







创建连接
sqlalchemy应用必须创建一个engine,用于连接数据库;
from sqlalchemy import create_engine
# 创建engine, 懒连接,在ORM中由Session管理
engine = create_engine("sqlite+pysqlite:///:memory:", echo=True, future=True)
# echo 表示sqlalchemy的日志 输出到控制台
# future,表示使用 sqlalchemy2.0 风格的接口
# 连接sqlite (内存)数据库,使用pysqlite DB API,即sqlite3
# 内存数据库,不用创建数据库文件,也不用连接其他的数据库服务器
# 真实创建连接(并开启事务)
conn = engine.connect() # 建议使用python的上下文管理器操作
cursor = conn.exec_driver_sql("select * from stu;")
cursor.fetchall()
conn.commit()/rollback()
事务和DBAPI
- engine.connect() 创建连接,并开启事务;
# 上下文管理器
with engine.connect() as conn:
# 开启事务
conn.exec_driver_sql("create table jack(id int, name varchar(20))")
conn.exec_driver_sql("insert into jack values(1, 'jack1')")
conn.exec_driver_sql("insert into jack values(2, 'jack2')")
# 提交事务
conn.commit()
# with作用域结束时,若未提交事务,则回滚(engine.connect())
- 直接调用conn.execute() 执行text(sql)
conn.exec_driver_sql() 执行sql
from sqlalchemy import text
# 真实连接
with engine.connect() as conn:
# sql 语句包裹在 text
conn.execute(text("CREATE TABLE some_table (x int, y int)"))
conn.execute(
text("INSERT INTO some_table (x, y) VALUES (:x, :y)"),
[{"x": 1, "y": 1}, {"x": 2, "y": 4}],
)
# 所有的操作 在事务内部(with作用域)
conn.commit()
- engine.begin() 开启事务,并自动提交事务
with engine.begin() as conn:
conn.exec_driver_sql("create table user(id int, name varchar(30))")
# with作用域结束,自动提交事务
- conn.execute()执行文本sql,实现增删改查.
with engine.connect() as conn: # 创建连接,开启事务
conn.execute(text("create table if not exists laufing(id int, name varchar(40))"))
conn.execute(text("insert into laufing values (1, 'jack')"))
# 查询返回CursorResult对象
result = conn.execute(text("select * from laufing"))
print("result:", result, type(result))
# 获取结果
print("data:", result.fetchone()) # data: (1, 'jack')
print("data:", result.fetchall()) # data: [(1, 'jack')]
# 遍历获取
for row in result: # 只能遍历一次 result.mappings() 每行转为字典
# row is Row obj,也是命名的元组,所以可以像元组一样遍历或者取值
print(row.id, row.name) # row[0], row[1]
# 条件查询 :字段名 占位符 参数化的sql --与原生sql ? 占位符类似
# 查询 y > 2 的所有数据
result = conn.execute(text("SELECT x, y FROM some_table WHERE y > :y"), {"y": 2})
# 向laufing表中插入多条数据(参数化)
conn.execute(text("insert into laufing values (:id, :name)"), [{"id": 2, "name":"lucy"}, {"id": 3, "name": "lili"}])
# 更新
conn.execute(text("update laufing set name='xxx' where id > 5"))
# 删除
conn.execute(text("delete from laufing where id > 5"))
