






这个笔记结合了我上课学到的内容和B站Andrew Ng的视频内容
人工智能是一个很大的研究领域,包含很多分支,包括专家系统、机器学习、进化计算、模糊逻辑、计算机视觉、自然语言处理、推荐系统等。

而机器学习是一种实现人工智能的方法,机器学习最基本的做法,是使用算法来解析数据、从中学习,然后对真实世界中的事件做出决策和预测。与传统的为解决特定任务、硬编码的软件程序不同,机器学习是用大量的数据来“训练”,通过各种算法从数据中学习如何完成任务。
深度学习则是一种实现机器学习的技术,或者说是机器学习的一个分支,是一类通过多层非线性变换对高复杂性数据建模算法的合集。在实际中深度学习通常认为是深度神经网络的代名词。

线性分类器(单层线性神经网络) f(x,W)=Wx+b 线性函数 W还可以表示为Theta θ,其为一个向量而非常数
线性回归算法(普通最小二乘法)
以预估房子的价格为例,设定两个特征,房子的房间数和面积(即向量θ的两维)j,根据输入x得出估计价格(假定输出)y 即h(x)=y
为了找到合适的θ需要引进损失函数(成本函数)J(θ)。假定有m个training example的训练集,则损失函数J(θ)为0.5*∑(1,m)(h(θ_x)-y)² 其中h(x)为预估价格,y为实际价格,0.5即二分之一是为了简化计算。最小化成本函数J(θ)就可以找到合适的θ,即找到θ的全局最优解
为了最小化Theta的成本函数J,我们又需要引入一个梯度下降算法
θ(j)=θ(j)-α*J(θ)对θ的偏导 (j为θ的维度,α为学习率 learning rate)
假定我们只有一个training example 则偏导为θ(j)=θ(j)-α*(h(θ_x)-y)*x*j
应用到m个则为θ(j)=θ(j)-α*∑(1,m)(h(θ_x(i))-y(i))*x(i)*j 这里的i指training example的序号,此时本算法也可以叫做批量梯度下降算法
梯度下降可以理解为:你站在图中的“+”点处,你现在需要走出一小步,以期能在最短的时间内下降到图中的最低点,走出这一小步后再以此类推,直到走到最低点。换言之函数定义了最陡下降的方向
批量梯度下降算法有一个很大的缺陷在于每一次迭代,更新θ值都需要遍历整个数据集,当训练集的规模特别庞大,比如千万级甚至亿级时,每迈出一步的开销都过于巨大。

随机梯度下降
for i=1 to m:
θ(j)=θ(j)-α*(h(θ_x(i))-y(i))*x(i)*j
即先对第一个训练样本的数据修改θ值以期拟合,再针对第二个训练样本做相同的事,随机梯度下降的路线可能是弯曲迂回的,最终可能到达全局最小值,实际上随机梯度下降永远不会完全收敛,参数会震荡但永远不会收敛,因为你总是在比较新的训练样本
判断随机梯度下降停止的标准:损失函数J(θ)不再下降
第三种求θ最优解的方式是 求出J(θ)的导数并使其=0,以此得到J(θ)的最小值,并得到相应的θ全局最优解,此方法涉及到矩阵求导。
参数学习算法和非参数学习算法
之前所说的都是参数学习算法,因为有一组固定的参数θ,无论训练集规模多大,都会拟合参数θ,完成训练后你可以从计算机内存中删除训练集,用训练得出的θ做出预测
非参数学习算法,参数/数据的数量会保持增长,参数会随着训练集的规模变大而线性增长。计算机所需的内存空间随训练集的大小而线性增长,用非参数学习算法做出预测需要在计算机中保留训练集
局部加权回归就是典型的非参数学习算法
fit θ to minimize
∑(1,m)w(i)(y(i)-θx(i))²
这里的w(i)是一个加权函数
w(i)=exp{-[(x(i)-x]²/τ},这里的w(i)介于0到1之间,x是需要进行预测的点,exp,高等数学里以自然常数e为底的指数函数
所以当输入值x(i)离预测点非常远时w(i)趋近于0,而当x(i)离预测点很近时,w(i)趋近于1
假设误差为IID,每一个误差项独立同分布
pip install 包名
pip uninstall 包名
线性回归:
# %matplotlib inline
import torch
from IPython import display
from matplotlib import pyplot as plt
import numpy as np
import random
from torch import nn
from torch.autograd import backward
# 生成数据集
num_inputs=2
num_examples=1000
true_w=[2,-3.4]
true_b=4.2
features=torch.tensor(np.random.normal(0,1,(num_examples,num_inputs)),dtype=torch.float)
labels=true_w[0]*features[:,0]+true_w[1]*features[:,1]+true_b
labels+=torch.tensor(np.random.normal(0,0.01,size=labels.size()),dtype=torch.float)
# 读取数据
import torch.utils.data as Data
batch_size=10
dataset=Data.TensorDataset(features,labels)
data_iter=Data.DataLoader(dataset,batch_size,shuffle=True)
for X,y in data_iter:
print(X,y)
break
class LinearNet(nn.Module):
def __init__(self,n_feature):
super(LinearNet,self).__init__()
self.linear=nn.Linear(n_feature,1)
# 定义前向传播
def forward(self,x):
y=self.linear(x)
return y
net=LinearNet(num_inputs)
print(net)
net=nn.Sequential(
nn.Linear(num_inputs,1)
)
print(net)
print(net[0])
for param in net.parameters():
print(param)
# 初始化模型参数
from torch.nn import init
init.normal_(net[0].weight,mean=0,std=0.01)
init.constant_(net[0].bias,val=0)
net[0].bias.data.fill_(0)
# 定义损失函数
loss=nn.MSELoss()
# 定义优化算法
import torch.optim as optim
optimizer=optim.SGD(net.parameters(),lr=0.03)
print(optimizer)
# optimizer=optim.SGD([
# {'params':net.subnet1.parameters()},
# {'params':net.subnet2.parameters(),'lr':0.01}
# ],lr=0.03)
#
# for param_group in optimizer.param_groups:
# param_group['lr']*=0.1
num_epochs=3
for epoch in range(1,num_epochs+1):
for X,y in data_iter:
output=net(X)
l=loss(output,y.view(-1,1))
optimizer.zero_grad()
l.backward()
optimizer.step()
print('epoch %d,loss: %f' %(epoch,l.item()))
dense=net[0]
print(true_w,dense.weight)
print(true_b,dense.bias)
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
np.random.normal()的意思是一个正态分布,normal这里是正态的意思。我在看孪生网络的时候看到这样的一个例子:numpy.random.normal(loc=0,scale=1e-2,size=shape) ,意义如下:
- 参数loc(float):正态分布的均值,对应着这个分布的中心。loc=0说明这一个以Y轴为对称轴的正态分布,
- 参数scale(float):正态分布的标准差,对应分布的宽度,scale越大,正态分布的曲线越矮胖,scale越小,曲线越高瘦。
- 参数size(int 或者整数元组):输出的值赋在shape里,默认为None。
torch.from_numpy 生成一个张量
简单说一下,就是torch.from_numpy()方法把数组转换成张量,且二者共享内存,对张量进行修改比如重新赋值,那么原始数组也会相应发生改变。
Example:
>>> a = numpy.array([1, 2, 3])
>>> t = torch.from_numpy(a)
>>> t
tensor([ 1, 2, 3])
>>> t[0] = -1
>>> a
array([-1, 2, 3])
均方误差(平均平方误差) WSE
plt.scatter:PYthon——plt.scatter各参数详解_yuanCruise-CSDN博客_plt.scatter
- s参数传list其实是设置每个点的大小


