







本项目根据学习其他人的代码,根据自己的需求进行了修改与改进,最后总结出这篇文章,供今后学习。文章前部分详细介绍,最后最后附源代码。
项目名称:诗词接龙
一、问题描述
诗词接龙的规则是诗词的首字接尾字,由前一个人先说一句诗词,后一个人根据前一个人的诗句的最后一个字,说出一句诗句与上一个人诗句进行接龙,要求是接诗句的人要说出一句以上一个人诗句的最后一个字的读音相同的诗句来进行接龙,如果符合要求,则继续接龙,如果不符合要求,则上一个人获胜。
二、问题求解
1、求解方案
要用nlp实现诗词接龙,首先需要有一个诗词库用来获取诗句,这个诗词库的数据可利用python爬虫进行获取,然后将这些诗词存入一个txt文档里,并进行简单的数据清理,再将诗词歌的句子分拆成开来,生成一个用以查找诗句的字典,再做处理,每当有人说出一句诗句时,根据诗句的最后一个字的拼音在字典里查找与其最后一个字拼音相同的诗句,Python里有一个类库xpingyin就是用来处理中文的拼音的,可以调用这个库,形成字典后,进行接龙,当输入一个诗句后,立即查找与输入的诗句最后一个字拼音相同的首字拼音,输出这个诗句,进行接龙。
2、优化思路
1、诗词的获取可利用爬虫生成诗词库,而无需自己准备诗词库。
2、可通过合理利用正则表达式来进行诗词文本处理,并建立字典,提高效率。
3、用相同的拼音接龙代替用相同的字进行接龙,更符合实际问题。
3、求解分析
这是一个自然语言处理范畴的问题,需要进行文本分析,涉及到python爬虫获取数据,数据清理,建立诗词库,诗词文本句子拆分,汉字转拼音,正则表达式等的利用。
需要调用的几个主要的库包括:
pickle:在机器学习中,我们常常需要把训练好的模型存储起来,这样在进行决策时直接将模型读出,而不需要重新训练模型,这样就大大节约了时间。Python提供的pickle模块就很好地解决了这个问题,它可以序列化对象并保存到磁盘中,并在需要的时候读取出来,任何对象都可以执行序列化操作。
Xpinyin:中文汉字转拼音库。
Defaultdict:其作用是在于,当字典里的key不存在但被查找时,返回的不是keyError而是一个默认值。
re :正则表达式。
bs4 :它的作用是能够快速方便简单的提取网页中指定的内容,给一个网页字符串,然后使用它的接口将网页字符串生成一个对象,然后通过这个对象的方法来提取数据,通过本地文件进行学习,通过网络进行写代码。
(1)根据标签名进行获取节点,只能找到第一个符合要求的节点。
(2)获取文本内容和属性。
lxml是一个解析器,bs4将网页字符串生成对象的时候需要用到解析器,就用lxml,或者使用官方自带的解析器 html.parser。
四、功能实现
1、使用环境