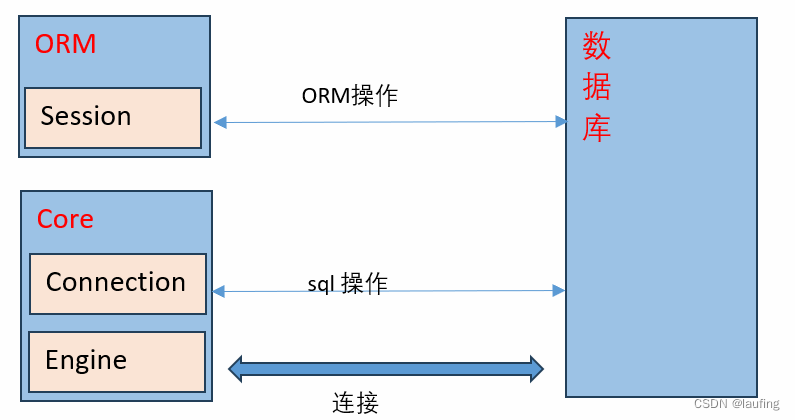
ORM 操作
- Core sql操作 使用Connection 对象;
- ORM 与 数据库 交互,使用Session对象,底层依赖Connection对象触发sql;
- 两者的底层均为Engine对象;
- ORM 将类 映射为表;类属性映射为表字段;类对象映射为表记录;通过对实例对象的操作,实现数据库的增删改查。
session的使用
from sqlalchemy import text
from sqlalchemy.orm import Session, sessionmaker
# 上下文管理器
with Session(engine) as session: # 开启会话,并创建事务
# 每次执行sql时,从engine 获取一个新的Connection对象
session.execute(text(sql))
# 提交事务
session.commit()
# with作用域结束 则关闭会话session.close()
# 或者
S = sessionmaker(engine) # 返回一个类
session = S()
session.execute(text(sql))
session.commit() # 写入数据时, 提交事务;查询则不用
session.close()
# 上下文管理器
with Session.begin() as session: # Session类调用begin()
session.add(some_object)
session.add(some_other_object)
# 无异常则提交事务,关闭会话
# 一般使用格式
with Session(engine) as session:
# 开启事务
session.begin()
# 异常捕获
try:
session.add(some_object) # 添加一个对象
session.add(some_other_object)
session.add_all([obj1, obj2]) # 添加多个对象
except: # 捕获到异常 则回滚
session.rollback()
raise
else:
session.commit() # 没有异常则提交
#
# 简便形式
with Session(engine) as session:
with session.begin(): # 开启事务
session.add(some_object)
session.add(some_other_object)
# inner context calls session.commit() - 无异常时,自动提交事务
# outer context calls session.close()
# 以上再简写
with Session(engine) as session, session.begin():
session.add(some_object)
session.add(some_other_object)
- 基于session的查询
# 查询User模型类 的所有字段,(name为ed的)
results = session.query(User).filter_by(name="ed").all() # 返回对象列表
# 查询多个类
results = session.query(User, Address)
.join("addresses") # 通过User中 与Address 的关系 连接
.filter(User.name=="jack") # 过滤
.all() # [(jack, 北京), (jack, 河南)] 对象元组 列表
# query using orm-columns, also returns tuples
results = session.query(User.name, User.fullname).all()
表关系
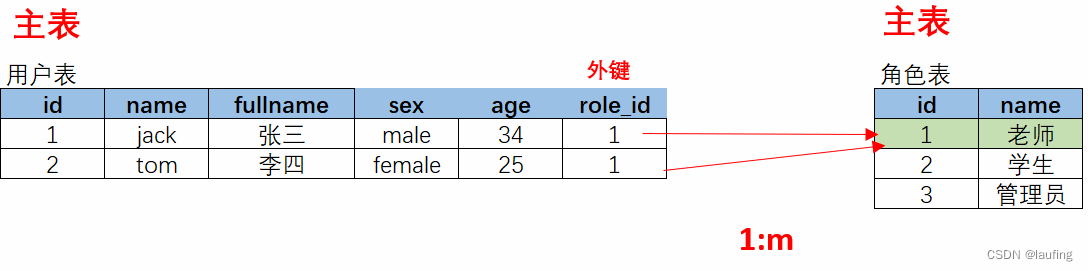
- 1:1,表A 中的一条记录,仅对应表B中的一条记录;表B的一条记录,仅对应表A的一条记录。
- 1:m,表A中的一条记录,对应表B中的多条记录,表B中的一条记录,仅对应表A的中的一条;(多的一方创建外键)
- m:n ,表A 中的一条记录,可对应表B中的多条记录;表B的一条记录,也可对应表A的多条记录。
ORM表示 1v1
pass
ORM表示 1vm
- 表结构


- 创建模型类
from sqlalchemy import Column, Integer, Float, String, Enum, ForeignKey, VARCHAR
from sqlalchemy.dialects.mysql import VARCHAR
from sqlalchemy.orm import declarative_base, relationship, Session, sessionmaker # sessionmaker返回一个会话类
from sqlalchemy import create_engine
# base class
Base = declarative_base()
# Address
class Address(Base):
