









1. 概述
IK分词器是ElasticSearch(es)的一个最最最有名插件,能够把一段中文或者别的语句划分成一个个的关键字,进而在搜索的时候对数据库中或者索引库数据进一个匹配操作
举个小例子,可以将计算机科学与技术学院更细致的拆分为计算机、计算 、算机 、科学、与、技术、学院 、技术学院 … 等等
2. 安装配置
注意版本的对应,必须保证ik分词器和es是同一个版本
下载链接:ik分词器GitHub地址
在Elasticsearch7.6.2\plugins目录下新建ik目录,将压缩包解压
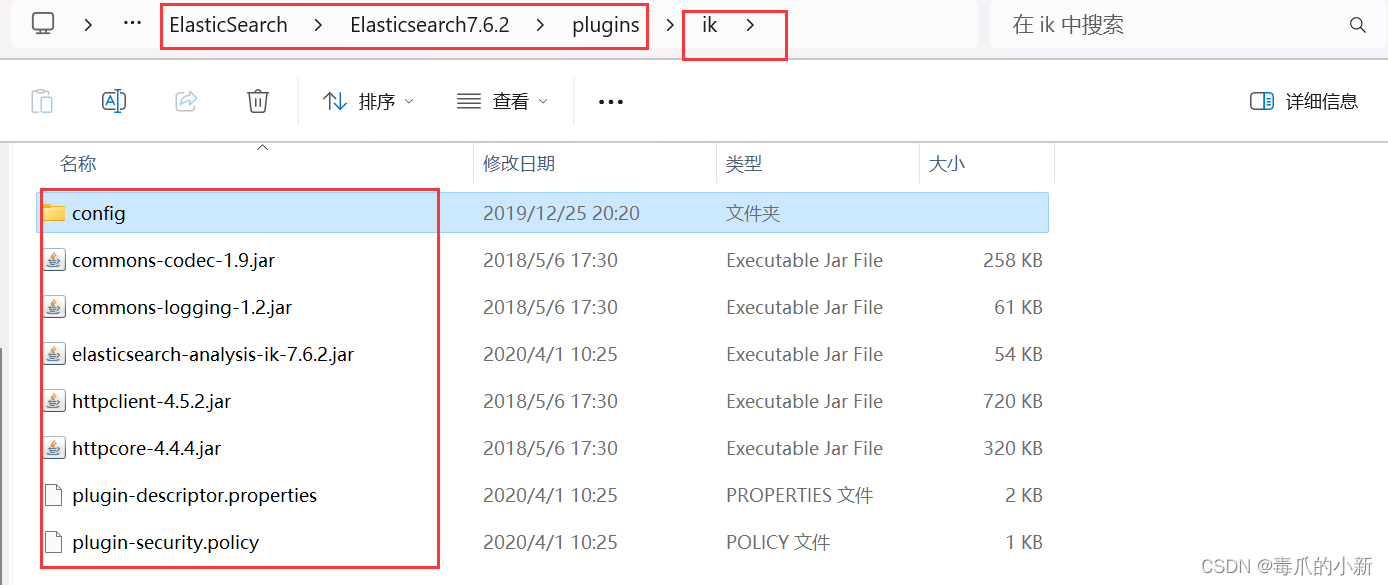
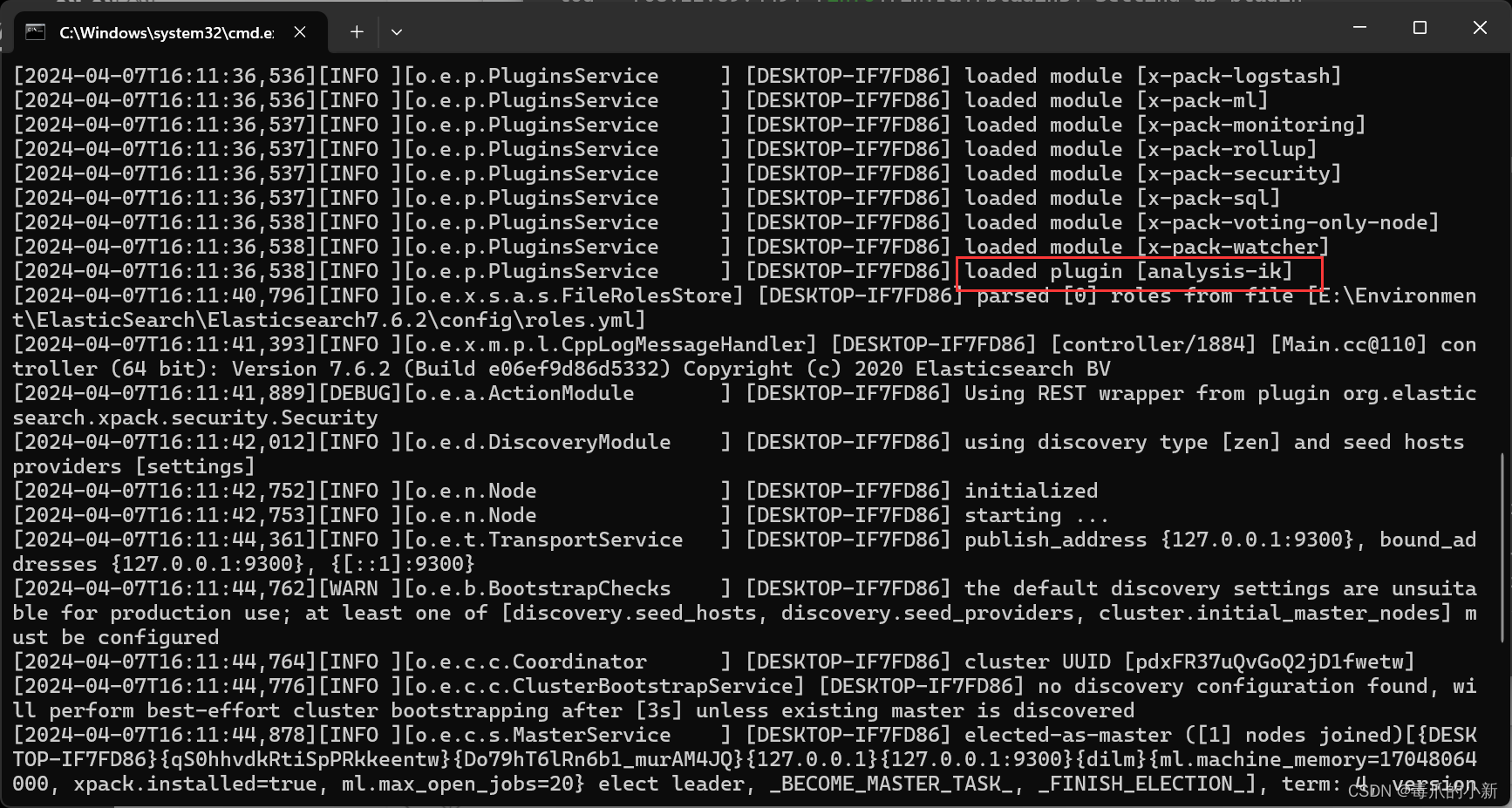
重启elasticsearch和kibana,可以看到ik分词器已经被加载
3. 自定义拆分文本
