







前言 顺序是按照上课接触的知识点展开的
回顾C++部分
一、结构体攻略
1.什么是结构体
数组(Array),它是一组具有相同类型的数据的集合。但在实际的编程过程中,我们往往还需要一组类型不同的数据,例如对于学生信息登记表,姓名为字符串,学号为整数,年龄为整数,所在的学习小组为字符,成绩为小数,因为数据类型不同,显然不能用一个数组来存放。
故而有了结构体的使用!结构体(关键字 Struct)可以用来存放一组不同类型的数据。结构体的定义形式为:
> struct 结构体名(即结构体类型){
> 结构体所包含的变量或数组
> }
结构体是一种集合,它里面包含了多个变量或数组,它们的类型可以相同,也可以不同,每个这样的变量或者数组都称为结构体的成员(Member)。
例如:
> struct stu{
> char name; //姓名
> int num; //学号
> int age; //年龄 char
> group; //所在学习小组
> float score; //成绩
> };
stu为结构体名,它包含了5个成员,分别是name、num、age、group、score。
ps:注意大括号后面的分号;不能少
2.结构体变量
既然结构体是一种数据,那么就可以用它来定义变量。例如:
struct stu stu1,stu2;
理解如下:
struct关键字声明了结构体类型stu,同时结构体类型stu定义了stu1和stu2结构体变量。两个变量stu1,stu2,他们都是stu类型,都分别由5个成员组成(name、num、age、group、score)。注意关键字struct不能少。
这里再举个例子:
#include <iostream>
using namespace std;
struct StructTest //自定义结构体类型
{
int t1; //创建结构体成员
int t2;
};
//typedef StructTest TEST;
int main()
{
StructTest my_Var; //定义结构体变量
//TEST my_Var;
cout << &my_Var << " " << &my_Var.t1 << " " << &my_Var.t2 << endl;
return 0;
}
输出结果:
006FFCF0 006FFCF0 006FFCF4
分析如下:
- 结构体是一种自定义的数据类型,是创建变量的模板,不占用内存空间;结构体变量才包含了实实在在的数据,需要内存空间来存储。即在
int t1,t2;这里不会分配内存,只有在StructTest my_Var;才开始分配内存。- 结构体和数据类似,也是一组数据的集合,整体使用没有太大意义。数据使用下标
[]获取单个元素,结构体使用点号.获取单个成员。获取结构体成员的一般格式为:
结构体变量.成员名;- main()是程序的入口
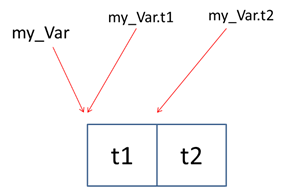
&表示取地址运算,故而&my_Var是表示取结构体变量my_Var的地址运算。
还有一点,结构体的名字(这里是my_Var)就是结构体变量的起始地址,即给my_Var赋值时要先从t1开始赋值,my_Var的输出结果与my_Var.t1的相同的。- 地址会默认转换为16进制,故而根据输出结果判定改结果为地址,故而明白
&在此处的意思是取地址运算。
3. 结构体在内存中的对齐规则
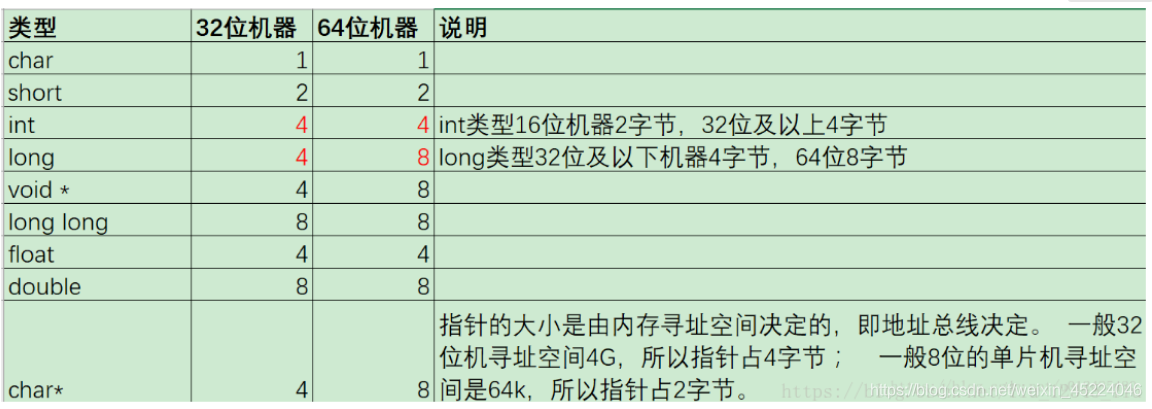
c++中基本数据类型的内存字节占比:
具体的对其规则详见下方链接:
https://blog.csdn.net/grantxx/article/details/7577730
