







文章目录
硬件基础知识
了解CPU的制作过程
沙子脱氧 -> 石英 -> 二氧化硅 -> 提纯 -> 硅锭 -> 切割 -> 晶圆 -> 涂抹光刻胶 -> 光刻 -> 蚀刻 -> 清除光刻胶 -> 电镀-> 抛光 -> 铜层 -> 测试 -> 切片 -> 封装
简单理解:一堆沙子 + 一堆铜 + 一堆胶水 + 特定金属添加 + 特殊工艺
Intel cpu的制作过程(视频讲解)
CPU是如何制作的(图文讲解)
了解CPU的原理
计算机需要解决的最根本问题:如何代表数字,就有牛人发现电可以代表数字,通电代表1断电代表0,称之为逻辑开关。
不同的电路组成不同的逻辑开关,形成不同的基础逻辑计算,与门 或门 非门 或非门(异或),cpu内部使用振荡器(时钟发生器)来不断通电断电来做运算,实现手动计算(通电一次,运行一次位运算),加入内存 实现自动运算(每次读取内存指令,内存中存的就是电信号(高电低电))。
那么对应硬件层面怎么代表01?
牛人就提出采用二极管,就是那种小灯泡,通电亮那种,这也就是为什么最早的一台计算机有一间房那么大了。但是不断通断电二极管很容易烧坏,就有了晶体管,不但体积很小而且耐造。
晶体管的工作原理(视频)
cpu的运算只认识电信号,对应01,如果说只能用0和1区编写程序那是不是太麻烦而且门槛太高了。不过最早的程序员真的就是01这样编程的。于是就诞生了汇编语言。