有的时候,ik分词器拆分出来的词语并不是我们想要的,或者说拆分出来的词语不够我使用,此时便可以自定义拆分文本
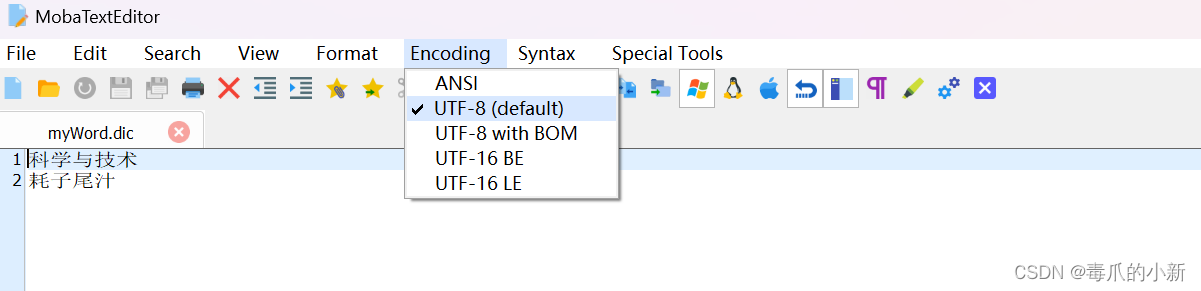
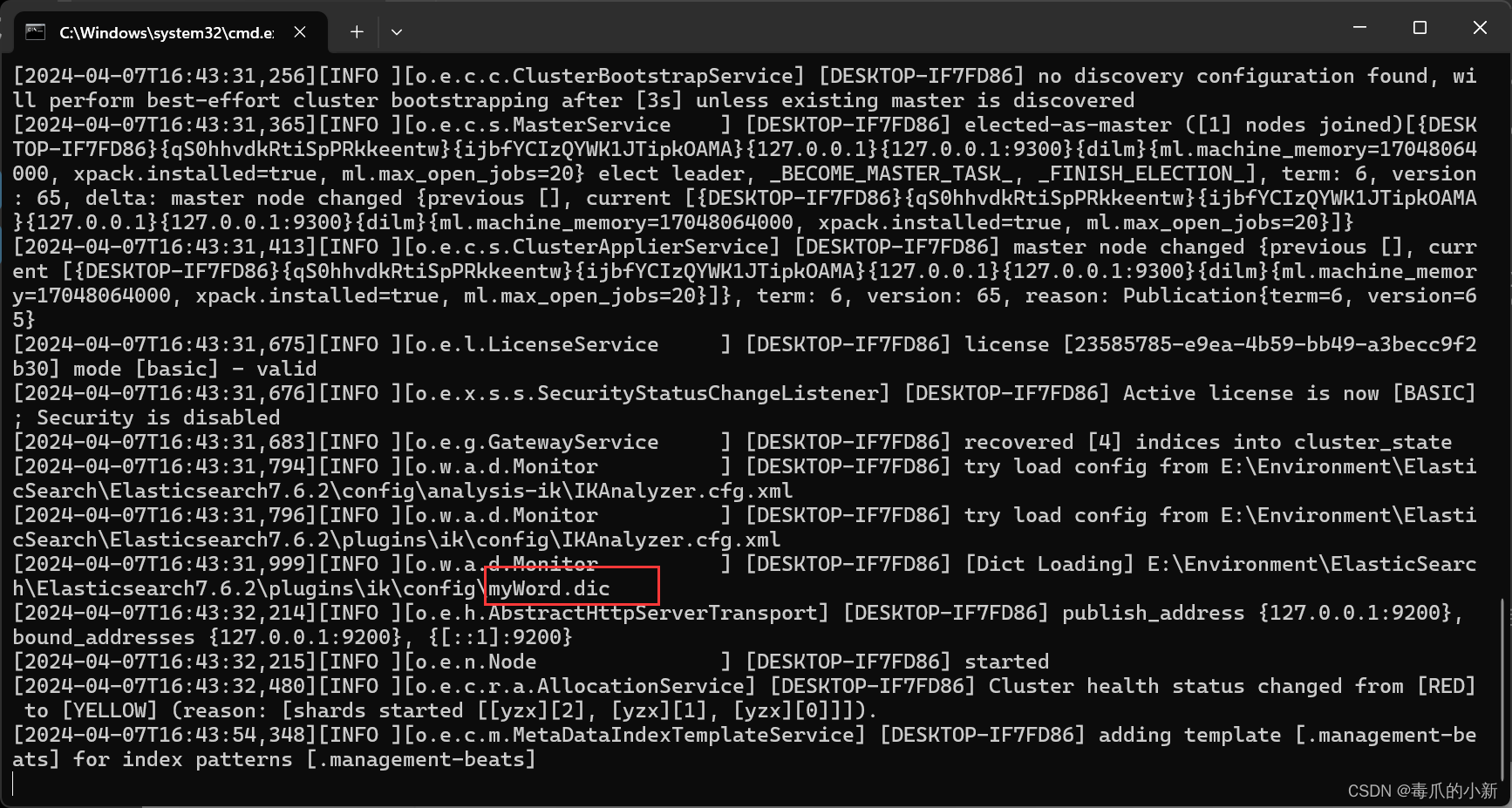
第一步,首先在Elasticsearch7.6.2\plugins\ik\config目录下新建一个文本文件,命名为.dic后缀的文件,例如我命名为myWord.dic
