








Dijkstra是用于计算从一个顶点到其余各顶点的最短路径算法(构建单源点的最短路径树),解决的是有权图中最短路径问题。由于每次都会选取当前起点以及经过中间点到目标点的最短距离,而不考虑其他未知点的因素,故而是一个基于局部最优解的贪心策略。因而,每当在已经确定的集合S中加入新的顶点v,都需要重新更新起点到其他点的最短距离。
Dijkstra其实和Prim(普利姆)算法极其相似,但是Prim是构造一个图中的最小生成树,类似于在一个图中找出一条连接所有顶点的最短路径,而Dijkstra是找出起点到其他顶点的最短路径。
Dijkstra的算法步骤如下,
1). 初始化 visit[ ] 数组,记录未被浏览的点位为-1, dist[ ] 初始化,记录x点到其他点的距离,所有不可达的权重为-1(本文中,自己本身也设置为-1)
然后初始化第一个点x,设置visit[x] = 0
2). 遍历 dist[ ] 从顶点集合中选出当前x中到达下一个点中的最短路径 ,并记录N点最小值的index 和 minNum(也就是到达该最小点的权重, 并对应在 visit[ ] 修改为其他值,以区分已经访问过的点)
3). 更新 dist[ ] 修改从源点x出发到其他店的距离,若有如下关系 dist[J] > dist[index] + dist[index]J则更新 dist[J]的值
4). 重复2,3步骤 n-1(初始点不用遍历) 次,遍历完剩余的所有点后,算法完成。
本次的示例图如下:
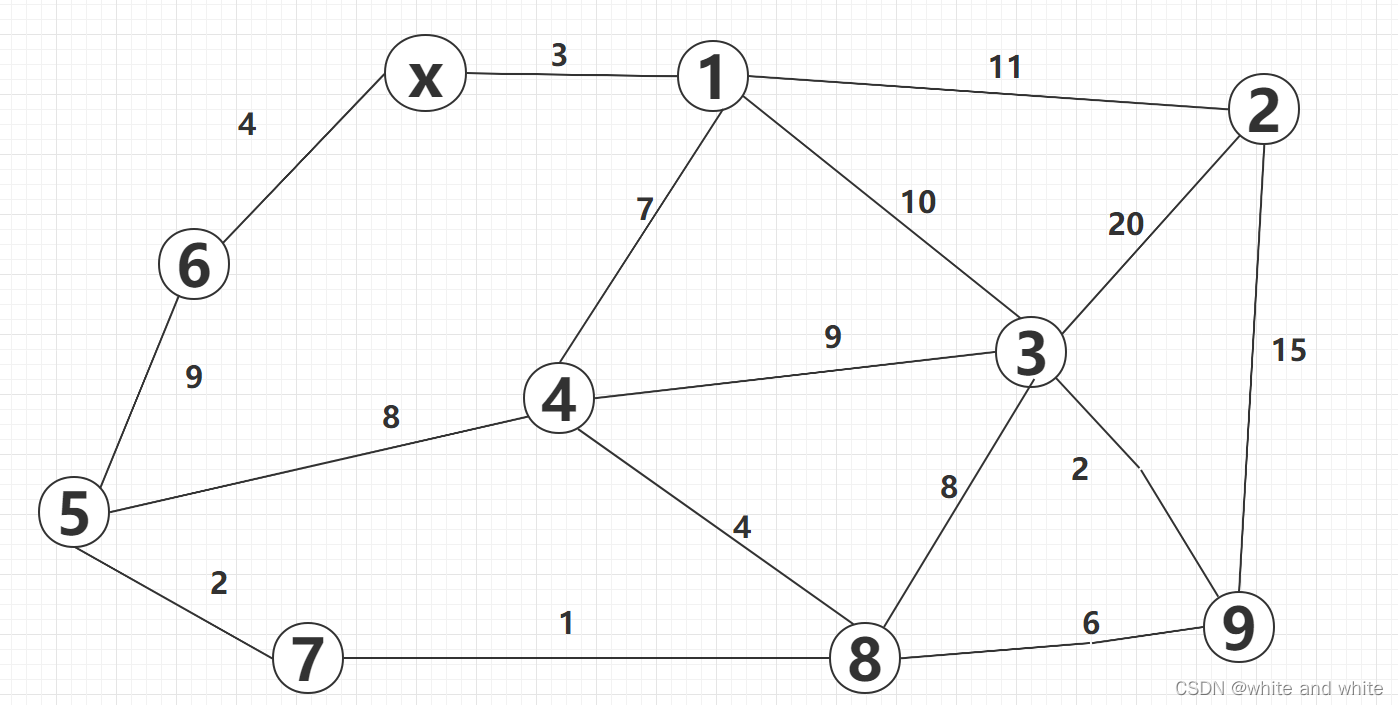