Pycharm、Python3、Windows10。
2、实现原理及步骤
(1)利用python爬虫爬取诗词,制作诗词库。
在古诗词网站上爬虫获取唐诗三百首、古诗三百、宋词三百、宋词精选等内容,通过列表的方式来获取诗词,因为考虑到电脑性能与爬取时间的问题,总共爬取的诗词大约1100多首,在我个人电脑上爬虫大约用时6分钟,爬虫完成后,保存到poem.txt文件。
具体实现为首先导入需要的库,然后在urls里定义需要爬取的网站页面,建立一个空列表,通过request的方式请求url和相应的头部,使用lxml解析器来获取页面html标签,再查找标签为div、class-sons的所有标签内容,接下来查找a标签的所有内容,建立空列表用来接收诗词,然后通过一系列正则表达式来处理诗句,在这里,我采用列表的方式来获取诗句,再将获取的诗句写入poem.txt文档中,形成诗词库。主要代码如下: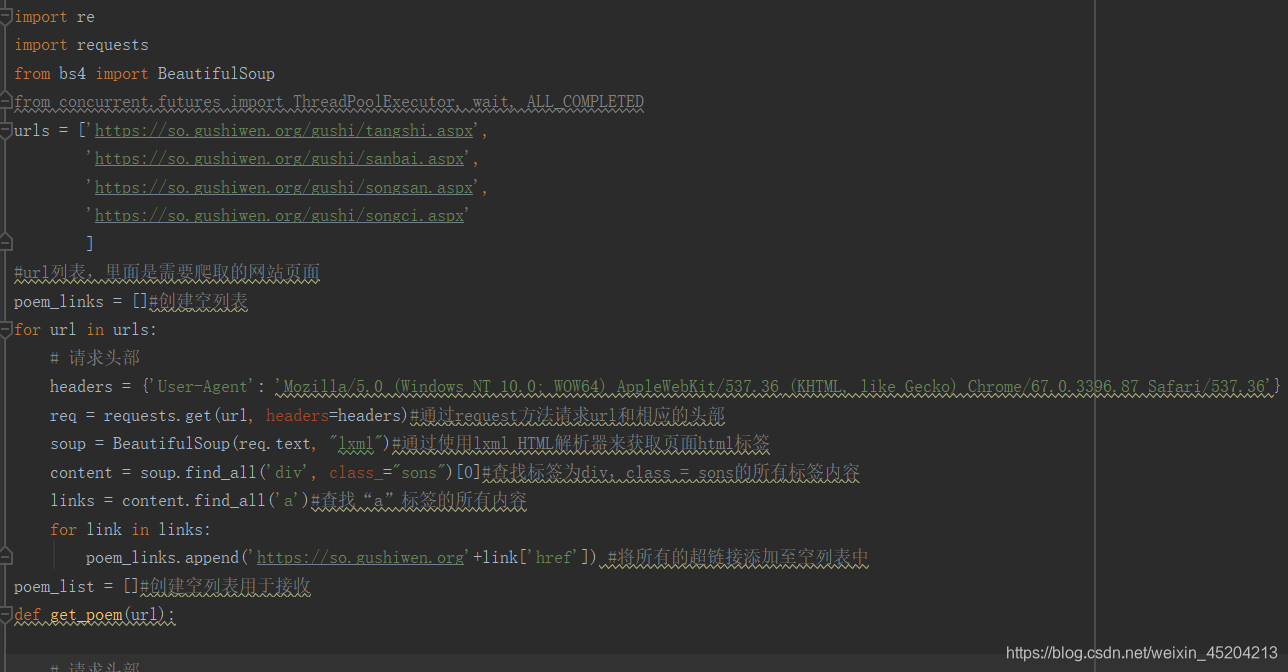
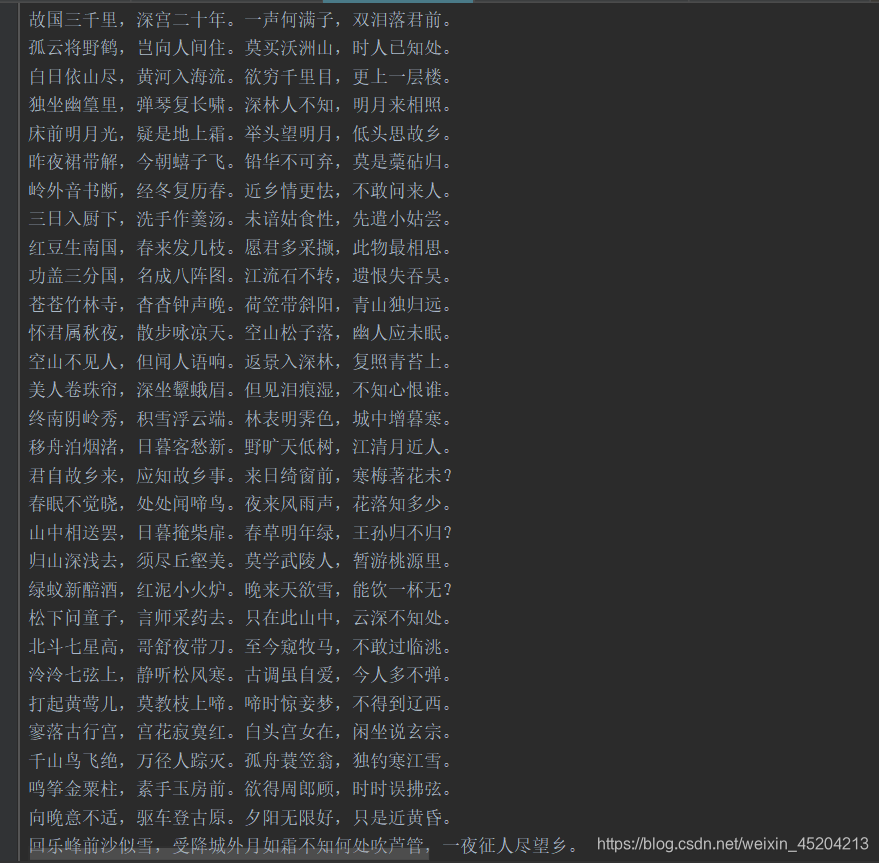
当然,这些诗词并不能直接使用,需要进行数据清理,比如有些诗词标点不规范,有些并不是诗词,只是诗词的序等等,虽然有些麻烦,但为了后面的诗词分句效果,也是值得的。爬取效果如下:
(2)诗词分句处理,形成字典。
有了诗词库,这时需要对诗词进行分句,分句的标准是按照诗词诗句的结尾为“。?!”进行分句,这个我利用了正则表达式’[\s\S]*?[。?!]'进行实现。
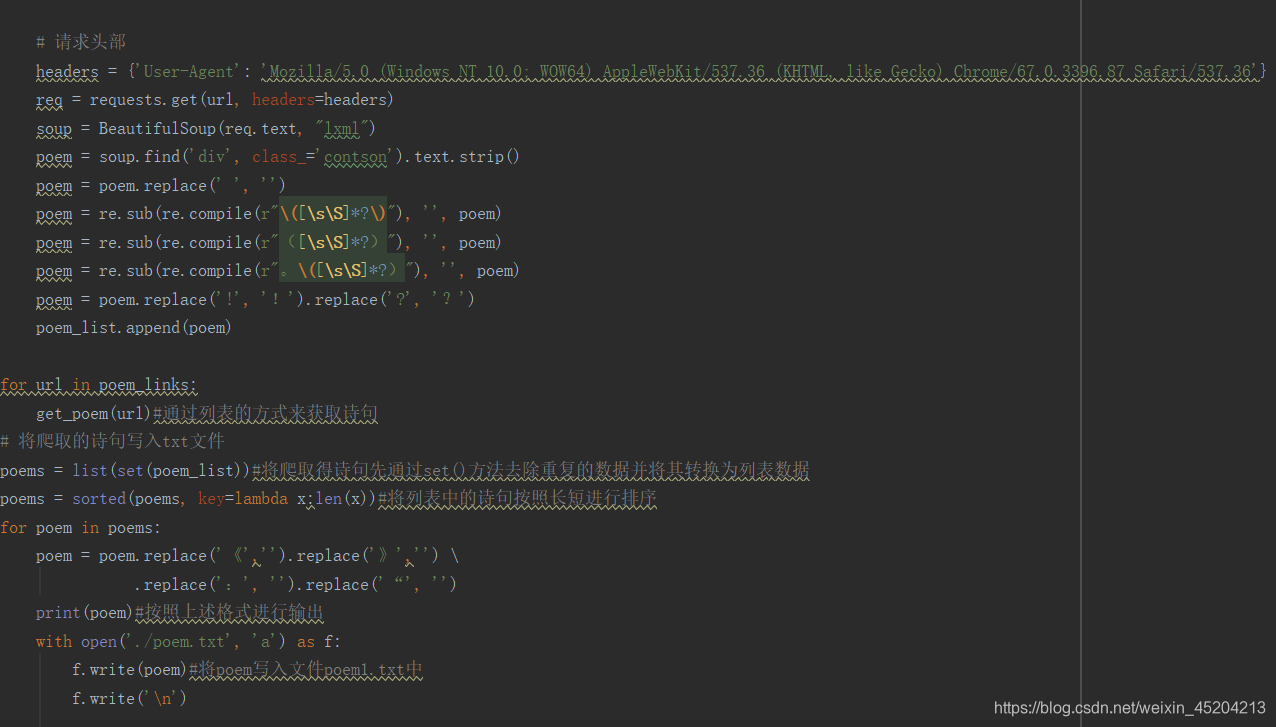
之后,将分句好的诗词写成字典,利用key-value的方式进行存储,键key为该诗句首字的拼音,值value为该首字拼音对应的诗句,并将字典保存为pickle文件,众所周知数据库是数据存储的常用方式,其在应用程序中使用,可以对大量数据进行存储。在这里我使用的pickle模块同样是为了永久存储,其可以对小数据量进行存储。数据存储在一个.pickle文件中。
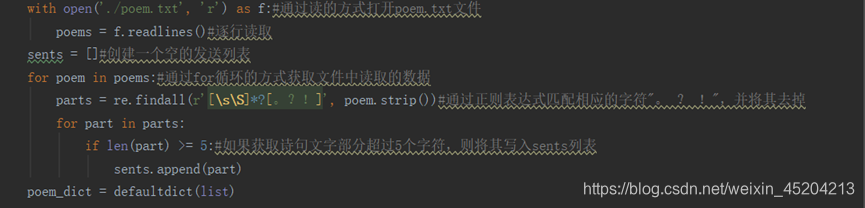
其代码实现为先导入相关的包,通过读的方式打开poem.txt文件,逐行进行读取,创建一个空的发送列表,再通过for循环的方式获取文件中读取的数据,通过正则表达式匹配相应的字符“,?!”,并将其去掉,然后进入一个for循环,把获取的诗句部分超过五个字符的诗句写入sents列表,并通过循环打印的方式输出诗句,调用
Pinyin().get_pinyin(sent,tone_marks=‘marks’,splitter=’’).split()[0]来获取诗句首字的拼音,并将拼音写入诗句库,最后形成字典。具体实现如下:

需要注意的是,一个拼音可以对应多个诗词。
(3)读取pickle文件,编写程序,以exe文件形式运行该程序。
为了能够在编译形成exe文件的时候不出错,需要改写xpinyin模块的__init__.py文件,将该文件的全部代码复制至mypinyin.py,并将代码中的下面这句代码:
data_path=os.path.join(os.path.dirname(os.path.abspath(file)), ‘Mandarin.dat’)
改写为:
data_path = os.path.join(os.getcwd(), ‘Mandarin.dat’)
这样就完成了mypinyin.py文件。
(4)诗词接龙。
我所实现的诗词接龙分为两种情景,首先我们需要选择是进行人工接龙还是进行机器接龙,选则人工接龙时,我们可以输入一个诗句,这时,机器便会进行查找诗词库,自动匹配符合规则的诗句,接下来又由人工输入,再机器,这样循环。当选择机器接龙时,我们需要输入开始的诗句,然后机器会把后续的诗句都列出来,但由于诗句会很多,所以我设置了十五次循环,意思是最多展示十五次接龙结果。
具体实现为首先以二进制读的方式获取字典,打开字典文件,主要代码如下:

然后设置人工接龙与机器接龙两个方式,在此我使用了try异常处理的方式来确保输入错误时不会出现程序运行错误,而是显示指定的输出内容,然后进行if判断,当选择人工时,显示“请输入一句诗”,然后获取输入句子的最后一个的字的拼音,然后判断字典中是否有这个字,并输出对应的结果。主要代码如下:
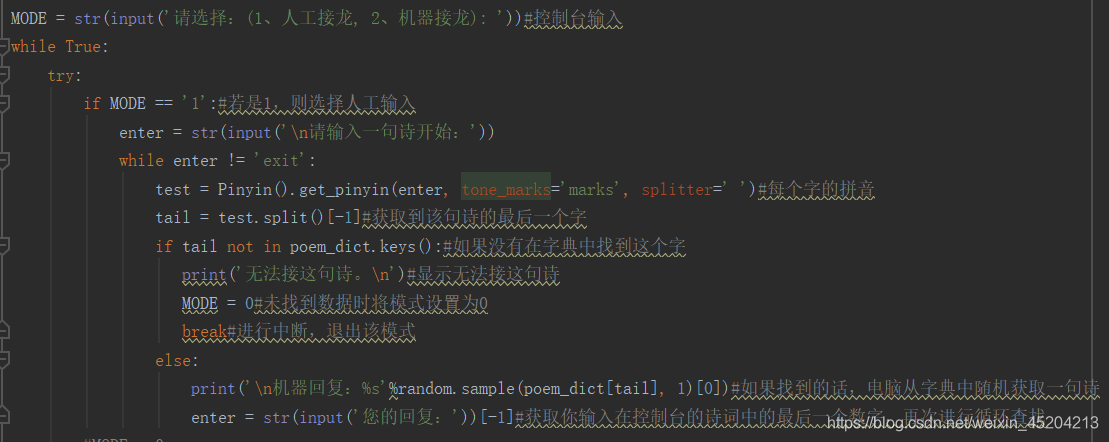
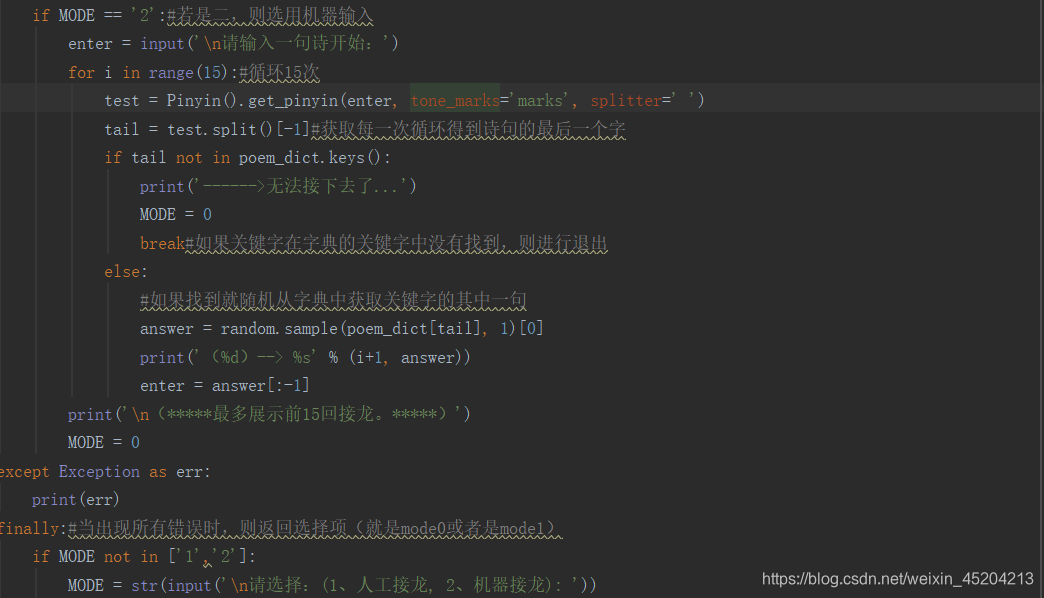
如果选择机器接龙,同样也是人工输入一个诗句,进入一个最多十五次的循环中,其他实现原理与人工接龙相同。最后,如果出现错误时,则返回最初的选
择项。主要代码如下:
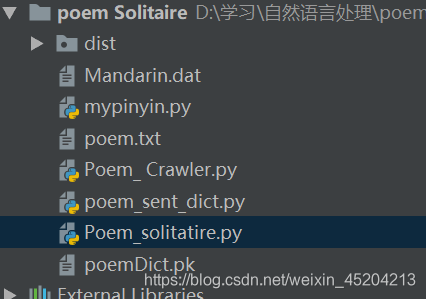
3、项目目录结构
以下为项目目录结构,其中Poem_Crawer.py为爬虫文件,poem_sent-dict.py为建立字典文件,poemDict.pk为其生成的字典,Poem_solitatire.py为诗词接龙文件,mypinyin.py为汉字转拼音文件,Mandarin.dat文件从xpinyin模块对应的文件夹下复制过来,poem.txt为爬虫获取的诗词库。
五、测试运行
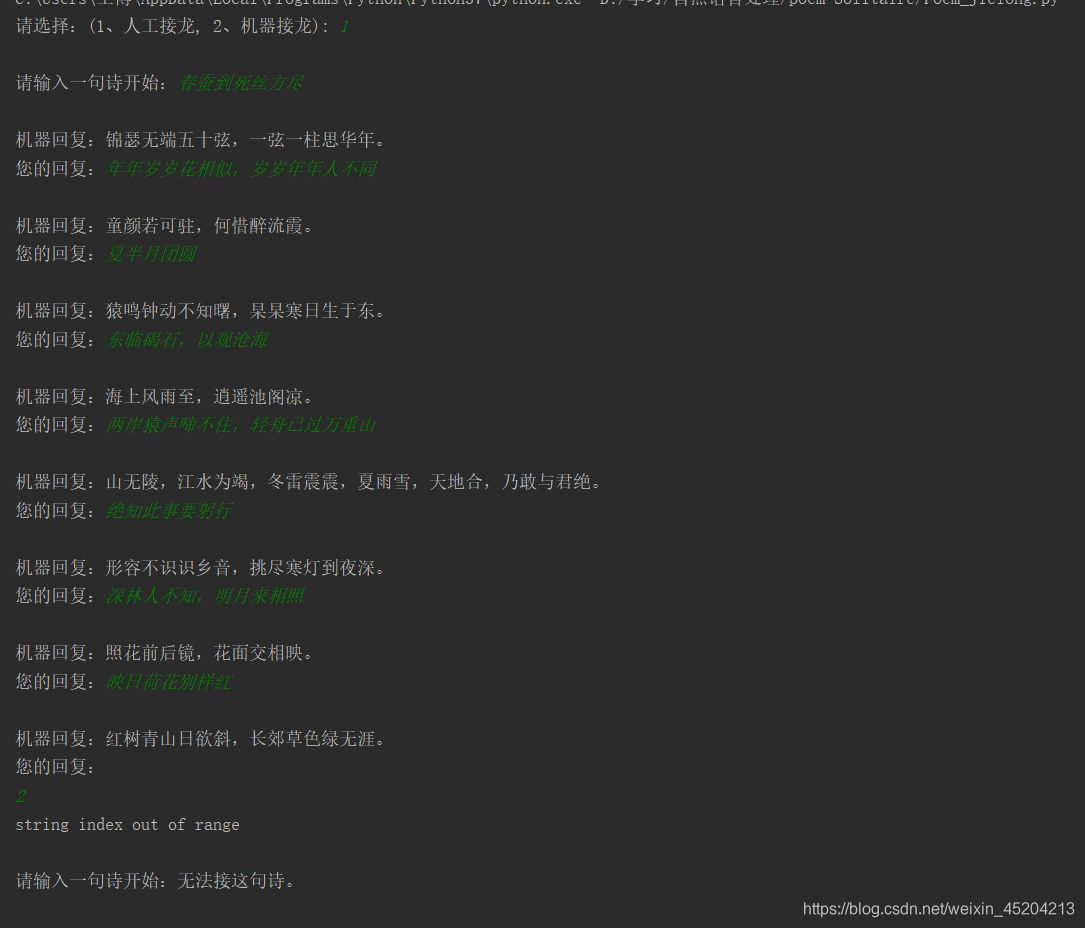
1、人工
选择1,输入一句诗“春蚕到死丝方尽,蜡炬成灰泪始干”进行接龙,结果如下:
2、机器
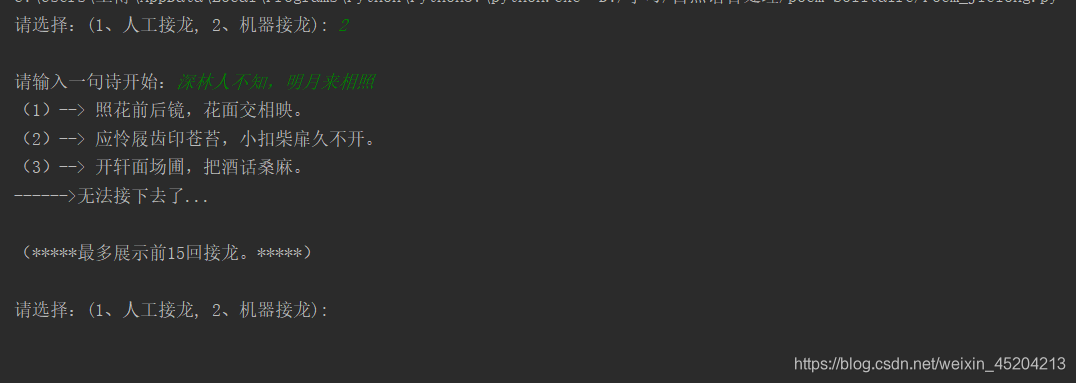
