






1. df_1是读取的csv, 拼接到df后,出现了两列id
2. df保存csv用excel打开显示下面这种乱码
3. 长数字自动被转换了科学计数法
df = pd.concat([df_1,df])
df.to_csv('data_full_1.csv',encoding='utf8',index_label= None)df = pd.concat([df_1,df])
df.to_csv('data_full_1.csv',index_label= None)
解决办法:
1. 保存csv的时候设置index_label即index的列名,在读取csv的时候也指定index_col即index列名
index 就正常了,只有一列
df_1 = pd.read_csv('data_full_1.csv',encoding='utf8',index_col='id')
df = pd.concat([df_1,df])
df.to_csv('data_full_1.csv', index_label='id')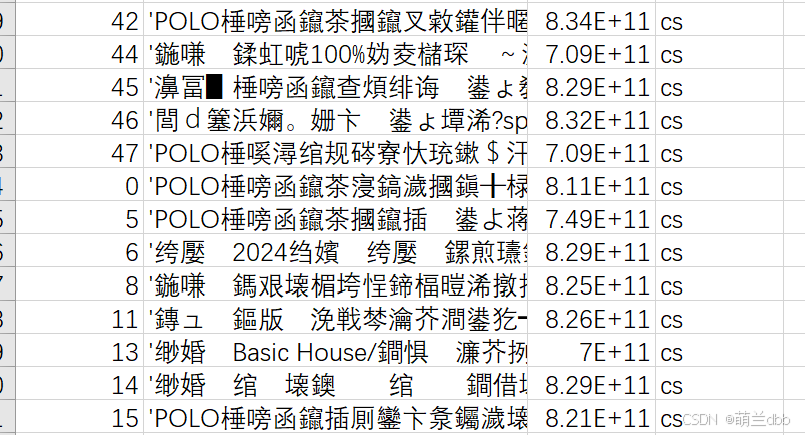
2. 乱码问题----设置 encoding='ANSI'
df_1 = pd.read_csv('data_full_1.csv', encoding='ANSI', index_col='id')
df = pd.concat([df_1, df])
df['img_id'] = df['img_id'].astype(str)
df.to_csv('data_full_1.csv', encoding='ANSI', index_label='id')3. 长数字避免被科学计数法---- str(数字)+'\t'
需要注意的一点是,需要再读取csv的时候且该数字字段不想变成int时,加上dtype={'img_id': str}
否则pd会默认转成int
df = pd.read_csv('data_full_1.csv',encoding='ANSI',index_col='id',dtype={'img_id': str,}) ![]()


















 5467
5467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