__tablename__ = "address_t"
id = Column(Integer, primary_key=True)
# 地址字段, mysql数据库使用VARCHAR类型,其他使用String类型
title = Column("address", String(50).with_variant(VARCHAR(50, charset="utf8"), "mysql"), nullable=False)
# 外键
user_id = Column(Integer, ForeignKey("user_t.id"), nullable=True)
# 关系(非表字段),模型类之间的引用
# back_populates 双向的 反向引用(通过属性)
# 旧版本的反向引用backref,只在主表中,它是单向的子表到主表的引用
# cascade 级联动作 delete-orphan 表示子表断开引用主表时,删除记录,仅用于1:m 中1的一方
user = relationship("User", back_populates="addresses")
def __repr__(self): # 打印对象时的输出
return f"{self.title}"
# User
class User(Base):
__tablename__ = "user_t"
id = Column(Integer, primary_key=True)
name = Column(String(30), unique=True)
fullname = Column(String(50))
# 枚举
sex = Column(Enum("male", "female", name="sex"))
age = Column(Integer)
role_id = Column(Integer, ForeignKey("role_t.id"), nullable=True)
# 关系
addresses = relationship("Address", back_populates="user", cascade="all, delete-orphan", order_by=Address.id)
# 以上的user、addresses 两个关系可以使用backref定义
# addresses = relationship("Address", backref="user")
# backref 会在Address 中定义一个user属性,用于获取用户
role = relationship("Role", back_populates="users")
def __repr__(self):
return f"{self.name}"
# Role
class Role(Base):
__tablename__ = "role_t"
id = Column(Integer, primary_key=True)
name = Column(String(30), unique=True)
# 关系
users = relationship("User", back_populates="role")
def __repr__(self):
return f"{self.name!r}"
# 创建懒连接
sqlalchemy_database_uri = "postgresql://user:pw@ip:port/dbxx"
engine = create_engine(sqlalchemy_database_uri, echo=True)
# 删除所有的表
Base.metadata.drop_all(engine)
# 创建所有的表
Base.metadata.create_all(engine) # 若表已存在,则跳过
# 创建会话
with Session(engine) as session:
jack = User(name="jack", fullname="张三", sex="male", age=34, addresses=[Address(title="北京"), Address(title="河南")])
tom = User(name="tom", fullname="李四", sex="female", age=25, addresses=[Address(title="武汉")])
# 创建角色
role = Role(name="老师", users=[jack, tom])
# 仅仅添加一个****主表记录**** 即可,子表记录 连带添加
session.add(role)
session.commit() # 事务的最终提交
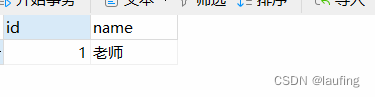
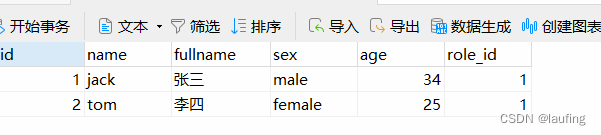
主表记录插入时,连带子表记录一起插入。
设置user_id时,若对应的数据不在表中,则可以使用关系赋值。
Working with Related Objects
https://docs.sqlalchemy.org/en/14/orm/tutorial.html

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