andom.shuffle()函数可以随机打乱数组顺序
-
import random -
random.shuffle(x1)
yield features.index_select(0,j), labels.index_select(0,j)
yield 首先作用理解为return,它也可以返回一个或多个值,要想调用返回值就必须在循环中
index_select() 中第一个参数 0 表示以行为标准选择,例如j = tensor([1,2]),结果为选取features 第1,第2行数据
torch.mul(a, b)是矩阵a和b对应位相乘,a和b的维度必须相等,比如a的维度是(1, 2),b的维度是(1, 2),返回的仍是(1, 2)的矩阵
torch.mm(a, b)是矩阵a和b矩阵相乘,比如a的维度是(1, 2),b的维度是(2, 3),返回的就是(1, 3)的矩阵
backward()函数:pytorch中backward()函数详解_Camlin_Z的博客-CSDN博客_backward()
创建一个张量x,并设置其 requires_grad参数为True,程序将会追踪所有对于该张量的操作,当完成计算后通过调用 .backward(),自动计算所有的梯度, 这个张量的所有梯度将会自动积累到 .grad 属性。
创建一个关于x的函数y,由于x的requires_grad参数为True,所以y对应的用于求导的参数grad_fn为<MulBackward0>。这是因为在自动梯度计算中还有另外一个重要的类Function,Tensor 和 Function互相连接并生成一个非循环图,它表示和存储了完整的计算历史。 每个张量都有一个.grad_fn属性,这个属性引用了一个创建了Tensor的Function(除非这个张量是用户手动创建的,即,这个张量的 grad_fn 是 None,例如1中创建的x的 grad_fn 是 None)
我们进行反向传播并输出x的梯度值,而这里出现了一个参数torch.ones_like(y)即为grad_tensors参数,这里便引入了我们的问题
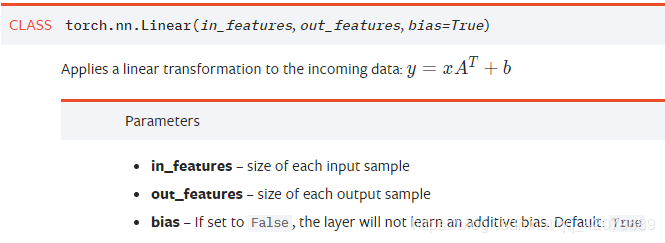
nn.Linear()
-
nn.Linear():用于设置网络中的全连接层,需要注意的是全连接层的输入与输出都是二维张量
-
一般形状为[batch_size, size],不同于卷积层要求输入输出是四维张量。其用法与形参说明如下:
-
in_features指的是输入的二维张量的大小,即输入的[batch_size, size]中的size。 -
out_features指的是输出的二维张量的大小,即输出的二维张量的形状为[batch_size,output_size],当然,它也代表了该全连接层的神经元个数。 -
从输入输出的张量的shape角度来理解,相当于一个输入为
[batch_size, in_features]的张量变换成了[batch_size, out_features]的输出张量。















 299
299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