此处谈一谈上方链接的最后一道题:
struct X{
char a;
int b;
double c;
};
struct Y {
char a;
X b;
};
经测试,可知sizeof(X)为16,sizeof(Y)为24。由第一原则和第二原则可知sizeof(X)的大小,而计算sizeof(Y)的大小,需要借助struct X。
struct Y中的X b;的计算要用向上取整法,向struct X看齐,取struct X的最宽元素长度double,而double的字节数为8,
故而可得在struct Y中,最宽的元素长度为8,首先系统会将字符变量 a 存入第0个字节(相对地址,指内存开辟的首地址);然后在存放 X 变量b 时,会以8个字节为单位进行存储,由于第一个八字节模块已有数据,因此它会存入第二个四字节模块,同时X类型本身占据16个字节,即sizeof(Y)=8+16=24.
二、指针攻略大全
1.先谈谈什么是指针
题外话
int p; 与 int *p;的区别
int p;是定义一个整型变量p,并且p里面放的全是整型(int)数据。
而int *p; 中*是起声明作用,声明变量p为指针变量,只能用来存放地址。
指针是一个特殊的变量,它里面存储的数值被解释成为内存里的一个地址。
要搞清楚一个指针就需要搞清楚指针四方面的内容:指针的类型,指针所指向的类型、指针的值或者叫做指针所指向的内存区,还有指针本身所占据的内存区。
先声明几个指针放着做例子:
例一:
int *ptr;
char *ptr;
int **ptr;
int (*ptr)[3];
int *(*ptr)[4];
2.开始深入——指针的类型
从语法的角度看,只要把指针声明语句里的指针名字去掉,剩下的部分就是这个指针的类型。这是指针本身所具有的类型。
例如:
int *ptr; //指针的类型是int *
char *ptr; //指针的类型是char *
int **ptr; //指针的类型是 int **
int (ptr)[3]; //指针的类型是 int()[3]
int *(*ptr)[4]; //指针的类型是 int ()[4]
3.继续深入——指针所指向的类型
当通过指针来访问指针所指向的内存区域时,指针所指向的类型决定了编译器将那片内存区里的内容当做什么来看待。
这里解释一下,什么是指针所指向的类型
int *a;
a是指针,int是什么呢?int是 指针a 指向 变量a为首地址的内存区域的类型。
从语法上看,只需要把指针声明语句里的指针名字和**名字左边的指针声明符***去掉,剩下的就是指针所指向的类型。
例如:
int *ptr; //指针所指向的类型是int
char *ptr; //指针所指向的的类型是char
int **ptr; //指针所指向的的类型是 int *
int (*ptr)[3]; //指针所指向的的类型是 int()[3]
int *(*ptr)[4]; //指针所指向的的类型是 int *()[4]
4.易混淆点——指针的值
指针的值是指针本身存储的数值,这个值被编译器当做一个内存区域的首地址,而不是一个一般的数值。、
指针所指向的内存区域就是从指针的值所代表的那个内存地址开始,长度为sizeof(指针所指向的类型)的一篇内存区。
(sizeof的用法可以看结构体那部分)
例如:
一个指针的值为a,则说明 该指针指向以a为首地址的一片内存区域;
一个指针指向某块内存区域,则说明 该指针的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2294
2294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









