







目录
1.1 networkx实现空手道俱乐部Graph的可视化。
1.2 利用network计算Graph的平均度并取整(Question 1)
1.3 平均聚类系数计算,并保留2位小数,可以使用networkx自带的聚类系数函数(Question 2)
1.4 计算id=0节点经过一次迭代的PageRank值(Question 3)
1.5 计算(raw) closeness centrality (Question 4)
2.1 Tensor矩阵的初始化(全1,全0,随机值)及元素类型转换
2.2 将networkx中Graph的边转化为dict类型,每条边在dict中用一个而2个元素的tuple表示。然后,再将dict转换为torch.LongTensor类型(Question 5)。
2.3 实现一个负样本边生成函数,功能是生成原图中没有的一些边(需要注意无向图正负边为同一条边,自环不算边等情况)(Question 6)
3.3 torch.nn.Embedding类的实例emb的训练过程(Question 7)
1 Graph Basic
主要涉及networkx包的使用:
1.1 networkx实现空手道俱乐部Graph的可视化。
# Visualize the graph
nx.draw(G, with_labels = True)
pylab.show() # tips 2:draw画图不显示问题可尝试导入pylab包1.2 利用network计算Graph的平均度并取整(Question 1)
# Question 1
def average_degree(num_edges, num_nodes):
# TODO: Implement this function that takes number of edges
# and number of nodes, and returns the average node degree of
# the graph. Round the result to nearest integer (for example
# 3.3 will be rounded to 3 and 3.7 will be rounded to 4)
avg_degree = 0
############# Your code here ############
avg_degree = round(num_edges * 2 / num_nodes)
#########################################
return avg_degree
num_edges = G.number_of_edges()
num_nodes = G.number_of_nodes()
avg_degree = average_degree(num_edges, num_nodes)
print("Average degree of karate club network is {}".format(avg_degree))1.3 平均聚类系数计算,并保留2位小数,可以使用networkx自带的聚类系数函数(Question 2)
# Question 2
def average_clustering_coefficient(G):
# TODO: Implement this function that takes a nx.Graph
# and returns the average clustering coefficient. Round
# the result to 2 decimal places (for example 3.333 will
# be rounded to 3.33 and 3.7571 will be rounded to 3.76)
avg_cluster_coef = 0
############# Your code here ############
## Note:
## 1: Please use the appropriate NetworkX clustering function
avg_cluster_coef = round(nx.average_clustering(G), 2)
#########################################
return avg_cluster_coef
avg_cluster_coef = average_clustering_coefficient(G)
print("Average clustering coefficient of karate club network is {}".format(avg_cluster_coef))1.4 计算id=0节点经过一次迭代的PageRank值(Question 3)
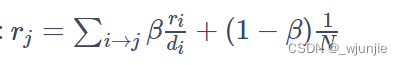
提示:节点邻居的遍历可以用networkx中自带函数G.neighbors(node_id)来实现,其返回值是一个dict迭代器(dict_keyiterator)。
# Question 3
def one_iter_pagerank(G, beta, r0, node_id):
# TODO: Implement this function that takes a nx.Graph, beta, r0 and node id.
# The return value r1 is one interation PageRank value for the input node.
# Please round r1 to 2 decimal places.
r1 = 0
############# Your code here ############
## Note:
## 1: You should not use nx.pagerank
'''
tips 3: nx.neighbors(self, n_id)
'''
tmp = G.neighbors(node_id) # tmp: Debug
for nb in G.neighbors(node_id):
r1 += 1.0 * r0 / G.degree(nb)
r1 = r1 * beta + (1.0 - beta) / G.number_of_nodes()
r1 = round(r1, 2)
#########################################
return r1
beta = 0.8
r0 = 1 / G.number_of_nodes()
node = 0
r1 = one_iter_pagerank(G, beta, r0, node)
print("The PageRank value for node 0 after one iteration is {}".format(r1))1.5 计算(raw) closeness centrality (Question 4)
PS:可以使用networkx自带的closeness计算函数,但需注意自带函数计算出的值是归一化后的值,即乘以了(节点数-1)。这里的结果需要除以(节点数-1)以消除归一化。

# Question 4
def closeness_centrality(G, node=5):
