







**
1,多进程
**
1,程序:是一个指令的集合
2,进程是指正在执行的程序,或者说当你运行了一个程序,你就启动了一个进程
----编写完的代码,没有运行时称为程序,正在运行的代码称为进程
----程序是死的(静态的),进程是活的(动态的)
3,队列Queue 先入先出 放到队列中的第一个消息是被第一个取出来的
4,操作系统轮流让各个任务交替执行,由于CPU的执行速度太快,我们感觉就像所有任务都在同时执行一样
5,多进程中,每个进程中所有数据(包含全局变量)都各自拥有一份,互不影响
6,程序开始时,首先会创建一个主进程
7,在主进程下(父进程),我们可以创建新的进程(子进程)。子进程依赖于主进程,如果主进程结束,程序会退出
8,python提供了非常好用的多进程包multiprocessing,借助这个包可以完成从单进程到并发执行的转换
9,multiprocessing模块提供了一个Process类来创建一个进程对象
from multiprocessing import Process
def run(name):
print("子进程运行中,name=%s" % name)
if __name__ == "__main__":
print("父进程启动")
p = Process(target=run, args=("test",))
print("子进程将要执行")
p.start()
print(p.name)
p.join()
运行结果为:
父进程启动
子进程将要执行
Process-1 # 每个进程只要跑起来,系统会自动给它分配一个名字
子进程运行中,name=test
也可以自己给进程起一个名字
p = Process(target=run, args=("test",), name = "pro1")
注意:
1,在__name__==__main__的情况下,文件作为程序直接被执行。而import到其他程序中是不会被执行的。
2,import的时候,__name__不等于__main__就不会出现递归运行了。
**

from multiprocessing import Process
import time
import os
def run():
print("子进程开始运行%d 父进程ID为%d" % (os.getpid(), os.getppid()))
if __name__ == "__main__":
print("主进程开始运行ID为%d" % os.getpid()) # pid得到当前进程编号
time.sleep(2) # ppid得到的是主进程的编号 此编号是由操作系统分配的
p = Process(target=run)
p.start()
p.join()
运行结果为:
主进程开始运行ID9348
子进程开始运行308 父进程ID为9348
2,进程类
**
1,Process(target, args, name)
target表示调用的函数对象,后面直接跟函数名,不加括号
args表示调用的函数对象的参数,是元组位置参数,args=(1,) 只有一个元组时,后面一定要加英文逗号
name为子进程的名字
2,Process类的常用方法
—p.start() 启动进程,并调用该子进程中的p.run()方法
—p.run() 进程启动时运行的方法,正是它去调用target指定的函数
—p.terminate() 强制终止进程,不会进行任何清理操作(了解)
—p.is_alive() 如果进程仍然运行,返回True。用来判断进程是否还在运行
—p.join( [timeout] ) 主进程等待进程终止,timeout是可选的超时时间
3,PID 进程跑起来的时候,系统自动给进程分配的编号
**
3,多进程默认不共享数据
**
全局变量在多个进程中不共享。进程之间的数据时独立的。默认情况下互不影响。
from multiprocessing import Process
num = 1
def run1():
global num
num += 10
print("子进程1运行中,num=%d" % num)
def run2():
global num
num += 20
print("子进程2运行中,num=%d" % num)
if __name__ == "__main__":
print("父进程启动")
p1 = Process(target=run1)
p2 = Process(target=run2)
print("子进程将要执行")
p1.start()
p2.start()
p1.join()
p2.join()
print("子进程结束")
print(num)
运行结果如下:
父进程启动
子进程将要执行
子进程1运行中,num=11
子进程2运行中,num=21
子进程结束
1
**
4,创建进程的另外一种方式:自定义一个类,继承自Process类
**
继承的目的是为了重写父类中的run方法。每次实例化这个类的时候,就等同于一个实例化进程对象。
import multiprocessing
import time
class ClockProcess(multiprocessing.Process):
def run(self):
n = 5
while n >= 0:
print(n)
time.sleep(2)
n -= 1
if __name__ == "__main__":
p = ClockProcess()
p.start()
p.join()
运行的结果为:
5
4
3
2
1
0
**
5,进程池
**
1,进程池用来创建多个进程。
2,当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process类生产多个进程。但如果需要创建多个目标时,此时就可以用到multiprocessing模块中的Pool进程池类
