







一、Mysql客户端\服务器架构
mysql分为客户端和服务器,服务器是直接与存储的数据进行交互。每个客户端都有自己唯一的命名,用户操作客户端就是客户端与服务器数据传输的过程。
客户端和mysql服务器(数据库实例)本质上就是计算机上的两个进程,进程即PID,每次开启的PID都是随机的,这个是由操作系统分配的,不过进程的名称都是一开始设计软件的时候定义好的,例如客户端默认名称为mysql, 服务器默认名称为mysqld
二、Mysql的安装
1、window下安装
直接去看这个文章即可(5.7版本),不过网上其实有很多教程,随意选择一个安装即可
mysql(5.7)window下安装
2、linux下安装
这边建议直接用docker部署,方便又快捷。
docker部署mysql5.7
3、bin文件夹
这个文件夹下就是启动文件,所以安装的时候一定要记住自己软件安装位置,需要后期配置环境变量的。
4、启动服务器程序
接下来就按照要求把服务器启动即可,为了让mysql服务器能够在启动计算机的时候一起启动,我们可以把他添加进服务中。
5、启动客户端程序
客户端程序启动有一个完整的语句
mysql -u用户名 -hIP地址 -p密码 --port=端口号(PID)
可以发现,这一串里面有英文缩写和完整的单词,缩写只需要一个-,而完整的单词需要- -,而且完整单词后面需要添加=符号。
注意!-p后面的密码不能带空格——即密码需要紧接着-p写入,不过正常都不会写在上面,而是输入完其他内容后按回车去进行密码的输入
例如本地输入(可以省略ip和端口):
mysql -uroot -p
6、关闭连接
- exit
- quit
- \q
三、客户端链接服务器的方式
因为客户端和服务器本质就是两个进程,所以可以mysql链接服务器当作进程之间的通信
1、TCP\IP
通常情况下,数据库客户端和服务器进程不会再同一个计算机中,我们就需要通过网络去让他们之间实现通信。在网络中,一台电脑都有自己独一无二的ip地址,可以通过这个ip地址,与分配一个端口即可实现通信。
端口分配范围为0~65535
为什么端口分配的范围是0~65535?
因为服务器和客户端之间的通讯是基于传输层的TCP/UDP协议的,网络的请求头中,源端口与目的端口分别占用两个字节
一个字节=8个二进制位,所以端口的分配范围就是0~2^16-1
mysql服务器默认端口为3306,这个端口也是可以自己设定的。
当使用TCP\IP连接的时候,客户端链接语句里面就一定要带上ip地址和端口号
2、命名管道和内存共享
window下可以通过命名管道和内存共享进行一个通信。具体怎么操作可以去查阅其他资料
3、Unix域套接字文件
如果客户端和服务器都在同一台unix系统中,就可以使用Unix域套接字链接
四、客户端与服务器通信过程
不管使用了哪种通信方式,客户端都是将编写好的sql文本传入服务器,服务器也向客户端返回一个文本(处理结果)
那具体做了什么操作呢?
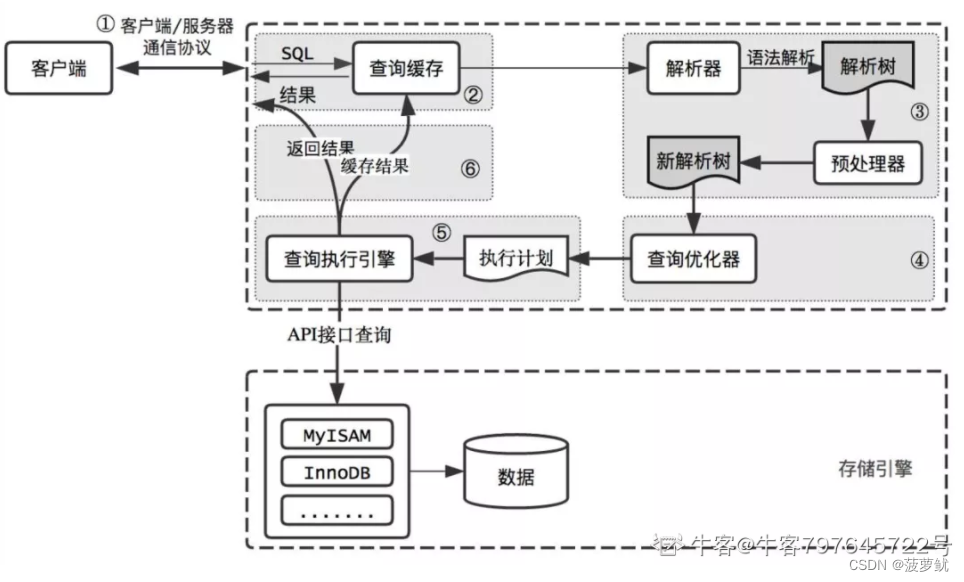
1、连接管理
我们可以通过前面说到的连接方式使客户端和服务器建立连接。每当有一个客户端进程发起连接到服务器进程时,服务器端就会创建一个线程去处理该客户端的连接,当客户端退出时会与服务器断开连接。此时服务器不会立即销毁与客户端交互的线程,而是将他缓存起来,再与其他连接进来的客户端进行一个交互。因为减少了频繁的创建销毁操作,从而减少了开销。
如果服务器和客户端运行不在同一台计算机中,那么我们可以通过SSL(安全套接字)的网络连接进行通信,从而保证数据传输的安全
2、查询缓存(了解)
因为查询缓存占用的命中率不高(sql语句任意变动都无法命中),虽然查询缓存有时候可以提升系统性能,但是缓存区域的维护也会造成开销,所以5.7.20以后的版本不推荐使用查询缓存,8.0中直接删除了这个环节。
那么查询缓存什么时候会失效呢~
如对该表使用了 INSERT 、 UPDATE 、 DELETE 、 TRUNCATE TABLE 、 ALTER TABLE 、 DROP TABLE 或DROP DATABASE 语句,那使用该表的所有高速缓存查询都将变为无效并从高速缓存中删除!