图中以x为源点,开始寻找
第一轮:X相连的只有index为 1和6,故有J = 1, 且dist[J]:

更新后的图像应该是这样的,以及对应的 visit数组和dist数组:


第二轮加入1这个中间点后,再次遍历dist更新,找到的是6:
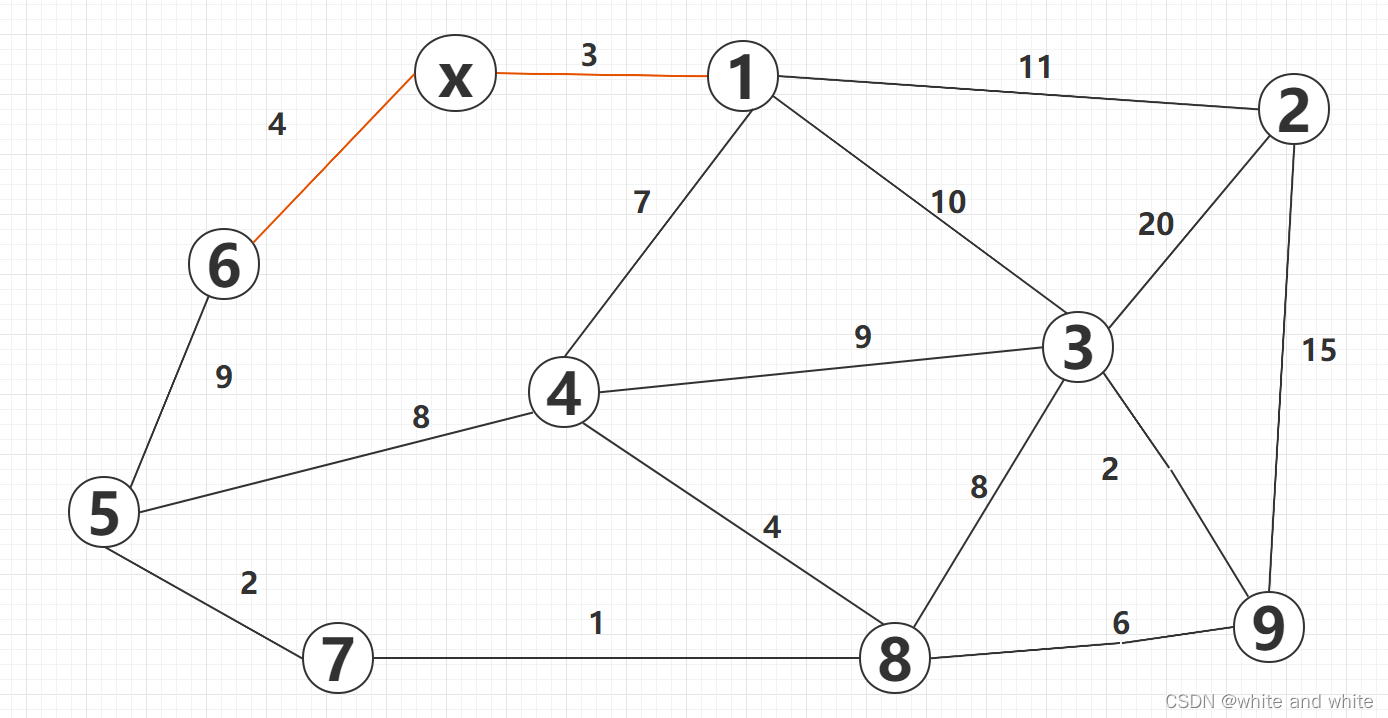
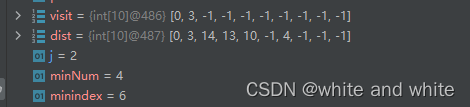
同样更新后是这样的:

接着第三轮就是这样的:
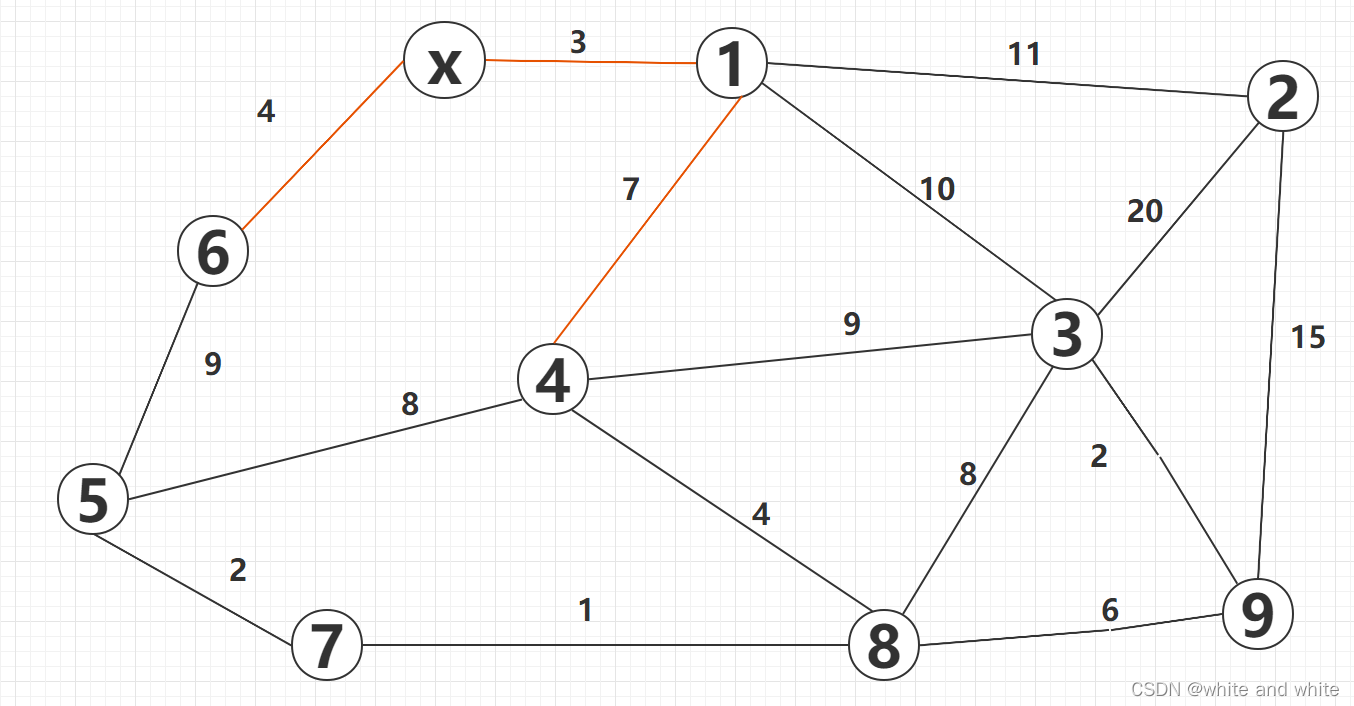
dist[4]中 =10 是为什么呢?因为这是计算从 源点x 到4这个点的距离,也就是说要把 从x开始经过的 1 还有 1-4这个点的权重给加起来,这也是和Prim算法中的差异之处
接下来不逐一放出程序的断点变量变化过程,直接放图---------------------------------------------
第四轮:
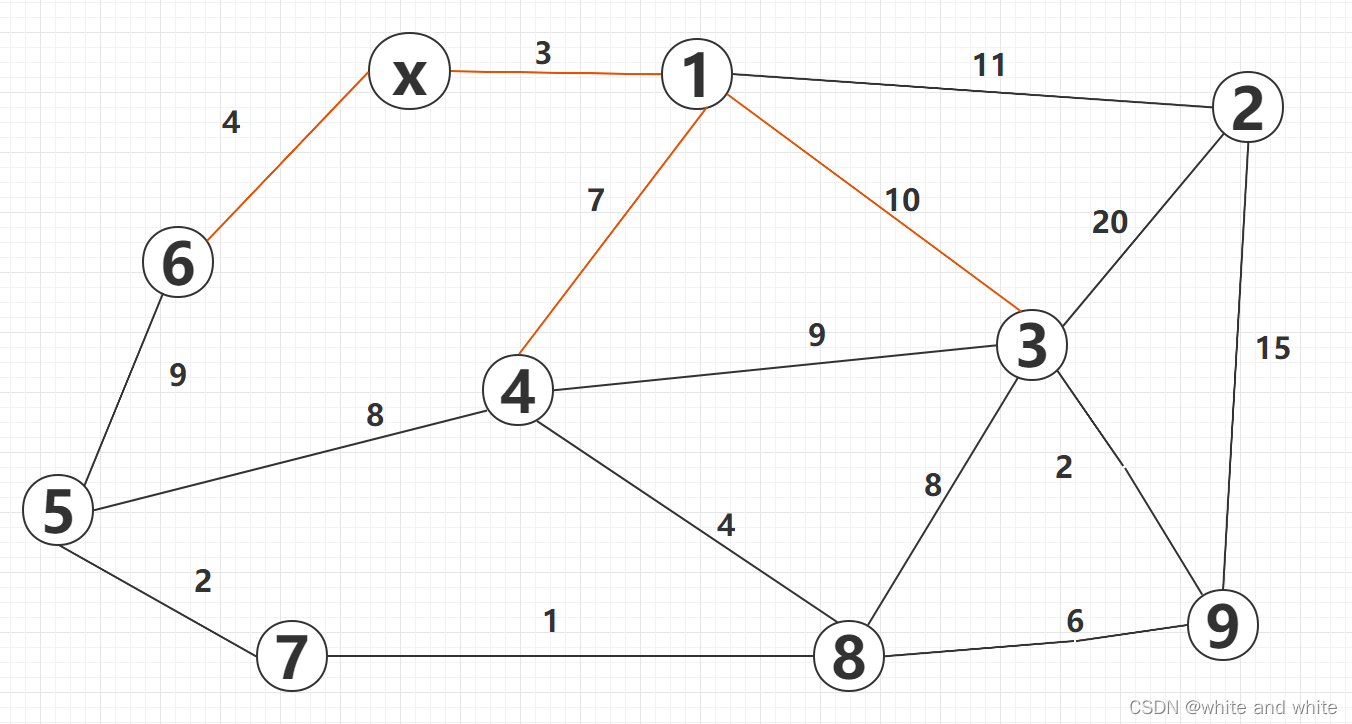
第五轮:
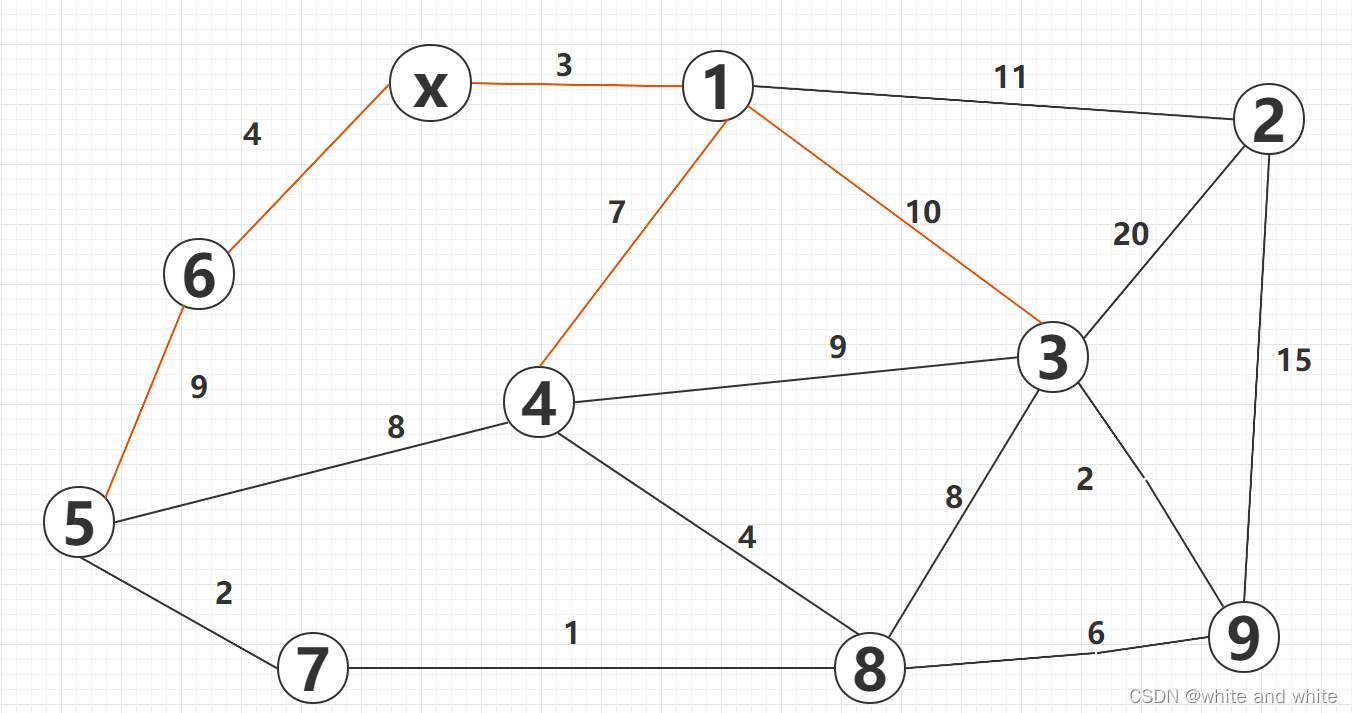
第六轮:
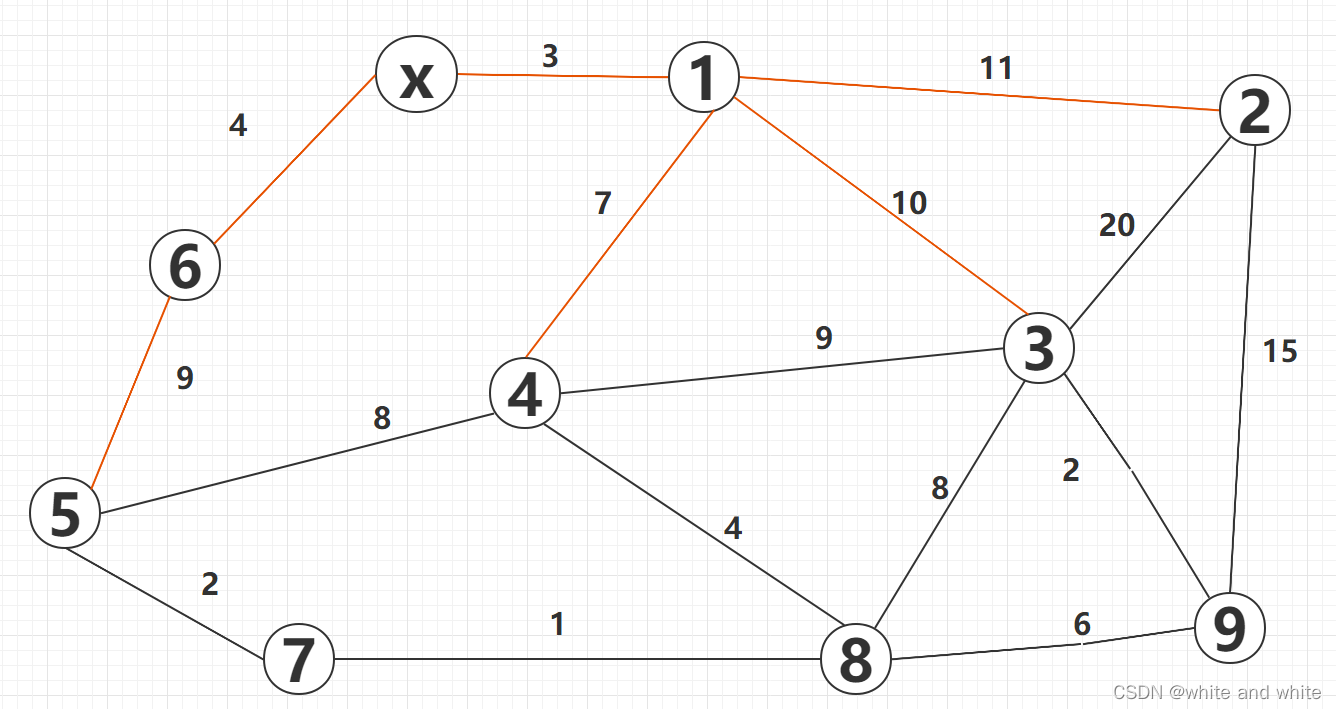
第七轮:
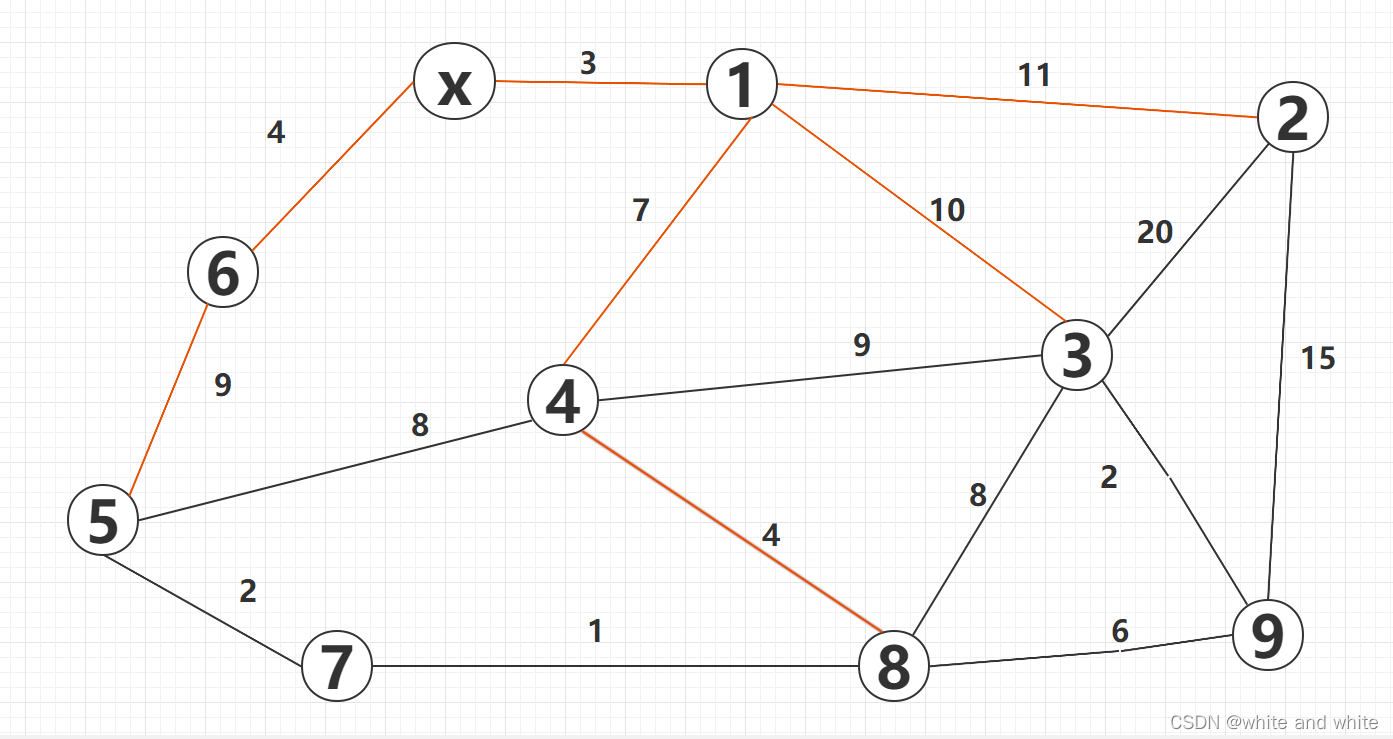
第八轮:
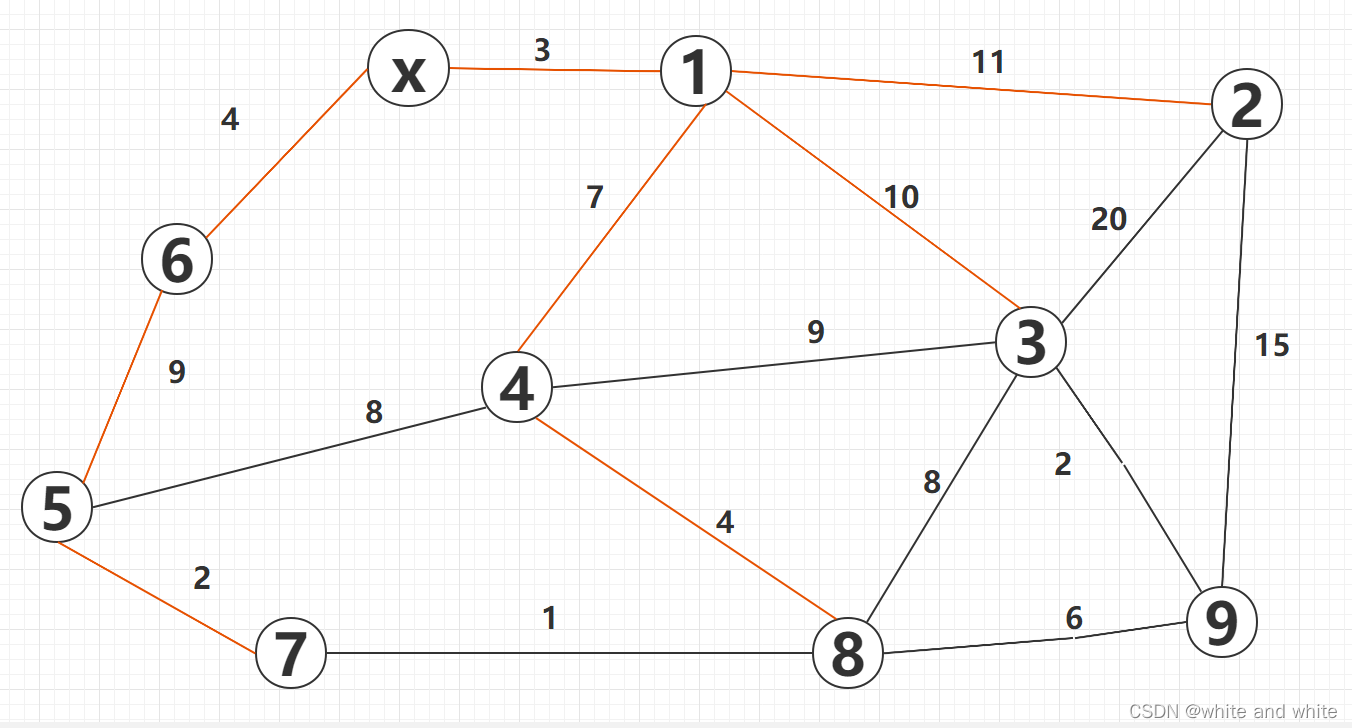
第九轮,完毕!