3,初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求。但如果池中的进程数已经达到指定的最大值,那么该请求就会等待。直到池中有进程结束,才会创建新的进程来执行
from multiprocessing import Pool
import time
import random
def work(num):
print(random.random()*num)
time.sleep(3)
if __name__ == "__main__":
po = Pool(3) # 指定进程池的最大进程数为3。如果不写的话,则默认大小为CPU核数
for i in range(10):
po.apply_async(work, (i,))
po.close() # 进程池关闭之后,不再接收新的请求
po.join() #等待进程池中的所有子进程结束,必须放在close后面
运行结果如下:
0.0
0.8434067539484286
0.9035027640534492
0.8440539956962685
1.4211959367783842
0.037711976403783654
4.13374002251715
5.397127285813744
4.10153323950918
1.5238340780303874
注意:在多进程中,主进程一般用来等待。真正的任务都是在子进程中执行。
4,multiprocessing.Pool常用函数解析
apply_async(func[ ,args [,kwds]])
使用非阻塞方式调用func并行执行(阻塞方式必须等待上一个进程退出,才能执行下一个进程)
例如进程池的最大进程数为3,那么可以有3个进程数同时在跑
args为传递给func的参数列表
kwds为传递给func的关键字参数列表(一般不用)
apply(func[ ,args [,kwds]])
使用阻塞方式调用func(了解)
close()
关闭Pool,使其不再接受新的任务(调用close方法之后就不能继续添加新的Process了)
terminate()
不管任务是否完成,立即终止(当池对象被垃圾收集时,terminate()将立即被调用)
join()
主进程阻塞,等待子进程的退出(等待所有子进程执行完毕),必须放在close的后面。必须在close或者terminate之后使用
from multiprocessing import Pool
import time
import os
import random
def task(task_id):
print("执行task %s(id为%s)" % (task_id, os.getpid()))
start = time.time()
time.sleep(random.random()*3)
end = time.time()
print("task%s运行%.2f秒" % (task_id, end - start))
if __name__ == "__main__":
print("核数", os.cpu_count())
print("主进程id为%d" % os.getpid())
p = Pool(2)
for i in range(4): # 创建4个进程加入到进程池中
p.apply_async(task, (i,)) # 异步非阻塞方式
# p.apply(task, (i,)) #同步阻塞方式(一个进程在跑的时候另外一个进程只能等着.当程序在运行的过程中有先后顺序的时候用同步)
print("waiting for all subprocess done")
p.close()
p.join()
print("all subprocess done")
运行结果为:
核数 4
主进程id为16596
waiting for all subprocess done
执行task 0(id为8140)
执行task 1(id为16344)
task0运行2.16秒
执行task 2(id为8140)
task1运行2.37秒
执行task 3(id为16344)
task2运行1.26秒
task3运行3.00秒
all subprocess done
**
6,进程间通信
**
from multiprocessing import Queue
if __name__ == "__main__":
q = Queue(3) # 初始化一个队列queue对象,最多可接受3条消息
q.put("第1个消息") # 添加的消息数据类型不限
q.put("第2个消息")
q.put("第3个消息")
print(q.full())
运行结果为:
True
1,可使用multiprocessing模块中的Queue实现多进程之间的数据传递
2,初始化Queue()对象时,若括号中没有指定最大可接收的消息数量或者数量为负值,则代表可接收的消息数量没有上限
3,Queue.qsize()
返回当前队列包含的消息数量
4,Queue.empty()
如果队列为空返回True,反之返回False
5,Queue.full()
如果队列满了返回True,反之返回False
6,Queue.get([ block [,timeout ]])
获取队列中的一条消息,然后将其从队列中移除,block的默认值为True
1,如果block设为默认值,且没有设置timeout,消息队列如果为空,此时程序将被阻塞(停在读取状态),
直到从消息队列中读到消息为止。如果设置了timeout,那么会等待timeout秒,若还没读取到任何消息,