# TODO: Implement the function that calculates closeness centrality
# for a node in karate club network. G is the input karate club
# network and node is the node id in the graph. Please round the
# closeness centrality result to 2 decimal places.
closeness = 0
## Note:
## 1: You can use networkx closeness centrality function.
## 2: Notice that networkx closeness centrality returns the normalized
## closeness directly, which is different from the raw (unnormalized)
## one that we learned in the lecture.
#########################################
closeness = nx.closeness_centrality(G, node) / (G.number_of_nodes() - 1)
closeness = round(closeness, 2)
return closeness
node = 5
closeness = closeness_centrality(G, node=node)
print("The node 5 has closeness centrality {}".format(closeness))2 Graph To Tensor
Tensor,一种数据类型
2.1 Tensor矩阵的初始化(全1,全0,随机值)及元素类型转换
import torch
# Generate 3 x 4 tensor with all ones
ones = torch.ones(3, 4)
print(ones)
# Generate 3 x 4 tensor with all zeros
zeros = torch.zeros(3, 4)
print(zeros)
# Generate 3 x 4 tensor with random values on the interval [0, 1)
random_tensor = torch.rand(3, 4)
print(random_tensor)
# Get the shape of the tensor
print(ones.shape)
'''
ones.shape作用等同于ones.size(),其返回一个torch.Size类,shape[0]和shape[1]可获得行数、列数。
'''
# Create a 3 x 4 tensor with all 32-bit floating point zeros
zeros = torch.zeros(3, 4, dtype=torch.float32)
print(zeros.dtype)
# Change the tensor dtype to 64-bit integer
zeros = zeros.type(torch.long)
print(zeros.dtype) #输出zeros张量内部元素的类型。 int642.2 将networkx中Graph的边转化为dict类型,每条边在dict中用一个而2个元素的tuple表示。然后,再将dict转换为torch.LongTensor类型(Question 5)。
①networkx中G的边转换为dict集合,可以用G.edges()函数,其返回值类型为<class 'networkx.classes.reportviews.EdgeView'>,该类型(集合)中元素(即每条边)类型为tuple,详见下面实现。
②dict转tensor可以直接用tensor的初始化函数。
PS:题目要求最后转换得到的tensor的shape为2*节点数,所以需要用到tensor.t()函数来实现矩阵的转置。
def graph_to_edge_list(G):
# TODO: Implement the function that returns the edge list of
# an nx.Graph. The returned edge_list should be a list of tuples
# where each tuple is a tuple representing an edge connected
# by two nodes.
edge_list = []
############# Your code here ############
for e in G.edges():
edge_list.append(e)
#########################################
return edge_list
def edge_list_to_tensor(edge_list):
# TODO: Implement the function that transforms the edge_list to
# tensor. The input edge_list is a list of tuples and the resulting
# tensor should have the shape [2 x len(edge_list)].
edge_index = torch.tensor([])
############# Your code here ############
edge_index = torch.LongTensor(edge_list).t()
#########################################
return edge_index
pos_edge_list = graph_to_edge_list(G)
pos_edge_index = edge_list_to_tensor(pos_edge_list)
print("The pos_edge_index tensor has shape {}".format(pos_edge_index.shape))
print("The pos_edge_index tensor has sum value {}".format(torch.sum(pos_edge_index)))2.3 实现一个负样本边生成函数,功能是生成原图中没有的一些边(需要注意无向图正负边为同一条边,自环不算边等情况)(Question 6)
函数:random.randint(0, N)可以生成[0,N]的随机整数。
# Question 6
import random
def myjudge1(G, p, q):
if (p != q and G.has_node(p) and G.has_node(q) and not G.has_edge(p, q) and not G.has_edge(q, p)):
return True
return False
def sample_negative_edges(G, num_neg_samples):
# TODO: Implement the function that returns a list of negative edges.
# The number of sampled negative edges is num_neg_samples. You do not
# need to consider the corner case when the number of possible negative edges
# is less than num_neg_samples. It should be ok as long as your implementation
# works on the karate club network. In this implementation, self loops should
# not be considered as either a positive or negative edge. Also, notice that
# the karate club network is an undirected graph, if (0, 1) is a positive
# edge, do you think (1, 0) can be a negative one?
neg_edge_list = []
############# Your code here ############
cas = 0
while(cas < num_neg_samples):
p = random.randint(0, G.number_of_nodes() - 1)
q = random.randint(0, G.number_of_nodes() - 1)
if myjudge1(G, p, q):
neg_edge_list.append((p, q))
cas += 1
#########################################
return neg_edge_list
# Sample 78 negative edges
neg_edge_list = sample_negative_edges(G, len(pos_edge_list))
# Transform the negative edge list to tensor
neg_edge_index = edge_list_to_tensor(neg_edge_list)
print("The neg_edge_index tensor has shape {}".format(neg_edge_index.shape))