第二步,打开自定义的dic文件,在其中编写你需要的词语(千万注意,这里要将文件的编码选择为UTF-8,否则无法正确识别)
第三步,打开Elasticsearch7.6.2\plugins\ik\config目录下的IKAnalyzer.cfg.xml文件,将自定义的dic文件写入
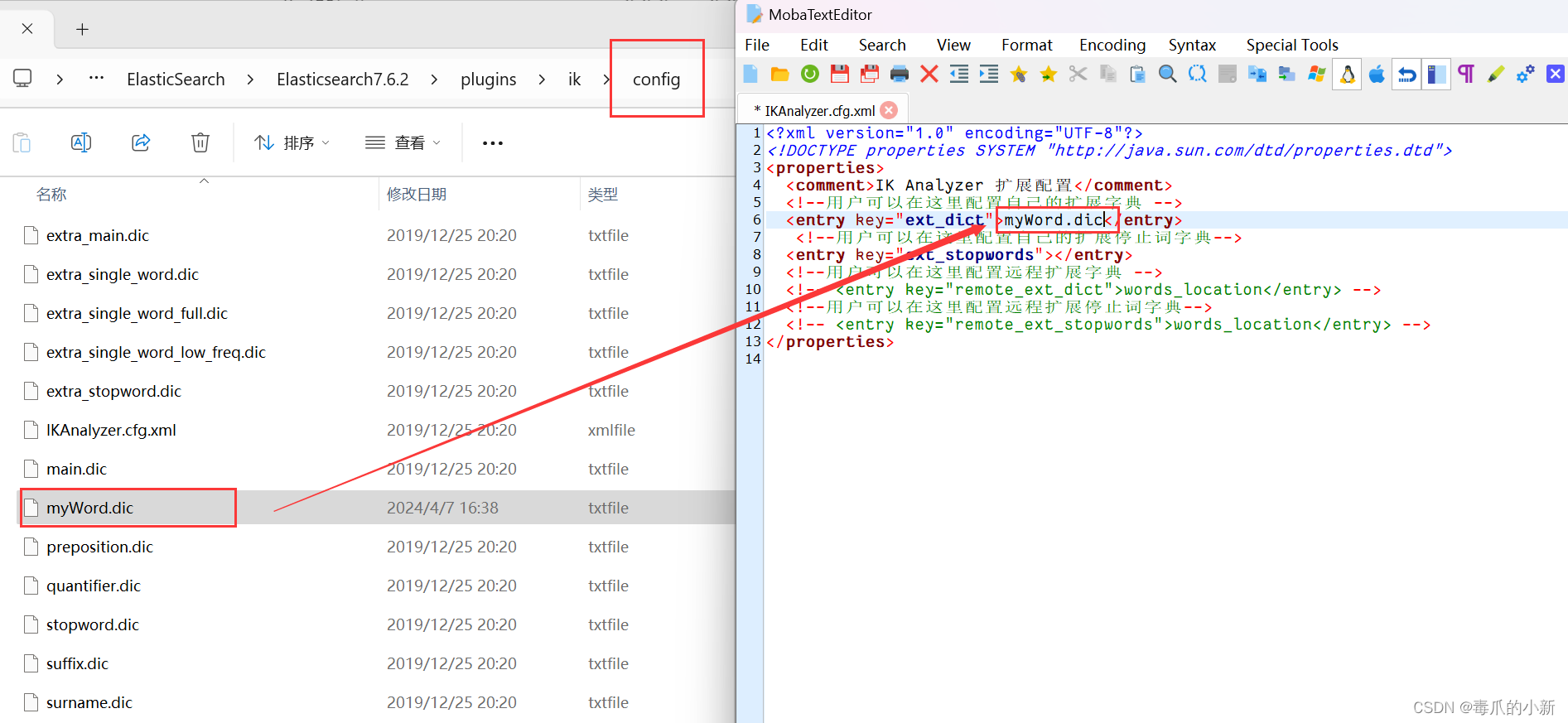
