







Pandas库使用过程中做些记录
pandas读取
读取csv文件
df = pd.read_csv(filepath, encoding="ISO-8859-1")
# 当时的文件使用‘utf-8’仍然报错,在stackoverflow上找到"ISO-8859-1"解决问题,编码问题有空需要了解一下
按行读取,每一行转成list存放(不含表头
for index, row in df.iterrows():
get_list.append(row.tolist())
按列读取,index为表头,row为该列
for index, row in df.iteritems():
header_list.append(index)
df类似于字典,直接表头作为key读取该列
name = 'name'
data = df[name].tolist()
pandas写入
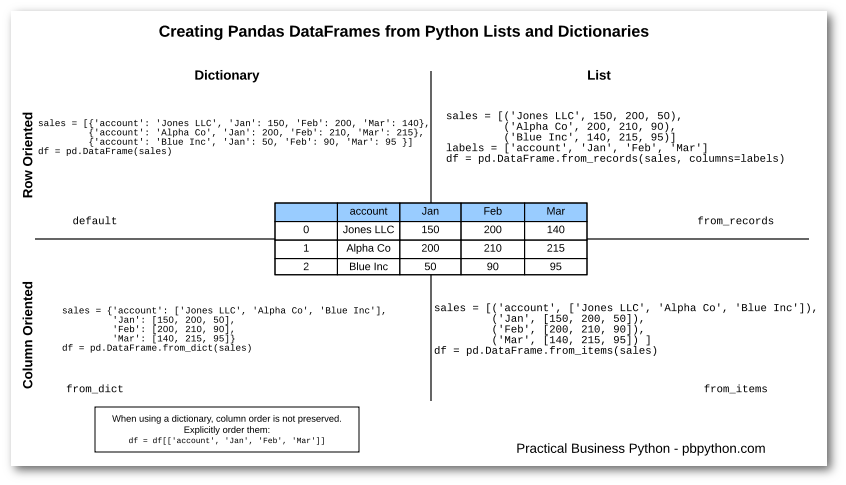
创建DataFrame
先创建字典,将字典转成DataFrame
原文链接
[外链图片转存失败(img-ZaLoWzWr-1562209845371)(https://pbpython.com/images/pandas-dataframe-shadow.png)]
由于字典是无序的,如果要保证dataframe的呈现按照一定的顺序:
header_list = ['account','Jan','Feb','Mar'] # 将表头按顺序存放在list
df = df[header_list] # dataframe按照result的顺序
DataFrame写入excel
writer = pd.ExcelWriter(store_path)
df.to_excel(writer, index=False) #index = True 则会在最左侧多一列index, 0-N
writer.save()
pandas索引
https://blog.csdn.net/Xw_Classmate/article/details/51333646
<转> Pandas——ix vs loc vs iloc区别
pandas数据处理
处理缺失值
dropna()
drop()
fillna()
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
<转>
https://blog.csdn.net/dss_dssssd/article/details/82814673
Series计数
value_counts()
函数可以对Series里面的每个值进行计数并且排序
- 如果想用升序排列,可以加参数ascending=True,默认降序
- 如果想得出的计数占比,可以加参数normalize=True















 5851
5851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}