# Which of following edges can be negative ones?
edge_1 = (7, 1)
edge_2 = (1, 33)
edge_3 = (33, 22)
edge_4 = (0, 4)
edge_5 = (4, 2)
############# Your code here ############
## Note:
## 1: For each of the 5 edges, print whether it can be negative edge
for a, b in [(7, 1), (1, 33), edge_3, (0, 4), (4, 2)]:
print(myjudge1(G, a, b))其他更好的代码实现版本:利用networkx自带函数nx.non_edges(G)得到G中所有不存在的边,然后利用random.sample(range(0,n), numb)函数从前边得到的边中随机选择numb个。
代码:
def sample_negative_edges(G, num_neg_samples):
#题目要求:不用考虑num_neg_samples比所有不存在边的数量还高的边界条件
#不考虑自环
#注意,本来需要考虑逆边的问题,但是由于nx.non_edges函数不会出现两次重复节点对,所以不用考虑这个问题。
neg_edge_list = []
#得到图中所有不存在的边(这个函数只会返回一侧,不会出现逆边)
non_edges_one_side=list(enumerate(nx.non_edges(G)))
neg_edge_list_indices=random.sample(range(0,len(non_edges_one_side)),num_neg_samples)
#取样num_neg_samples长度的索引
for i in neg_edge_list_indices:
neg_edge_list.append(non_edges_one_side[i][1])
return neg_edge_list
# Sample 78 negative edges
neg_edge_list = sample_negative_edges(G, len(pos_edge_list))
# Transform the negative edge list to tensor
neg_edge_index = edge_list_to_tensor(neg_edge_list)
3 Node Embedding Learning
3.1 torch.nn.Embedding类的使用
PS:Embedding相当于生成了一个N*M的嵌入表,G中的每个节点在表中都有一个对应的M维嵌入。
①torch.nn.Embedding初始化方法:
# Initialize an embedding layer
# Suppose we want to have embedding for 4 items (e.g., nodes)
# Each item is represented with 8 dimensional vector
emb_sample = nn.Embedding(num_embeddings=4, embedding_dim=8) #初始化
print('Sample embedding layer: {}'.format(emb_sample))
'''
>>> print('Sample embedding layer: {}'.format(emb_sample))
Sample embedding layer: Embedding(4, 8)
'''②torch.nn.Embedding的使用:
索引id需要是torch.LongTensor类型的矩阵,可以一维可以二维,具体维度根据最后需要的矩阵shape来定。(id矩阵是nn.Embdding矩阵和目标矩阵之间的过渡量)
# Select an embedding in emb_sample
id = torch.LongTensor([1])
print(emb_sample(id))
# Select multiple embeddings
ids = torch.LongTensor([1, 3])
print(emb_sample(ids))
# Get the shape of the embedding weight matrix
shape = emb_sample.weight.data.shape
print(shape)
# Overwrite the weight to tensor with all ones
emb_sample.weight.data = torch.ones(shape)
# Let's check if the emb is indeed initilized
ids = torch.LongTensor([0, 3])
print(emb_sample(ids))③torch.nn.Embedding值的修改:
# Overwrite the weight to tensor with all ones
emb_sample.weight.data = torch.ones(shape)实现一个nn.Embedding生成函数,要求其各个元素值服从[0, 1]的均匀分布,可以使用torch.rand(a, b)来生成一个服从[0, 1]均匀分布的a*b的矩阵。
PS:网上有人说实际上nn.Embedding初始化的时候的值就是[0,1]的,这里再修改一次的目的是为了协同torch.manual_seed()函数来保证结果的可复现性。
# Please do not change / reset the random seed
torch.manual_seed(1)
def create_node_emb(num_node=34, embedding_dim=16):