3、语法解析
如果查询语句没有命中上面的查询缓存,那么就会到这一步。
因为客户端传来的sql语句只是一段文本,所以服务器需要获取这段文本,并且判断语法是否正确,并且解析这段语法,将需要用到的表,条件提取出来后面使用
4、查询优化
语法解析以后,服务器就获得了需要查的表和条件,这时候mysql识别到可能我们编写的sql语句效率不是很高,这时候他就会一顿操作。优化后就会生成一个执行计划了这个执行计划表明了应该使用哪些索引进行查询,表之间的连接顺序是啥样的。我们可以使用EXPLAIN 语句来查看某个语句的执行计划
5、存储引擎
一段sql语句,经历了前面这一系列解析优化处理后,还没有真正的去操作我们的数据表。mysql将数据表的存取操作都封装到了一个名字叫存储引擎的模块中。存储引擎负责从表中读出数据,将数据写入物理存储器上。
mysql提供了很多中存储引擎,通过不同的存储引擎去管理不同的存储结构和存取算法。
存储引擎就是获取上层传入的指令,然后对数据进行提取或者写入的操作
五、常用的存储引擎
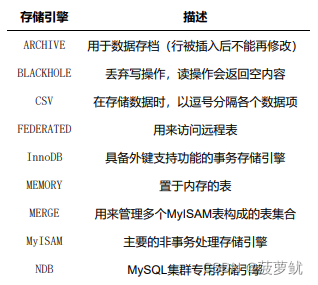
这里面其实常用的就是InnoDB和MyISAM。其中InnoDB是Mysql的默认存储引擎
六、关于存储引擎的一些操作
通过下面这个命令可以查看当前服务器支持的引擎:
SHOW ENGINES;
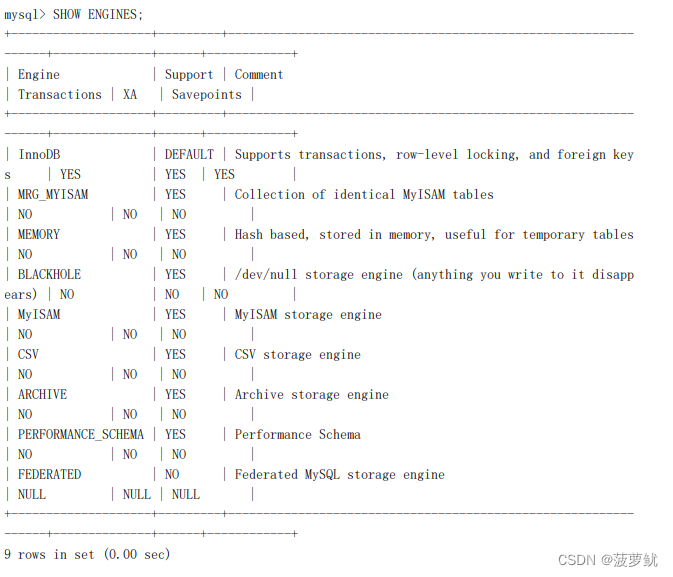
- Support 列表示该存储引擎是否可用,DEFAULT 值代表是当前服务器程序的默认存储引擎。
- Comment 列是对存储引擎的一个描述,英文的,将就着看吧。
- Transactions 列代表该存储引擎是否支持事务处理。
- XA 列代表着该存储引擎是否支持分布式事务。
- Savepoints 代表着该列是否支持部分事务回滚。
这些具体都是啥,好像都一知半解,后面的话慢慢搞懂吧
1、设置表的存储引擎
存储引擎是对表中的数据进行提取和写入工作的,我们可以为不同的表选择不同的存储引擎,这样表就有不同的物理存储结构和存取方式了
mysql是默认InnoDB的,但是我们可以在建表的时候为他设置想要的存储引擎
CREATE TABLE 表名(
建表语句;
) ENGINE = 存储引擎名称;
2、修改表的存储引擎
那么如果一个表已经建好了,如何去修改他的存储引擎呢
ALTER TABLE 表名 ENGINE = 存储引擎名称;
修改好了如何确认呢?
通过下面第一行就可以查看到该表的搜索引擎了哦
mysql> SHOW CREATE TABLE engine_demo_table\G
*************************** 1. row ***************************
Table: engine_demo_table
Create Table: CREATE TABLE `engine_demo_table` (
`i` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.01 sec)
















 4601
4601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