了解汇编语言(机器语言)
汇编语言的本质:机器语言的助记符 其实它就是机器语言,助记符就是规定用特定一些词来代表01的代码,比如加操作对应二进制为01001000那么就规定个助记符为add,见到add就知道这是个加操作了。
执行过程: 计算机通电 -> CPU读取内存中程序(电信号输入)->时钟发生器不断震荡通断电
->推动CPU内部一步一步执行(执行多少步取决于指令需要的时钟周期)->计算完成->写回(电信号)->写给显卡输出(sout,或者图形)
Java相关硬件知识
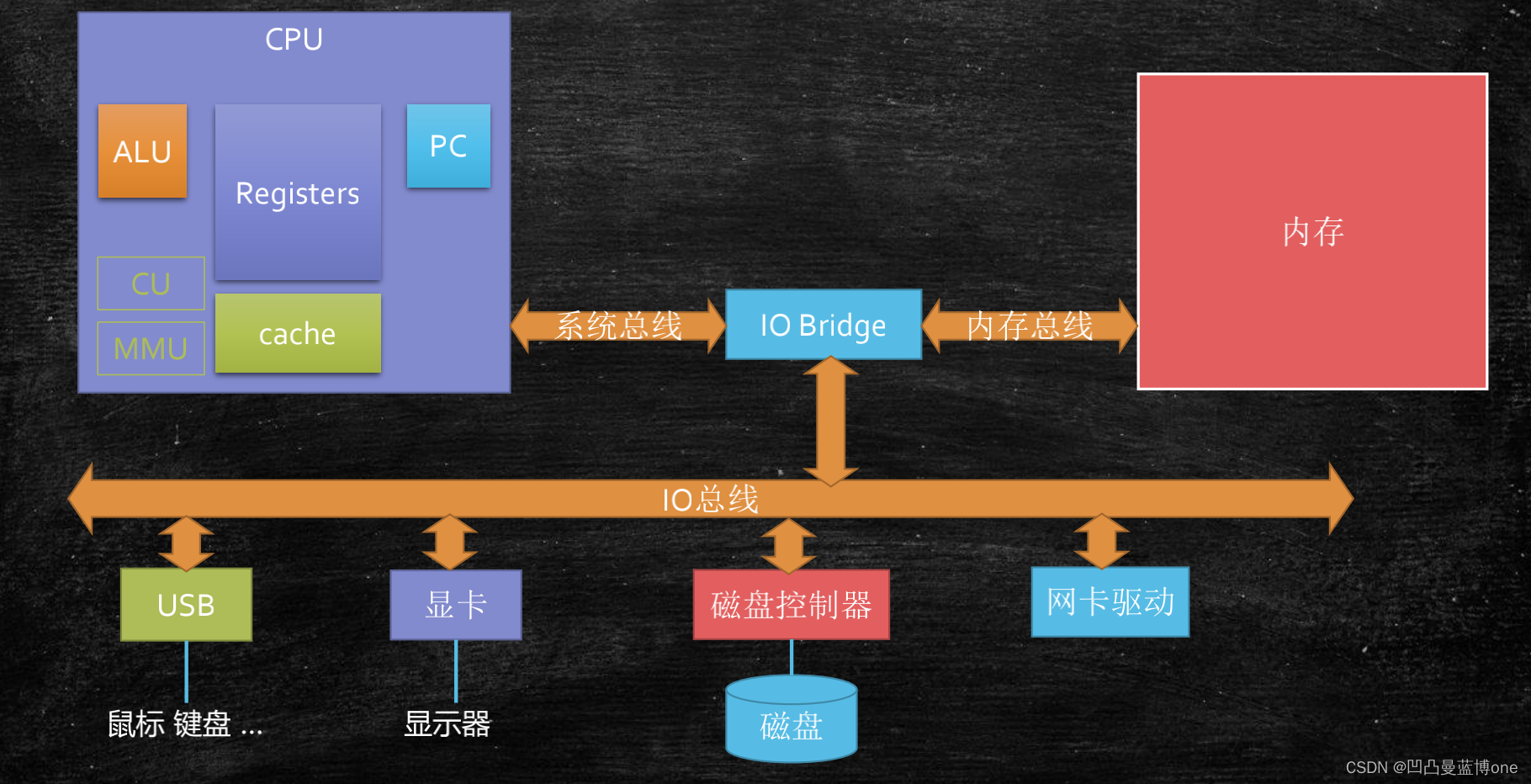
计算机的组成
计算机核心是一个主板,连接各种元器件的东西,如cpu,内存条,显卡,网卡等。cpu和内存,是计算机的核心。
cpu基本的逻辑组成:
PC:Program Counter 程序计数器 (记录当前指令地址)
Registers:寄存器,暂时存储CPU计算需要用到的数据
ALU :Arithmetic & Logic Unit 运算逻辑单元,就是做运算用的
CU:Control Unit 控制单元,对中断信号等的控制
MMU: Memory Management Unit 内存管理单元
cache:缓存
超线程
一个ALU对应多个PC | Registers。所谓的四核八线程

