









一、fraud
跑了一个lr模型,从正则,一直看到了极大似然和最大后验估计emmm。一路跑偏,已经0954了。先把实验结果抄一抄
本来想把模型都跑完,没想到看R补充了大量的基本知识(L1\L2正则、先验概率
今天先来看fraud
看的时候,要知道原来模型的大体内容,效果,改进空间。
下午场开始啦~1351。
再花一个小时总结一下APT论文,然后和老师汇报。
二、APT
完美用了一个小时看完、总结完了paper,并push了一下老师。休息了一下,打算再看看上午学的内容。
最近开始用markdown了,感觉还蛮爽的!
呜呜呜,刚刚看csdn私信,发现被夸了,好开心啊!!!
三、基础模型与LR相关内容总结(上午内容)
(一)正则化方法
1、L1,L2
正则化,约束了解空间。
L1正则化用参数绝对值约束,看起来像是个有棱角的方形。不易求导,更容易为0,更加稀疏,很多参数最后为0。
L2正则化用参数欧氏距离约束,是圆形约束。


(二)极大似然估计
这是一个谜一样的存在,当时再看《统计学习方法》的时候就因为这个一度放弃,今天终于可以弄明白一点了!!
1、似然函数
所谓似然函数,其实就是我们熟悉的概率函数P(X|θ)的另一种解读方法。
(1)如果模型参数θ已知,x为变量,那么求不同x出现的可能性就是我们平时说的概率函数
(2)如果x已知,而θ为变量,那么对于不同的θ,导致出现x的概率,则为似然函数。也就是,对于不同的θ,出现已知x的可能性。
2、极大似然估计
MLE:most likelihood estimate
一般x是已知的,由我们抽样获取的,我们希望通过抽样实验估计出模型参数θ的值。
于是,我们求解,在θ为什么值的时候,最可能出现我们抽样出的结果,认为该θ为模型的最优值。这里面包含了一层意思——我们认为我们抽样的结果可以反应数据本身的分布,即我们根据我们的样本,估计了一个使模型生成该样本数据的最佳参数。我们无比相信我们的抽样结果x。
3、最大后验估计
MAP:Maximum A Posteriori
在考虑极大似然估计的时候,我们只考虑了什么样的θ可以让x最大可能出现,但是并没有考虑theta本身出现的概率,所以并不能反映P(θ|x),也就是已知x,某个theta真正出现的概率,即最大后验估计。这也是贝叶斯学派的思想,强调加入先验概率P(θ)
4、MLE和MAP
个人感觉,
MLE是无比相信某一次实验的结果,仅仅看实验结果,求θ,使得实验结果最大可能出现;
而MAP,则是在MLE的基础上做了一些correction,类似于补了一刀,虽然这个θ可以使本次实验结果最大可能出现,但是有可能这个θ本身的出现并不符合常理,要用P(θ)纠正。
所以,二者之间,其实可以通过实验次数来不断靠近——实验次数多了,那么一次实验的结果也就有说服力了,靠近真实结果了,MLE也就不会被P(θ)影响太多了,因为常识其实已经在不断的实验中被注入了。
从数学上讲,例如,投硬币实验,实验次数多了,那么θ次方也就多了,最大值就不会轻易被P(θ)的分布带跑偏了。
当然,如果有顽固贝叶斯学派,认为θ日常只可能出现在0.5,即P(θ=0.5)=1,那么无论怎样,MAP只能为theta=0.5,在取其他值的时候,P(θ|x)=0,也就是知识注入太强势了。
(三)不同的avg
A. Micro考虑所有样本,直接算
B. Macro先针对不同类别算,再在类别之间直接平均
C. weighted针对不同类别算后,加权求平均
(四)LR原理
兜兜转转,回到最初的起点。
其实感觉逻辑回归就是个模型嘛~这个模型其实就是线性+sigmoid拟合。
1、预测函数
其中z其实就是θT·x的线性组合,h(x)求出来在0~1,我们为其赋予意义:y为1的可能性。
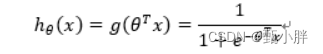

2、损失函数Loss
由于定义了h(x)的含义:y为1的可能性,那么就可以据此分类讨论,Yt为0和1的情况啦。
如果Yt=0,我希望预测结果也为0,则结果越靠近0,损失越小,越靠近1,损失越大,于是L(h(x),y)=-log(1-h(x));
如果Yt=1,则希望预测结果也越靠近1,结果越靠近1,损失越小,则L(h(x),y)=-log(h(x)),这里采用-log作为代价函数