选择2,然后输入“深林人不知,明月来相照。”测试结果如下:
六、总结
由于个人能力以及机器性能的不足,选择了不是很复杂的项目,在诗词接龙功能的实现上还算完整准确,但在运行效率与人机交互界面上还有一些欠缺。本项目基本实现了诗词接龙的功能,包括诗词库的爬虫获取,并利用正则表进行诗词文本处理,并对所爬取的数据进行了数据清理,比如有些诗词标点不规范,有些并不是诗词,只是诗词的序等等,虽然有些麻烦,但为后面的诗词分句提供便利,使用了汉字转拼音的功能,并生成了诗词字典,以诗句首字拼音作为键值,诗句作为值进行存储,还完成人工与机器两种方式的接龙。但也有一些不足之处需要后续改进,比如说爬虫时的时间有些长,需要提高爬虫速度,减少时间,以及在接龙时对人工输入的数据没有正误的判断,这些都需要在后期的学习中逐步完善等等。
源代码:
1、mypinyin.py
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
import os.path
import re
PinyinToneMark = {
0: u"aoeiuv\u00fc",
1: u"\u0101\u014d\u0113\u012b\u016b\u01d6\u01d6",
2: u"\u00e1\u00f3\u00e9\u00ed\u00fa\u01d8\u01d8",
3: u"\u01ce\u01d2\u011b\u01d0\u01d4\u01da\u01da",
4: u"\u00e0\u00f2\u00e8\u00ec\u00f9\u01dc\u01dc",
}
class Pinyin(object):
"""translate chinese hanzi to pinyin by python, inspired by flyerhzm’s
`chinese\_pinyin`_ gem
usage
-----
::
>>> from xpinyin import Pinyin
>>> p = Pinyin()
>>> # default splitter is `-`#默认分隔符是'-'
>>> p.get_pinyin(u"上海")
'shang-hai'
>>> # show tone marks
>>> p.get_pinyin(u"上海", tone_marks='marks')
'shàng-hǎi'
>>> p.get_pinyin(u"上海", tone_marks='numbers')
>>> 'shang4-hai3'
>>> # remove splitter(移除分隔符)
>>> p.get_pinyin(u"上海", '')
'shanghai'