存储器的层次结构
因为cpu的速度太快了,内存速度太慢了,为了提高cpu的效率,不让cpu等内存拿数据,就有了三层高速缓存L1,L2,L3。
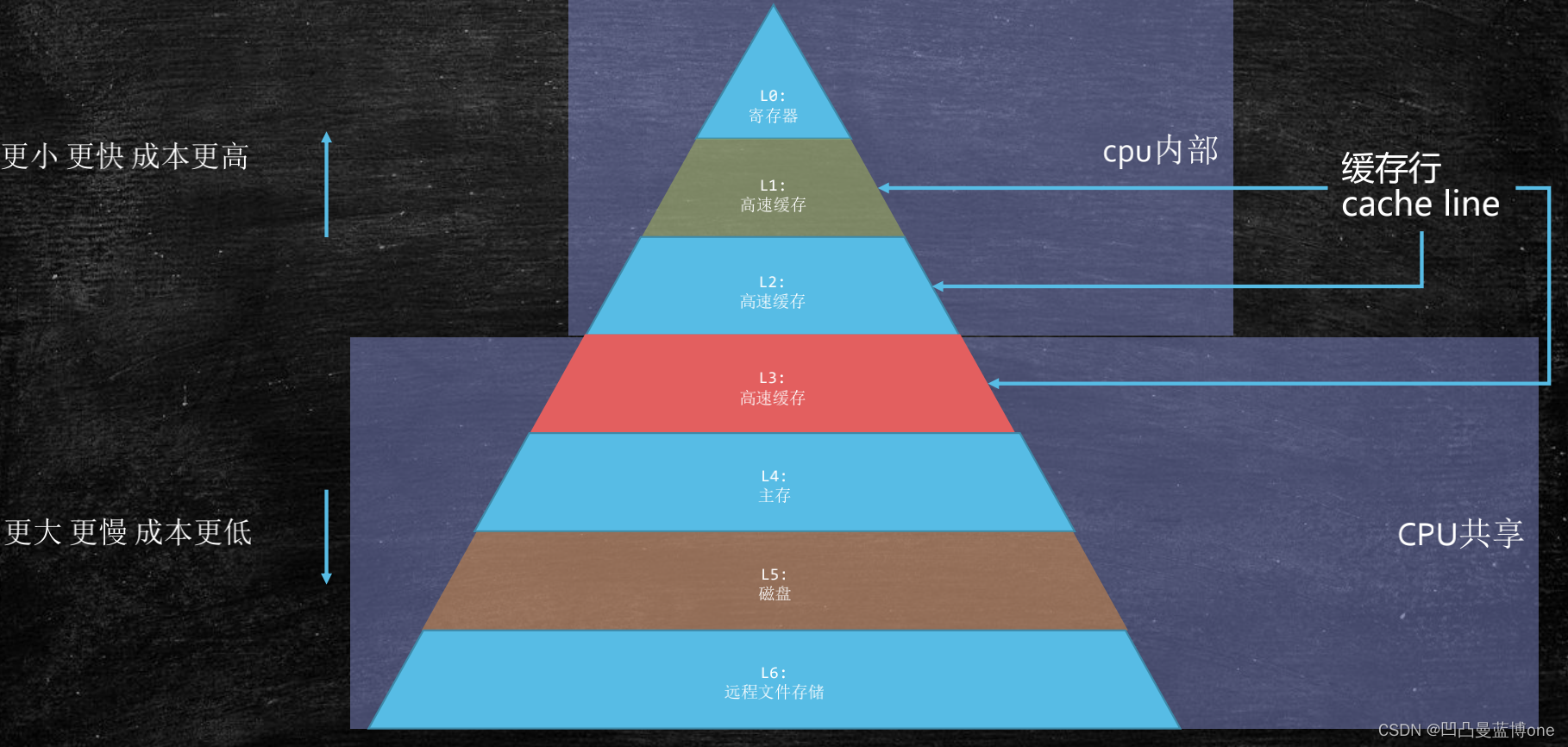
从CPU的计算单元(ALU)到不同层次的访问速度:

缓存
按块读取
程序局部性原理,可以提高效率
充分发挥总线 CPU针脚等一次性读取更多数据的能力
cache line的概念 缓存行对齐 伪共享:
例如:ALU计算需要y值会先从L1找,没有去L2找,L2没有再去L3找,三层高速缓存都没有的话,就去主存中找,拿数据的时候不只是只拿一个y值,而是把y值存在于的这一块数据都拿过来,一层层的返回。如果两个ALU都拿到相同的数据块做计算,那么就存在数据不一致的问题,这是就需要遵循缓存一致性协议来保证数据一致。
英特尔采用的缓存一致性协议是:MESI Cache一致性协议
https://www.cnblogs.com/z00377750/p/9180644.html
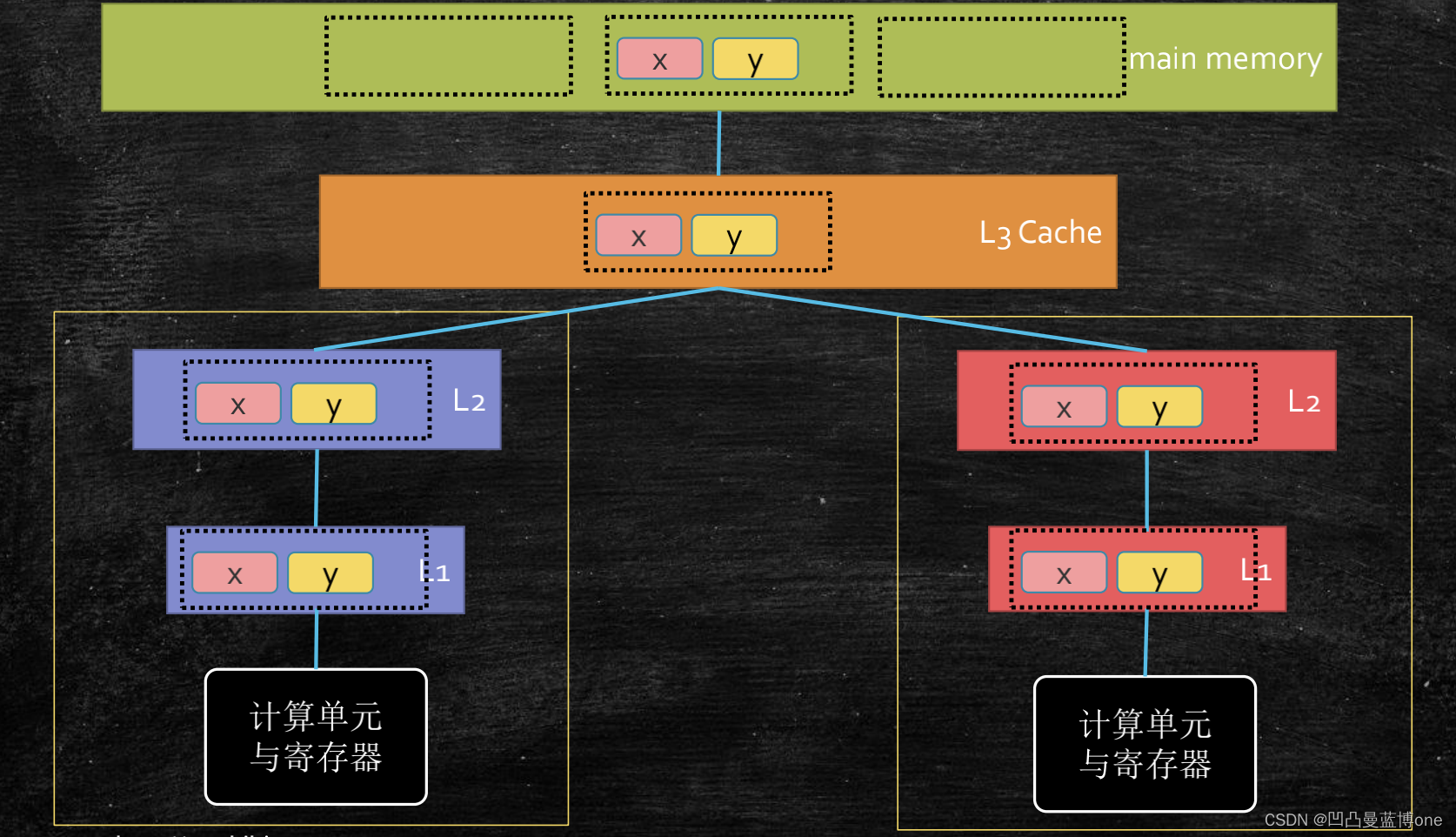
缓存行:
缓存行越大,局部性空间效率越高,但读取时间慢
缓存行越小,局部性空间效率越低,但读取时间快
取一个折中值,目前多用:64字节
举例:
我们知道一个long类型占8个字节,如下有个长度为2的long数组,这个数组也就是16个字节,那么两个线程来分别修改第一个和第二个元素,cpu在计算的的时候是按64字节为一块数据来读取,那么这个被修改的这两个元素肯定存在于同一个缓存行,就会不停的改数据然后通知另一个计算单元重新读数据来保证数据一致性,那么这样看来性能是很差的。
public class T03_CacheLinePadding {
public static volatile long[] arr = new long[2];
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(()->{
for (long i = 0; i < 10000_0000L; i++) {
arr[0] = i;
}
});
Thread t2 = new Thread(()->{
for (long i = 0; i < 10000_0000L; i++) {
arr[1] = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start)/100_0000);
}
}
再看这个例子,是一个长度16的long数组,也就是一共128字节,两条线程分别修改第0个元素和第8个元素,那么被修改的这两个元素就存在不同的缓存行,128字节分成两个64字节的数据块,第0个元素就在第一个数据块而第8个元素在第二个数据块,这样元素本身就是处在不同的缓存行,对其修改也不影响另外的计算单元,这样效率明显提高。
public class T04_CacheLinePadding {
public static volatile long[] arr = new long[16];
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(()->{
for (long i = 0; i < 10000_0000L; i++) {
arr[0] = i;
}
});
Thread t2 = new Thread(()->{
for (long i = 0; i < 10000_0000L; i++) {
arr[8] = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start)/100_0000);
}
}
缓存行对齐:对于有些特别敏感的数字,会存在线程高竞争的访问,为了保证不发生伪共享,可以使用缓存航对齐的编程方式
JDK7中,很多采用long padding提高效率