则会抛出“Queue Empty”异常
2,如果block设为False,消息队列如果为空,则会立刻抛出“Queue Empty”异常
7,Queue.get_nowait() 相当于Queue.get(False)
8,Queue.put(item, [ block [,timeout ]])
将消息写入队列,block默认值为True
1,如果block设为默认值,且没有设置timeout,消息队列如果已满,此时程序将被阻塞(停在写入状态),
直到消息队列腾出空间为止。如果设置了timeout,则会等待timeout秒,若还没空间,则会抛出“Queue Full”异常
2,如果block设为False,消息队列如果没有空间可写入,则会立刻抛出“Queue Full”异常
9,Queue.put_nowait(item) 相当于Queue.put(item, False)
from multiprocessing import Queue
from multiprocessing import Process
import time
def write(q):
for i in ["a", "b", "c"]:
print("开始写入", i)
q.put(i)
time.sleep(1)
def read(q):
while True:
if not q.empty():
print(q.get())
else:
break
if __name__ == "__main__":
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
pw.start()
pw.join() # 等待写入完毕
pr.start() # 写入完毕之后,另外一个子进程pr开始运行
pr.join()
运行结果为:
开始写入 a
开始写入 b
开始写入 c
a
b
c
from multiprocessing import Process
from multiprocessing import Queue
import time
import random
def write(queue):
for i in ["a","b","c"]:
queue.put(i)
print("写入", i)
time.sleep(random.random() * 2)
def read(queue):
while True:
print("取出", queue.get())
if __name__ == "__main__":
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
pw.start()
pr.start()
pw.join()
# pr.join()
if q.empty():
print("看看是否执行")
if pr.is_alive():
print("pr活着")
pr.terminate()
if pw.is_alive():
print("pw活着")
pw.terminate()
运行结果为:
写入 a
取出 a
写入 b
取出 b
写入 c
取出 c
看看是否执行
pr活着
**
7,进程池创建的进程间通信
**
1,如果要使用Pool创建进程,就需要使用multiprocessing.Manager()中的Queue()
from multiprocessing import Manager, Pool
import time
def write(q):
for i in ["a", "b", "c"]:
print("开始写入", i)
q.put(i)
def read(q):
time.sleep(3)
for i in range(q.qsize()):
print("读取到", q.get())
if __name__ == "__main__":
q = Manager().Queue()
po = Pool(2)
po.apply_async(write, (q,))
po.apply_async(read, (q,))
po.close()
po.join()
运行结果为:
开始写入 a
开始写入 b
开始写入 c
读取到 a
读取到 b
读取到 c
需求:使用进程池方式实现多任务。复制一个文件夹下的所有文件(一个文件的复制由一个进程完成)
"""
使用进程池方式实现多任务
复制一个文件夹下的所有文件(一个文件的复制由一个进程来完成)
文件夹目录:C:\Users\toby5\Desktop\新建文件夹
注意 :要将目录地址中的 \ 改为 / C:/Users/toby5/Desktop/新建文件夹
使用管道队列Manager().Queue()
"""
from multiprocessing import Manager
from multiprocessing import Pool
import os, time, random
#复制文件
def copyFile(srcFile,toFile,queue):
try:
fr = open(srcFile,"r",encoding="utf-8")
fw = open(toFile,"w",encoding="utf-8")
content = fr.read()
fw.write(content)
# 将已经复制完毕的文件的信息 存入队列中
queue.put(toFile)
time.sleep(random.random() * 3)
finally:
fr.close()
fw.close()
if __name__ == "__main__":
queue = Manager().Queue()
pool = Pool()
# 准备好源文件夹
srcDir = "C:/Users/toby5/Desktop/新建文件夹"
