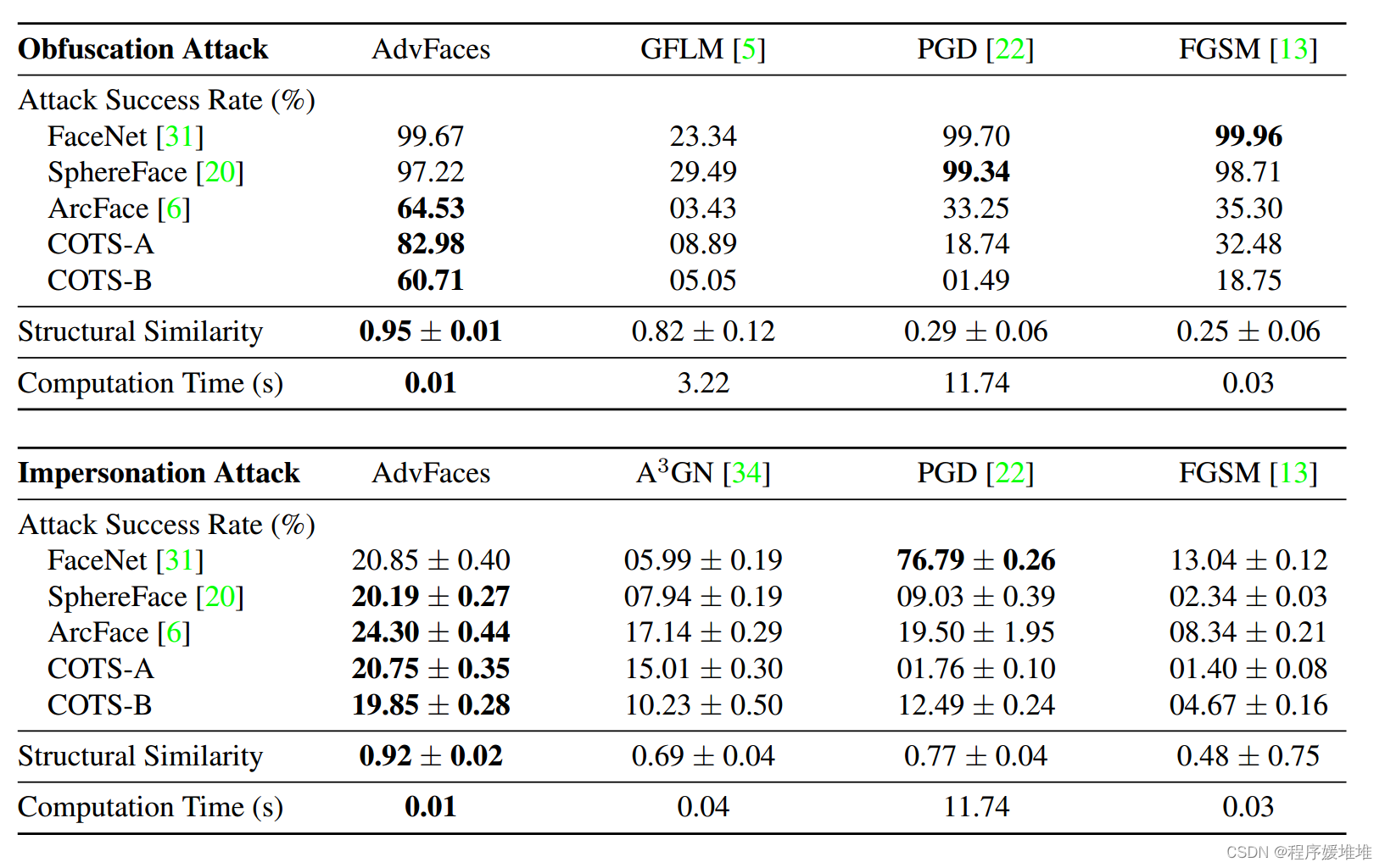
在表1中,我们发现与最先进的技术相比,AdvFaces生成了类似于探针的对抗性面。此外,在混淆和模拟设置中,对抗性图像在4个最先进的黑盒AFR系统上获得了很高的混淆攻击成功率。AdvFaces学习扰动人脸的显著区域,不像PGD [22], FGSM[13]会扰动图像中的每个像素。因此,我们发现尽管PGD和FGSM的成功率很高,但探针与合成面之间的结构相似性很低。另一方面,GFLM[5]在几何上扭曲了人脸图像,从而导致低结构相似性。此外,最先进的匹配器对这种几何变形具有鲁棒性,这解释了GFLM在人脸匹配器上的低成功率。A3GN也是一种基于gan的方法,但是在模拟设置中无法获得合理的成功率。在图6中,我们看到,除了成功率高之外,本文方法生成的对抗人脸在视觉上也很吸引人,并且与基线相比,探针图像和合成图像之间的差异几乎无法区分。
4.2 消融实验
为了分析系统中每个模块的重要性,在图7中,我们分别通过去除GAN损失(LGAN)、微扰损失l摄扰和身份损失liidentity来训练AdvFaces的三个变体进行比较。GAN损失有助于保证合成人脸的视觉质量。单独使用生成器时,会引入不需要的工件。没有提出的扰动损失,对抗性掩模中的扰动是无界的,因此,导致缺乏感知质量。身份损失是确保获得对抗图像的必要条件。在没有身份丢失的情况下,合成图像无法躲避最先进的人脸匹配器。我们发现AdvFaces的每个组件都是必要的,以便获得一个对抗的脸,不仅在感知上是真实的,而且可以逃避最先进的人脸匹配器。

图7:AdvFaces的变体分别没有GAN损失、微扰损失和身份损失。
4.3 AdvFaces学习什么?
在训练过程中,AdvFaces学习干扰可以逃避人脸匹配器的显著面部区域F(在我们的例子中是FaceNet[31])。这是由Lperturbation来执行的,它惩罚大的摄动,从而将摄动限制在显著像素位置。在图8中,AdvFaces合成了与探测对应的对抗性掩码。然后,我们对掩模进行阈值,以提取扰动幅度超过0.40的像素。可以推断,眉毛、眼球和鼻子包含AFR系统用来识别个体的高度判别性信息。因此,干扰这些显著区域足以逃避最先进的人脸识别系统
4.4 扰动量的影响
微扰铰链损失,Lperturbation由一个超参数限定。也就是说,对抗性掩码的L2范数必须至少为。如果没有这个约束,对抗性掩码将变成一个空图像,探针没有任何变化。使用,我们可以观察到攻击成功率与图9中探针和合成对抗面之间的结构相似性之间的权衡。越高,摄动限制越小。这以较低的结构相似性为代价产生了更高的攻击成功率。对于模拟攻击,这意味着对抗图像可能包含黑客和目标的面部特征。在我们的实验中,我们分别为模拟和混淆攻击选择 = 8.0和 = 3.0。
5. 总结
我们提出了一种新的对抗人脸合成方法,即AdvFaces,该方法可以自动生成具有不可察觉扰动的对抗人脸图像,从而避开最先进的人脸匹配器。在GAN的帮助下,以及所提出的扰动和身份损失,AdvFaces学习人脸匹配器识别所需的像素位置集,并且只干扰那些显著的面部区域(如眉毛和鼻子)。经过训练后,AdvFaces可以生成高质量和感知上真实的对抗示例,这些示例对人眼无害,但可以避开最先进的黑盒人脸匹配器,优于其他最先进的对抗人脸方法。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