>>> # set splitter as whitespace(将空格作为分隔符)
>>> p.get_pinyin(u"上海", ' ')
'shang hai'
>>> p.get_initial(u"上")
'S'
>>> p.get_initials(u"上海")
'S-H'
>>> p.get_initials(u"上海", u'')
'SH'
>>> p.get_initials(u"上海", u' ')
'S H'
请输入utf8编码汉字
.. _chinese\_pinyin: https://github.com/flyerhzm/chinese_pinyin
"""
data_path = os.path.join(os.getcwd(), 'Mandarin.dat')
def __init__(self, data_path=data_path):
self.dict = {}
with open(data_path) as f:
for line in f:
k, v = line.split('\t')
self.dict[k] = v
@staticmethod
def decode_pinyin(s):
s = s.lower()
r = ""
t = ""
for c in s:
if "a" <= c <= 'z':
t += c
elif c == ':':
assert t[-1] == 'u'
t = t[:-1] + "\u00fc"
else:
if '0' <= c <= '5':
tone = int(c) % 5
if tone != 0:
m = re.search("[aoeiuv\u00fc]+", t)
if m is None:
# pass when no vowels find yet
t += c
elif len(m.group(0)) == 1:
# if just find one vowels, put the mark on it
t = t[:m.start(0)] \
+ PinyinToneMark[tone][PinyinToneMark[0].index(m.group(0))] \
+ t[m.end(0):]
else:
# mark on vowels which search with "a, o, e" one by one
# when "i" and "u" stand together, make the vowels behind
for num, vowels in enumerate(("a", "o", "e", "ui", "iu")):
if vowels in t:
t = t.replace(vowels[-1], PinyinToneMark[tone][num])
break
r += t
t = ""
r += t
return r
@staticmethod
def convert_pinyin(word, convert):
if convert == 'capitalize':
return word.capitalize()
if convert == 'lower':
return word.lower()
if convert == 'upper':
return word.upper()
def get_pinyin(self, chars=u'你好', splitter=u'-',
tone_marks=None, convert='lower'):
result = []
flag = 1
for char in chars:
key = "%X" % ord(char)
try:
if tone_marks == 'marks':
word = self.decode_pinyin(self.dict[key].split()[0].strip())
elif tone_marks == 'numbers':
word = self.dict[key].split()[0].strip()
else:
word = self.dict[key].split()[0].strip()[:-1]
word = self.convert_pinyin(word, convert)
result.append(word)
flag = 1
except KeyError:
if flag:
result.append(char)
else:
result[-1] += char
flag = 0
return splitter.join(result)
def get_initial(self, char=u'你'):
try:
return self.dict["%X" % ord(char)].split(" ")[0][0]
except KeyError:
return char
def get_initials(self, chars=u'你好', splitter=u'-'):
result = []
flag = 1
for char in chars:
try:
result.append(self.dict["%X" % ord(char)].split(" ")[0][0])
flag = 1
except KeyError:
if flag:
result.append(char)
else:
result[-1] += char