# TODO: Implement this function that will create the node embedding matrix.
# A torch.nn.Embedding layer will be returned. You do not need to change
# the values of num_node and embedding_dim. The weight matrix of returned
# layer should be initialized under uniform distribution.
emb = None
############# Your code here ############
emb = torch.nn.Embedding(num_node, embedding_dim)
emb.weight.data = torch.rand(num_node, embedding_dim)
#########################################
return emb
emb = create_node_emb()
ids = torch.LongTensor([0, 3])
# Print the embedding layer
print("Embedding: {}".format(emb))
# An example that gets the embeddings for node 0 and 3
print(emb(ids))3.2 nn.Embedding实例emb的可视化
def visualize_emb(emb):
X = emb.weight.data.numpy()
pca = PCA(n_components=2)
components = pca.fit_transform(X)
plt.figure(figsize=(6, 6))
club1_x = []
club1_y = []
club2_x = []
club2_y = []
for node in G.nodes(data=True):
if node[1]['club'] == 'Mr. Hi':
club1_x.append(components[node[0]][0])
club1_y.append(components[node[0]][1])
else:
club2_x.append(components[node[0]][0])
club2_y.append(components[node[0]][1])
plt.scatter(club1_x, club1_y, color="red", label="Mr. Hi")
plt.scatter(club2_x, club2_y, color="blue", label="Officer")
plt.legend()
plt.show()
# Visualize the initial random embeddding
visualize_emb(emb)3.3 torch.nn.Embedding类的实例emb的训练过程(Question 7)
PS:我们滴目标是,使每个节点在emb表中对应的embedding能最大程度的保持节点的结构特点。不同于监督分类任务中可以直接对比节点的预测值和标签值,这里没有ground-truth,所以采取的思路是:
如果模型很好的学习到了节点的结构特征,那么一个节点和它的邻居的embedding应该是相似的(这里用向量点积来衡量相似度,相当于余弦相似度),所以模型的输出值就是一些向量点积,label标签就是对应edge是否在图中存在(即向量点积对应的两个节点是否直接相连)。
代码如下:
tips 1:Tensor类型的数据可以直接使用+、-、*、/、==、>、sigmoid、mul...等运算符,详见accuracy()函数以及train()函数的Version 2。
tips 2:item()函数可以将一个1*1的Tensor转换为普通数据类型的量
tips 3:每轮epoch,optimizer的梯度要清零
tips4:随着epoch轮次的迭代,loss会越来越小,loss如果不是递减的,则模型有错误,例如梯度没清零。
# Question 7
from torch.optim import SGD
import torch.nn as nn
def accuracy(pred, label):
# TODO: Implement the accuracy function. This function takes the
# pred tensor (the resulting tensor after sigmoid) and the label
# tensor (torch.LongTensor). Predicted value greater than 0.5 will
# be classified as label 1. Else it will be classified as label 0.
# The returned accuracy should be rounded to 4 decimal places.
# For example, accuracy 0.82956 will be rounded to 0.8296.
accu = 0.0
############# Your code here ############
accu = ((pred > 0.5) == label).sum().item() * 1.0 / pred.shape[0]
accu = round(accu, 4)
#########################################
return accu
def train(emb, loss_fn, sigmoid, train_label, train_edge):
# TODO: Train the embedding layer here. You can also change epochs and
# learning rate. In general, you need to implement:
# (1) Get the embeddings of the nodes in train_edge
# (2) Dot product the embeddings between each node pair
# (3) Feed the dot product result into sigmoid
# (4) Feed the sigmoid output into the loss_fn
# (5) Print both loss and accuracy of each epoch
# (6) Update the embeddings using the loss and optimizer
# (as a sanity check, the loss should decrease during training)
epochs = 500
learning_rate = 0.1
optimizer = SGD(emb.parameters(), lr=learning_rate, momentum=0.9)
for i in range(epochs):
############# Your code here Version 2 ############
optimizer.zero_grad()
tmp = emb(train_edge)
pred = sigmoid(tmp[0].mul(tmp[1]).sum(1))
loss = loss_fn(pred, train_label)
print(f"Epochs: {i}, Accuracy: {accuracy(pred, train_label)}, Loss: {loss}")
loss.backward()
optimizer.step()
#########################################
############# Your code here Version 1############
'''
optimizer.zero_grad()
pred = torch.Tensor(train_edge.shape[1])
for j in range(train_edge.shape[1]):
node_ids = torch.LongTensor([train_edge[0][j], train_edge[1][j]])
tmp = emb(node_ids)
pred[j] = sigmoid(tmp[0].dot(tmp[1]))
loss = loss_fn(pred, train_label)
print(f"Epochs: {i}, Accuracy: {accuracy(pred, train_label)}, Loss: {loss}")
loss.backward()
optimizer.step()
'''
#########################################
loss_fn = nn.BCELoss()
sigmoid = nn.Sigmoid()
print(pos_edge_index.shape)
print(neg_edge_index.shape)
# Generate the positive and negative labels
pos_label = torch.ones(pos_edge_index.shape[1], )
neg_label = torch.zeros(neg_edge_index.shape[1], )
# Concat positive and negative labels into one tensor
train_label = torch.cat([pos_label, neg_label], dim=0)
# Concat positive and negative edges into one tensor
# Since the network is very small, we do not split the edges into val/test sets
train_edge = torch.cat([pos_edge_index, neg_edge_index], dim=1)
print(train_edge.shape)
train(emb, loss_fn, sigmoid, train_label, train_edge)
# Visualize the final learned embedding
visualize_emb(emb)部分结果:
<class 'networkx.classes.graph.Graph'>
Average degree of karate club network is 5
Average clustering coefficient of karate club network is 0.57
The PageRank value for node 0 after one iteration is 0.13
The node 5 has closeness centrality 0.01
End...















 6981
6981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