# 创建好目标文件夹
toDir = srcDir + "复件"
os.makedirs(toDir)
list_files = os.listdir(srcDir) # 源文件夹里面包含的文件
for file in list_files: # 遍历源文件夹里面包含的文件
# 源文件
srcFile = srcDir + "/" + file
# 目标文件
toFile = toDir + "/" + file
# 同步执行多任务
# pool.apply(copyFile, args=(srcFile, toFile, queue))
# 异步执行多任务(异步执行的话,有一个callback回调函数。只有异步执行多任务时,有回调函数)
pool.apply_async(copyFile, args=(srcFile, toFile, queue))
# 阻塞主进程之前需要先关闭进程池对象,防止进程池里面的进程被修改
pool.close()
pool.join() # 阻塞主进程
num = 0
total = len(list_files)
while num < total:
s = queue.get()
print("{0}复制完成".format(s))
num += 1
print("复制完成度%.2f%%" % (num/total * 100))
关于进程池异步任务回调函数的使用
注意:以上代码是有bug的,后面进度条的体验性不好,因为它是全部复制完成之后,进度条再一下子全部打印
在实际的开发过程中,需要复制完成一个文件打印一下进度条
这时候就需要使用到 进程池异步任务中的回调函数
修改之后的代码如下:
from multiprocessing import Manager
from multiprocessing import Pool
import os, time, random
#复制文件
def copyFile(srcFile,toFile,queue):
try:
fr = open(srcFile,"r",encoding="utf-8")
fw = open(toFile,"w",encoding="utf-8")
content = fr.read()
fw.write(content)
# 将已经复制完毕的文件的信息 存入队列中
# queue.put(toFile)
time.sleep(random.random() * 3)
finally:
fr.close()
fw.close()
# 回调函数 (与某个进程处理的任务相关联,当该进程处理完该任务以后,回调函数被调用)
def finished(queue, file,total):
queue.put(file)
print((queue.qsize(), total))
print("文件{0}复制完成".format(file))
if __name__ == "__main__":
queue = Manager().Queue()
pool = Pool()
# 准备好源文件夹
srcDir = "C:/Users/toby5/Desktop/新建文件夹"
# 创建好目标文件夹
toDir = srcDir + "复件"
os.makedirs(toDir)
list_files = os.listdir(srcDir) # 源文件夹里面包含的文件
total = len(list_files)
for file in list_files: # 遍历源文件夹里面包含的文件
# 源文件
srcFile = srcDir + "/" + file
# 目标文件
toFile = toDir + "/" + file
# 同步执行多任务
# pool.apply(copyFile, args=(srcFile, toFile, queue))
# 异步执行多任务(异步执行的话,有一个callback回调函数。只有异步执行多任务时,有回调函数)
pool.apply_async(copyFile, args=(srcFile, toFile, queue), callback=finished(queue, file, total))
# 阻塞主进程之前需要先关闭进程池对象,防止进程池里面的进程被修改
pool.close()
pool.join() # 阻塞主进程
**
8,多线程
**
1,线程是实现多任务的另一种方式。不适合处理高并发的任务(多进程+协程处理高并发任务)
2,一个进程中也需要同时做多件任务,就需要同时运行多个“子任务”,这些子任务就称为线程
3,线程是更小的执行单元
1,一个进程中可拥有多个并行的线程,当中每一个线程,共享当前进程的资源
2,由于线程间的通信是在同一地址空间上进行的,所以不需要额外的通信机制,这就使得通信更简便而且
信息传递的速度也更快
3,一个进程中的线程共享相同的内存单元/内存地址空间,可以访问相同的变量和对象,而且它们从同一堆
中分配对象---->通信,数据交换,同步操作
进程和线程的区别


处理计算密集型任务时:用多进程(多进程的开销大,需要向操作系统申请内存空间)
处理IO密集型任务时:用多线程 (即输入输出操作比较多的程序)(发挥不了CPU多核的优势)
多线程有全局解释器锁GIL(不管CPU和线程数量,一次只能执行一个线程)
处理高并发:多进程+协程 是最有组合
CPU--进程--线程1 线程2 线程3(竞聘上岗机制,线程1休眠让出CPU,线程2和线程3会去抢CPU,取决于windows系统调度)
谁抢到谁执行
1,threading的常用方法
threading.active_count()
threading.current_thread() 获取当前线程