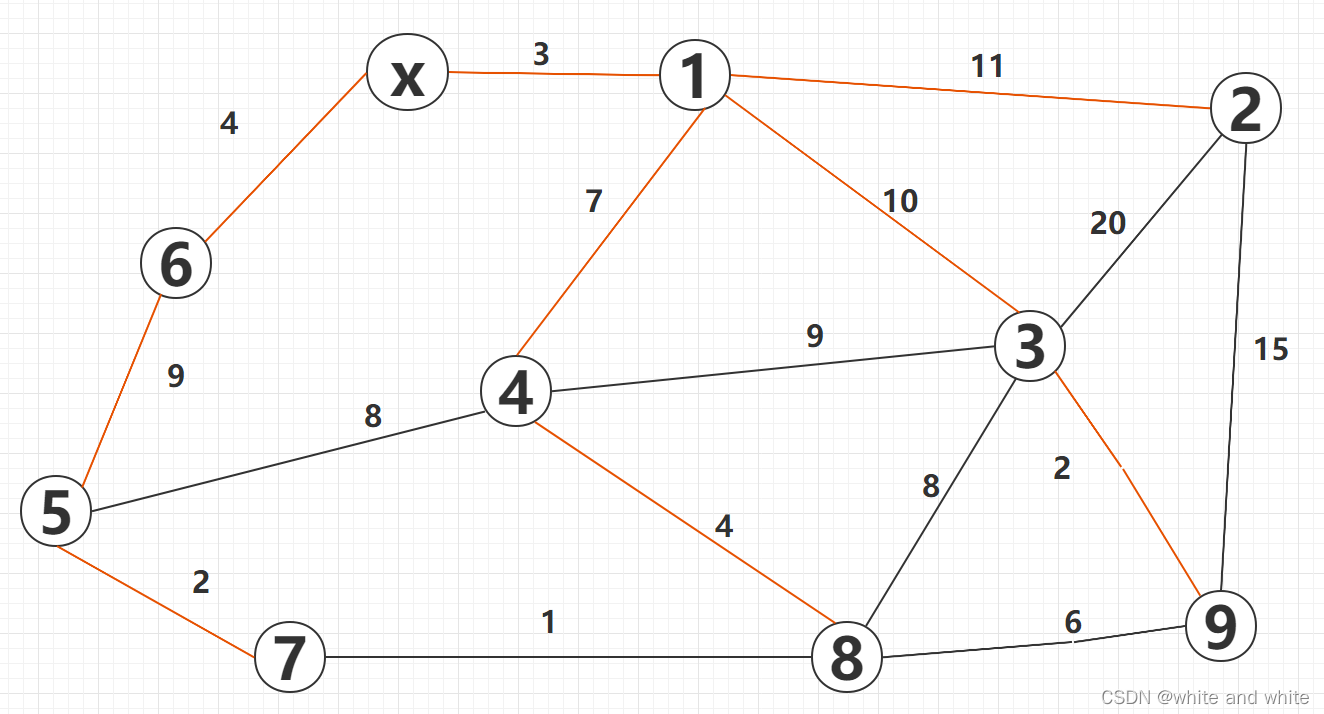
这样就可以得出所有从x出发到其他点的最短距离了:

初始化的代码如下,其中,startIndex是说改数据以哪个点作为起点
int startIndex = 0;
grape[startIndex][startIndex] = 0;
//得到点的个数
int points = grape.length;
//已确定最短路径的点集合
int[] visit = new int[points];
//到其他点的路径长度(权重)
int[] dist = new int[points];
//初始化未检索的集合
for(int i = 0;i<points;i++){
visit[i] = -1;
}
//初始化第一个点
visit[startIndex] = 0;
//初始化startIndex到其他点的距离,
for(int i = 0;i < points ;i++){
dist[i] = grape[startIndex][i];
}
下面是遍历dist数组,找出当前最小边,作为最短路径
//更新确定的集合,并且记录当前最短下标
int minNum = Integer.MAX_VALUE;
int minindex = startIndex;
for(int k = 0;k<points;k++){
//当前dist中有-1的都是为无穷长,以为浏览过,剔除,寻找剩余最短的点,记录其index
if(dist[k]!=-1&&visit[k]==-1&&minNum>dist[k]){
minNum = dist[k];
minindex = k;
}
}
//加入确定的集合
visit[minindex] = minNum;
接着就是前文的第三步,对 dist[J] > dist[index] + dist[index][J]作为一个判断,每次加入的点都要更新dist
//加入新点后,更新dist,遍历新节点到其他点的距离(grape代替)
for(int column = 0;column < points ;column++){
//判断是否有权重
if(grape[minindex][column]!=-1){
//判断startindex节点出发或者从最新的minindex(中转点出发)到目标点的距离更小,而原本为-1(不可达),则直接置换新权重
int x = dist[minindex] + grape[minindex][column];
if(dist[column] == -1 || dist[column]>x){
dist[column] = x;
}
}
}
最后完整的代码如下:
public static void main(String[] args) {
int[][] graph ={
{-1, 3,-1,-1,-1,-1, 4,-1,-1,-1},
{ 3,-1,11,10, 7,-1,-1,-1,-1,-1},
{-1,11,-1,20,-1,-1,-1,-1,-1,15},
{-1,10,20,-1, 9,-1,-1,-1, 8, 2},
{-1, 7,-1, 9,-1, 8,-1,-1, 4,-1},
{-1,-1,-1,-1, 8,-1, 9, 2,-1,-1},
{ 4,-1,-1,-1,-1, 9,-1,-1,-1,-1},
{-1,-1,-1,-1,-1, 2,-1,-1, 1,-1},
{-1,-1,-1, 8, 4,-1,-1, 1,-1, 6},
{-1,-1,15, 2,-1,-1,-1,-1, 6,-1}
};