return splitter.join(result)
2、poem-crawler
import re
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
urls = ['https://so.gushiwen.org/gushi/tangshi.aspx',
'https://so.gushiwen.org/gushi/sanbai.aspx',
'https://so.gushiwen.org/gushi/songsan.aspx',
'https://so.gushiwen.org/gushi/songci.aspx'
]
#url列表,里面是需要爬取的网站页面
poem_links = []#创建空列表
for url in urls:
# 请求头部
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
req = requests.get(url, headers=headers)#通过request方法请求url和相应的头部
soup = BeautifulSoup(req.text, "lxml")#通过使用lxml HTML解析器来获取页面html标签
content = soup.find_all('div', class_="sons")[0]#查找标签为div,class = sons的所有标签内容
links = content.find_all('a')#查找“a”标签的所有内容
for link in links:
poem_links.append('https://so.gushiwen.org'+link['href']) #将所有的超链接添加至空列表中
poem_list = []#创建空列表用于接收
def get_poem(url):
# 请求头部
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text, "lxml")
poem = soup.find('div', class_='contson').text.strip()
poem = poem.replace(' ', '')
poem = re.sub(re.compile(r"\([\s\S]*?\)"), '', poem)
poem = re.sub(re.compile(r"([\s\S]*?)"), '', poem)
poem = re.sub(re.compile(r"。\([\s\S]*?)"), '', poem)
poem = poem.replace('!', '!').replace('?', '?')