threading.main_thread() 获取主线程
2,Thread常用方法
start()
run()
join()
setName()
getName()
is_alive()
isDaemon()
setDaemon()
import threading
if __name__ == "__main__":
# 任何进程默认会启动一个线程,这个线程就是主线程。主线程可以启动新的子线程
# current_thread(): 返回当前线程的实例
# .name:当前线程的名称
print(threading.current_thread().name)
运行结果为:
MainThread
示例如下:
import threading
import time
def sing():
for i in range(3):
print("%d正在唱歌" % i)
time.sleep(1)
def dance():
for i in range(2):
print("%d正在跳舞" % i)
time.sleep(1)
if __name__ == "__main__":
print("主程序%s启动,时间是%d" % (threading.current_thread().name, time.time()))
t1 = threading.Thread(target=sing)
t2 = threading.Thread(target=dance)
t1.start()
t2.start()
while True:
length = len(threading.enumerate())
print("当前的线程数为%d" % length)
if length <= 1:
break
time.sleep(1)
运行结果为:
主程序MainThread启动,时间是1561709675
0正在唱歌
0正在跳舞
当前的线程数为3
当前的线程数为3
1正在唱歌
1正在跳舞
当前的线程数为3
2正在唱歌
当前的线程数为2
当前的线程数为1
**
9,创建线程的两种方式
**
1,通过threading.Thread直接在线程中运行函数
2,通过继承threading.Thread类来创建线程
通过继承的方式来创建线程,只需要重载threading.Thread类中的run()方法,然后start()开启线程就可以了
import threading
class MyThread(threading.Thread):
def run(self):
for i in range(5):
print(i)
if __name__ == "__main__":
t1 = MyThread()
t2 = MyThread()
t1.start()
t2.start()
运行结果为:
0
1
2
3
4
0
1
2
3
4
使用threading.Thread完成多线程任务
多线程中有一个全局解释器锁,同一时刻只能有一个线程执行
from threading import Thread
import random
import time
def download1():
for i in range(8, 11):
print("下载任务1完成%d%%" % i)
time.sleep(0.2)
def download2():
for i in range(8, 11):
print("下载任务2完成%d%%" % i)
time.sleep(0.2)
if __name__ == "__main__":
t1 = Thread(target=download1)
t2 = Thread(target=download2)
t1.start()
t2.start()
content = input("请输入内容:")
print(content)
# 主进程中写点代码
print("主进程执行完毕")
使用threading.Thread的子类创建多线程
import threading
import time
import random
class my_thread(threading.Thread):
def __init__(self, thread_id):
self.thread_id = thread_id
super().__init__()
def run(self):
for i in range(95, 101):
print("线程%d的下载进行%d%%" % (self.thread_id, i))
time.sleep(2)
if __name__ == "__main__":
t1 = my_thread(1)
t2 = my_thread(2)
t1.start()
t2.start()
print("线程的总数量为{0}".format(threading.active_count()))
print("主线程为{}".format(threading.main_thread().getName()))
**
9,使用多线程处理IO密集型的多任务
**
from threading import Thread
def run():
for i in range(5):
print("下载完成%d" % i)
if __name__ == "__main__":
t = Thread(target=run)
t.start()
content = input("请输入内容:")
print("输入的内容为",content)
运行结果为:
下载完成0
请输入内容:下载完成1
下载完成2
下载完成3
下载完成4
3
输入的内容为 3
从运行结果可以看出当执行输入输出操作任务时,执行到content语句时,主线程让出了CPU资源,子线程获得了CPU资源,继续执行并没有等待