System.out.println(dijkstra(graph));
}
public static int dijkstra(int[][] grape){
int startIndex = 0;
grape[startIndex][startIndex] = 0;
//得到点的个数
int points = grape.length;
//已确定最短路径的点集合
int[] visit = new int[points];
//到其他点的路径长度(权重)
int[] dist = new int[points];
//初始化未检索的集合
for(int i = 0;i<points;i++){
visit[i] = -1;
}
//初始化第一个点
visit[startIndex] = 0;
//初始化startIndex到其他点的距离,
for(int i = 0;i < points ;i++){
dist[i] = grape[startIndex][i];
}
//遍历
for(int j = 1;j<points;j++){
//更新确定的集合,并且记录当前最短下标
int minNum = Integer.MAX_VALUE;
int minindex = startIndex;
for(int k = 0;k<points;k++){
//当前dist中有-1的都是为无穷长,以为浏览过,剔除,寻找剩余最短的点,记录其index
if(dist[k]!=-1&&visit[k]==-1&&minNum>dist[k]){
minNum = dist[k];
minindex = k;
}
}
//加入确定的集合
visit[minindex] = minNum;
//加入新点后,更新dist,遍历新节点到其他点的距离(grape代替)
for(int column = 0;column < points ;column++){
//判断是否有权重
if(grape[minindex][column]!=-1){
//判断startindex节点出发或者从最新的minindex(中转点出发)到目标点的距离更小,而原本为-1(不可达),则直接置换新权重
int x = dist[minindex] + grape[minindex][column];
if(dist[column] == -1 || dist[column]>x){
dist[column] = x;
}
}
}
}
int res = 0;
for (int n = 0;n<points;n++){
res = res + dist[n];
System.out.print(dist[n]+" ");
}
return res;
}
不过Dijkstra还是有不适用的情况,比如权重为负值的时候,因为这会导致原来已经更新好的 dist[ ] 发生新的变化,会产生加上未来的边后比原来得出的最短路径还要短
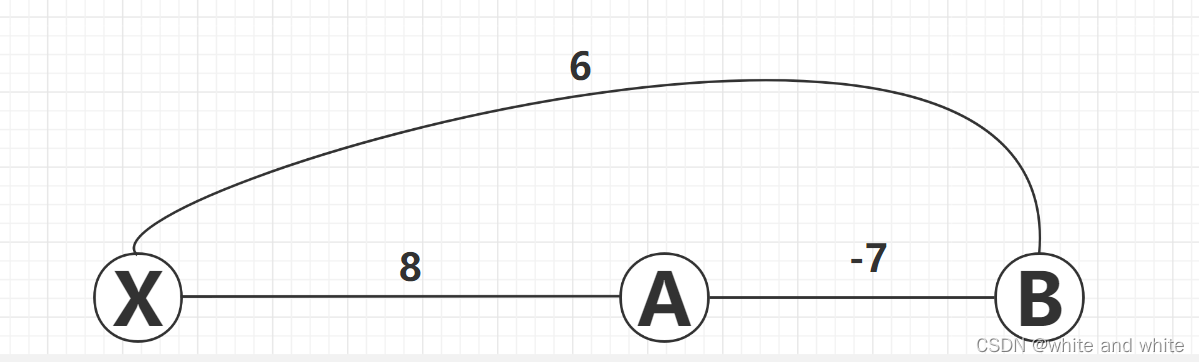 按照Dijkstra算法,第一步X出发肯定会选择 权重为6 的到B的这条边,可是如果按照下面这条边的走法,X --> B的距离是1 ,远小于Dijkstra算法选择的 权重为6的这条边
按照Dijkstra算法,第一步X出发肯定会选择 权重为6 的到B的这条边,可是如果按照下面这条边的走法,X --> B的距离是1 ,远小于Dijkstra算法选择的 权重为6的这条边















 1400
1400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