JDK8,加入了@Contended注解(实验)需要加上:JVM -XX:-RestrictContended
CPU的乱序执行-指令重排序
CPU在进行读等待的同时执行指令,是CPU乱序的根源不是乱,本质上是提高效率。
例如:指令1要去内存中读数据,而指令2只需要计算,这时在指令1去内存那数据的时候,就会优先处理指令2。

通俗点来说,如下:再烧开水的时候,不能坐那干巴巴等着水烧开吧,烧开水期间还可以洗茶壶,洗茶杯是吧。但是泡茶和拿茶叶就不能重排序,因为泡茶依赖茶叶所以必须等拿完茶叶才能泡茶

乱序执行可能会产生的问题:
如下:java在new过程,对应的汇编码
class T {
int m = 8;
}
T t = new T();
汇编码:
0 new #2 <T>
3 dup
4 invokespecial #3 <T.<init>>
7 astore_1
8 return
new的时候只是在内存申请了一块内存空间,invokespecial执行构造方法,astore的时候才会将t的引用指向实例对象
那么DCL单例(Double Check Lock)到底需不需要volatile?
如果一个线程过来执行,初始化new之后,这时发生了指令重排序,那第二个线程进来判断发现t不为null,这时第二个线程就使用了半初始化的对象,肯定就有问题了。

java层面可以使用
volatile来防止指令重排序
CPU层面如何禁止重排序?
答:内存屏障
intel:使用lfence mfence sfence原语,当然也可以使用总线锁来解决
对某部分内存做操作时前后添加的屏障,屏障前后的操作不可以乱序执行

有序性保障
X86 CPU内存屏障:
sfence:在sfence指令前的写操作当必须在sfence指令后的写操作前完成。
lfence:在lfence指令前的读操作当必须在lfence指令后的读操作前完成。
mfence:在mfence指令前的读写操作当必须在mfence指令后的读写操 作前完成。
intel lock汇编指令:
原子指令,如x86上的”lock …” 指令是一个Full
Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU。Software
Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序
JSR内存屏障(虚拟机层面的):
LoadLoad屏障:
对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。 通俗点说就是屏障上边的读和下边的读不可互换
StoreStore屏障:
对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。通俗点说就是屏障上边的写和下边的写指令不可互换
LoadStore屏障:
对于这样的语句Load1;LoadStore; Store2, 在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。通俗点说就是屏障上边的读和下边的写指令不可互换
StoreLoad屏障:
对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。通俗点说就是屏障上边的写指令和下边的读指令不可互换
volatile在JVM层面的实现细节

hanppens-before原则(JVM规定重排序必须遵守的规则)
JLS17.4.5
•程序次序规则:同一个线程内,按照代码出现的顺序,前面的代码先行于后面的代码,准确的说是控制流顺序,因为要考虑到分支和循环结构。
•管程锁定规则:一个unlock操作先行发生于后面(时间上)对同一个锁的lock操作。
•volatile变量规则:对一个volatile变量的写操作先行发生于后面(时间上)对这个变量的读操作。
•线程启动规则:Thread的start( )方法先行发生于这个线程的每一个操作。
•线程终止规则:线程的所有操作都先行于此线程的终止检测。可以通过Thread.join( )方法结束、Thread.isAlive( )的返回值等手段检测线程的终止。
•线程中断规则:对线程interrupt( )方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过Thread.interrupt( )方法检测线程是否中断
•对象终结规则:一个对象的初始化完成先行于发生它的finalize()方法的开始。
•传递性:如果操作A先行于操作B,操作B先行于操作C,那么操作A先行于操作C
as if serial
不管如何重排序,单线程执行结果不会改变














 3384
3384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