使用多进程处理IO密集型的多任务的实验如下:
from multiprocessing import Process
def run():
for i in range(5):
print("下载完成%d" % i)
if __name__ == "__main__":
p = Process(target=run)
p.start()
content = input("请输入内容:")
print("输入的内容为",content)
运行结果为:
请输入内容:3
输入的内容为 3
下载完成0
下载完成1
下载完成2
下载完成3
下载完成4
从运行结果可以看出当执行到content语句时,阻塞了多任务的实现,只有当输入完成之后,主进程的代码才会跑,子进程的代码才会跟着跑
**
10,线程的生命周期(或称线程的状态)


**


**
11,线程数据同步 (死锁)
**
多线程中数据同步的问题。知识点:锁的应用
应用场景:多线程操作共享数据时,需要注意互斥锁的使用,来保证数据的完整性
互斥锁Lock 加锁,解锁
可重入锁RLock 加锁,解锁(了解)
1,在线程间共享多个资源的时候,如果两个线程分别占有一部分资源,并且同时等待对方的资源
就会造成死锁
2,到了死锁状态,可以使用Ctrl Z 退出



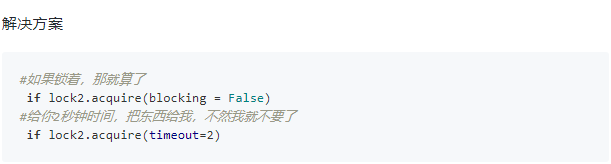
一个进程内的所有线程共享全局变量,多线程之间数据共享
缺点是:可能造成多个线程同时修改一个变量
互斥锁Lock的示例如下:
import threading
num = 0
def test1():
global num
if mutex.acquire(): # 调用Lock()对象获得锁 每次只有一个线程可以获得锁
for i in range(10):
num += i
print(num)
mutex.release() # 调用release()方法释放锁
def test2():
global num
if mutex.acquire(): #如果此时另外一个线程试图获得这个锁,该线程就会变为同步阻塞状态
for i in range(5):
num += i
print(num)
mutex.release()
if __name__ == "__main__":
mutex = threading.Lock()
p1 = threading.Thread(target=test1)
p1.start()
p2 = threading.Thread(target=test2)
p2.start()
print(num)
运行结果为:
45
55
55
from threading import Thread
from threading import Lock
tickets = 200
mutex = Lock()
def sale1():
mutex.acquire()
global tickets
for i in range(50):
tickets -= 1
print("t1执行完毕剩余车票%d" % tickets)
mutex.release()
def sale2():
mutex.acquire()
global tickets
for i in range(10):
tickets -= 1
print("t2执行完毕剩余车票为%d" % tickets)
mutex.release()
if __name__ == "__main__":
t1 = Thread(target=sale1)
t2 = Thread(target=sale2)
t2.start()
t1.start()
t1.join() #阻塞主线程,等着子线程执行结束
t2.join()
运行结果为:
t2执行完毕剩余车票为190
t1执行完毕剩余车票140
上面的代码不符合实际情况,优化后的代码如下:
from threading import Thread
from threading import Lock
tickets = 200
mutex = Lock()
def sale1():
global tickets
for i in range(50):
mutex.acquire()
tickets -= 1
mutex.release()
print("t1执行完毕剩余车票%d" % tickets)
def sale2():
global tickets
for i in range(10):
mutex.acquire()
tickets -= 1
mutex.release()
print("t2执行完毕剩余车票为%d" % tickets)
if __name__ == "__main__":
t1 = Thread(target=sale1)
t2 = Thread(target=sale2)
t2.start()
t1.start()
t1.join() # 阻塞主线程,等着子线程执行结束
t2.join()
**
12,线程数据同步和异步
**
1,同步调用:确定调用的顺序 互斥锁的应用
2,异步调用:不确定顺序


**
13,多线程间通信:生产者消费者模式
**
1,Python提供了queue这一线程安全的容器,可以方便的和多线程结合起来。 queue包括FIFO先入先出队列Queue,LIFO后入先出队列LifoQueue,和优先级队列PriorityQueue。
2,这些队列都实现了锁原语,能够在多线程中直接使用。可以使用队列来实现线程间的同步
from threading import Thread
from queue import Queue
import time
q = Queue(maxsize=10) # 最多容纳10个消息的队列