poem_list.append(poem)
for url in poem_links:
get_poem(url)#通过列表的方式来获取诗句
# 将爬取的诗句写入txt文件
poems = list(set(poem_list))#将爬取得诗句先通过set()方法去除重复的数据并将其转换为列表数据
poems = sorted(poems, key=lambda x:len(x))#将列表中的诗句按照长短进行排序
for poem in poems:
poem = poem.replace('《','').replace('》','') \
.replace(':', '').replace('“', '')
print(poem)#按照上述格式进行输出
with open('./poem.txt', 'a') as f:
f.write(poem)#将poem写入文件poem1.txt中
f.write('\n')
3、poem-sent-dict
import re
import pickle
from xpinyin import Pinyin
from collections import defaultdict
def main():
with open('./poem.txt', 'r') as f:#通过读的方式打开poem.txt文件
poems = f.readlines()#逐行读取
sents = []#创建一个空的发送列表
for poem in poems:#通过for循环的方式获取文件中读取的数据
parts = re.findall(r'[\s\S]*?[。?!]', poem.strip())#通过正则表达式匹配相应的字符"。 ? !",并将其去掉
for part in parts:
if len(part) >= 5:#如果获取诗句文字部分超过5个字符,则将其写入sents列表
sents.append(part)
poem_dict = defaultdict(list)
for sent in sents:
print(part)#通过循环打印的方式输出诗句
head = Pinyin().get_pinyin(sent, tone_marks='marks', splitter=' ').split()[0]#通过Pinyin()方法,获取第一个字的拼音
poem_dict[head].append(sent)
with open('./poemDict.pk', 'wb') as f:
pickle.dump(poem_dict, f)#此处通过序列化实现将poem_dict列表写入到poemDict.pk文件中
main()
4、poem-solitatire
import pickle
from mypinyin import Pinyin
import random
# 获取字典
with open('./poemDict.pk', 'rb') as f:#rb二进制读的方式
poem_dict = pickle.load(f)#打开字典文件
MODE = str(input('请选择:(1、人工接龙, 2、机器接龙): '))#控制台输入
while True:
try:
if MODE == '1':#若是1,则选择人工输入
enter = str(input('\n请输入一句诗开始:'))
while enter != 'exit':
test = Pinyin().get_pinyin(enter, tone_marks='marks', splitter=' ')#每个字的拼音
tail = test.split()[-1]#获取到该句诗的最后一个字
if tail not in poem_dict.keys():#如果没有在字典中找到这个字
print('无法接这句诗。\n')#显示无法接这句诗
MODE = 0#未找到数据时将模式设置为0
break#进行中断,退出该模式
else:
print('\n机器回复:%s'%random.sample(poem_dict[tail], 1)[0])#如果找到的话,电脑从字典中随机获取一句诗
enter = str(input('您的回复:'))[-1]#获取你输入在控制台的诗词中的最后一个数字,再次进行循环查找
#MODE = 0
if MODE == '2':#若是二,则选用机器输入
enter = input('\n请输入一句诗开始:')
for i in range(15):#循环15次
test = Pinyin().get_pinyin(enter, tone_marks='marks', splitter=' ')
tail = test.split()[-1]#获取每一次循环得到诗句的最后一个字
if tail not in poem_dict.keys():
print('------>无法接下去了...')
MODE = 0
break#如果关键字在字典的关键字中没有找到,则进行退出
else:
#如果找到就随机从字典中获取关键字的其中一句
answer = random.sample(poem_dict[tail], 1)[0]
print('(%d)--> %s' % (i+1, answer))
enter = answer[:-1]
print('\n(*****最多展示前15回接龙。*****)')
MODE = 0
except Exception as err:
print(err)
finally:#当出现所有错误时,则返回选择项(就是mode0或者是mode1)
if MODE not in ['1','2']:
MODE = str(input('\n请选择:(1、人工接龙, 2、机器接龙): '))

















 2935
2935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