用log的原因,大概是在不影响本身表达loss的想法的情况之下,更好计算和优化,
3、代价函数C
损失函数,是定义在单个样本的,而代价函数是定义在整个训练集的
这里用yi和(1-yi)分布*相应的loss,是一个很神奇的方法。当yi为0时,只需要看yi=0带来的loss,即右半部分;yi=1同理。而且乘数为1,不影响值的大小。

其实到这里基本就可以优化了。
4、目标函数
目标函数是在代价函数的基础上,加上正则项(结构风险)的函数,最终需要优化的函数。
呜呜呜,越来越爱“学习”了,真的是理论和时间的完美融合。
5、优化@梯度下降
梯度的方向是给定函数,在某点数值上升最快的方向,反过来,就是数值下降最快的地方。
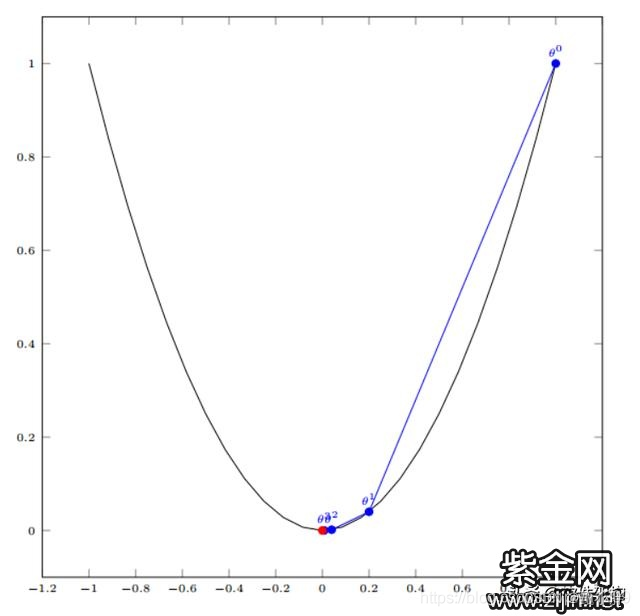
迭代优化,这也解释了为什么要设置迭代次数

6、反向传播BP
是一种快速求偏导的算法
对于每一个样本,先正求y,然后计算目标函数(误差),对误差分别对最后一层的参数求导,再根据链式法则,对之前每一层参数求导,分别得到对应梯度。
反向传播,巧妙借助反向的优势,借助前面的求导直接,实现对每一层参数的求导。
求导之后,再根据梯度下降,优化参数。
总的来说,我想通过改变θ,让目标函数变小,那么我要对θ(神经网络中的w和b)进行梯度下降操作。于是,就要对每个参数求偏导。在求偏导时,先对后层参数求,前层参数可以借助后层参数的求导结果,快速实现梯度的计算,这也是反向传播的美妙之处。
—1644总结完啦~~
一会有个讲座~
btw,终于有时间看看datacon相关内容啦~开心!!!
emmm吃饭,看讲座,北邮的老师好潇洒~王小娟老师,优秀知识女性hh
1820狂吃狂吃零食,看一会KG书籍,一会去做核算
四、KG
具体笔记记录在typora里啦
这里记录一些小点
1、启发式规则
就是基于经验构建的算法啦
一个基于直观或经验构造的算法,在可接受的花费(指计算时间和空间)下给出待解决组合优化问题每一个实例的一个可行解,该可行解与最优解的偏离程度一般不能被预计。
看着看着就不想吃零食了!!!
先去做核算,回来继续看!!!
—1912继续看啦
2、本体匹配
哇塞,这本书把原来的概念细节化了,没想到本体匹配还能玩出这么多花花来~
看到了这个!!!清华大学知识工程实验室!
3、TransE、TransR、TransH很有意思啊,可以仔细看看
妈耶看书看的脑壳痛了,终于读完第二章啦~~~
去敲一会colab1吧!!!
五、cs224w colab1
1、normalized closeness centrality
标准化的是乘了N-1,点多一点,图就大一点,那么距离远一点也正常。如果点多,距离还小,那就是真正的王者。

2、又看到tensor真的好激动啊

明天再继续敲!!!我要去看ctf啦!!!
六、今天居然要写脚本了
41题一道题就好顶呀~
大体思路是,因为都过滤了,所以采用构造字符串。
为啥不直接构造一个16进制呢?非得用或生成?
搭一下昨天的服务器
改了这里,试一试!

不行,xsl,
我的目录写错了
Mysql密码更改
Navicat
用来连接mysql















 2107
2107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