class Produce(Thread):
count = 0
def __init__(self, name):
super(Produce, self).__init__()#如果子类重写了构造函数,必须确保在对线程执行其他操作之前调用基类的构造函数
self.name = name
def run(self):
while True:
Produce.count += 1
result = "{0}生产的第{1}个包子".format(self.name, Produce.count)
q.put(result)
print(result)
if Produce.count ==11:
break
class Custom(Thread):
def __init__(self, name):
super(Custom, self).__init__()
self.name = name
def run(self):
while True:
if q.qsize() > 0:
r = q.get()
print("{0}吃了{1}".format(self.name, r))
else:
break
time.sleep(1)
if __name__ == "__main__":
t1 = Produce("张三")
t2 = Custom("李四")
t3 = Custom("王五")
t1.start()
t2.start()
t3.start()
运行结果为:
张三生产的第1个包子
张三生产的第2个包子
张三生产的第3个包子
李四吃了张三生产的第1个包子
张三生产的第4个包子
张三生产的第5个包子
王五吃了张三生产的第2个包子
张三生产的第6个包子
张三生产的第7个包子
张三生产的第8个包子
张三生产的第9个包子
张三生产的第10个包子
张三生产的第11个包子
李四吃了张三生产的第3个包子
王五吃了张三生产的第4个包子
王五吃了张三生产的第5个包子
李四吃了张三生产的第6个包子
王五吃了张三生产的第7个包子
李四吃了张三生产的第8个包子
李四吃了张三生产的第9个包子
王五吃了张三生产的第10个包子
李四吃了张三生产的第11个包子

**
14,协程
小知识:查看电脑上是否安装了greenlet模块 cmd---->pip list
协程的特点:是由用户控制的
用gevent实现协程的优点是:会自己根据事件来进行协程的自动切换
**


from greenlet import greenlet
import time
def test1():
print("12")
gr2.switch()
print("34")
gr2.switch()
def test2():
print("56")
gr1.switch()
print("78")
# 创建协程转换器
gr1 = greenlet(test1)
gr2 = greenlet(test2)
# 启动g1转换器
gr1.switch()
运行结果为:
12
56
34
78

import gevent
def method(n):
for i in range(n):
print(i, gevent.getcurrent())
ge1 = gevent.spawn(method, 5)
ge2 = gevent.spawn(method, 5)
ge3 = gevent.spawn(method, 5)
ge1.join()
ge2.join()
ge3.join()
注意:以上是顺序执行的代码
协程自动切换任务的演示代码如下:
import gevent
def method(n):
for i in range(n):
print(i, gevent.getcurrent())
gevent.sleep(1)
ge1 = gevent.spawn(method, 5)
ge2 = gevent.spawn(method, 5)
ge3 = gevent.spawn(method, 5)
ge1.join()
ge2.join()
ge3.join()
运行结果如下:
0 <Greenlet at 0x1f62cde1448: method(5)>
0 <Greenlet at 0x1f62cde1848: method(5)>
0 <Greenlet at 0x1f62cde1948: method(5)>
1 <Greenlet at 0x1f62cde1448: method(5)>
1 <Greenlet at 0x1f62cde1848: method(5)>
1 <Greenlet at 0x1f62cde1948: method(5)>
2 <Greenlet at 0x1f62cde1448: method(5)>
2 <Greenlet at 0x1f62cde1848: method(5)>
2 <Greenlet at 0x1f62cde1948: method(5)>
3 <Greenlet at 0x1f62cde1448: method(5)>
3 <Greenlet at 0x1f62cde1848: method(5)>
3 <Greenlet at 0x1f62cde1948: method(5)>
4 <Greenlet at 0x1f62cde1448: method(5)>
4 <Greenlet at 0x1f62cde1848: method(5)>
4 <Greenlet at 0x1f62cde1948: method(5)>

使用协程写一个并发下载器


















 451
451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