第四步,重启es和kibana,可以看到es已经重新加载了我们自定义的dic文件
4. 调用
4.1 拆分规则
ik分词器拥有两种拆分规则,分别为ik_smart和ik_max_word
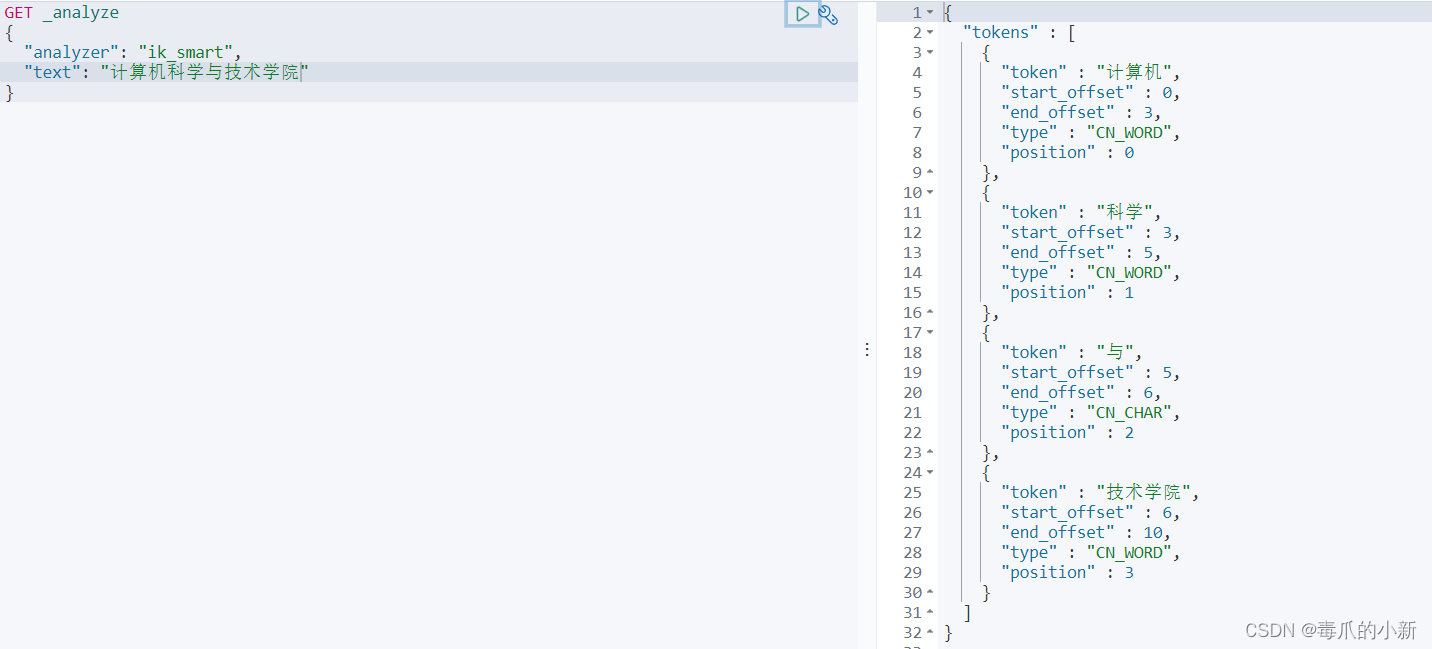
ik_smart:粗糙的拆分,列举常见的拆分
GET _analyze
{
"analyzer": "ik_smart",
"text": "计算机科学与技术学院"
}
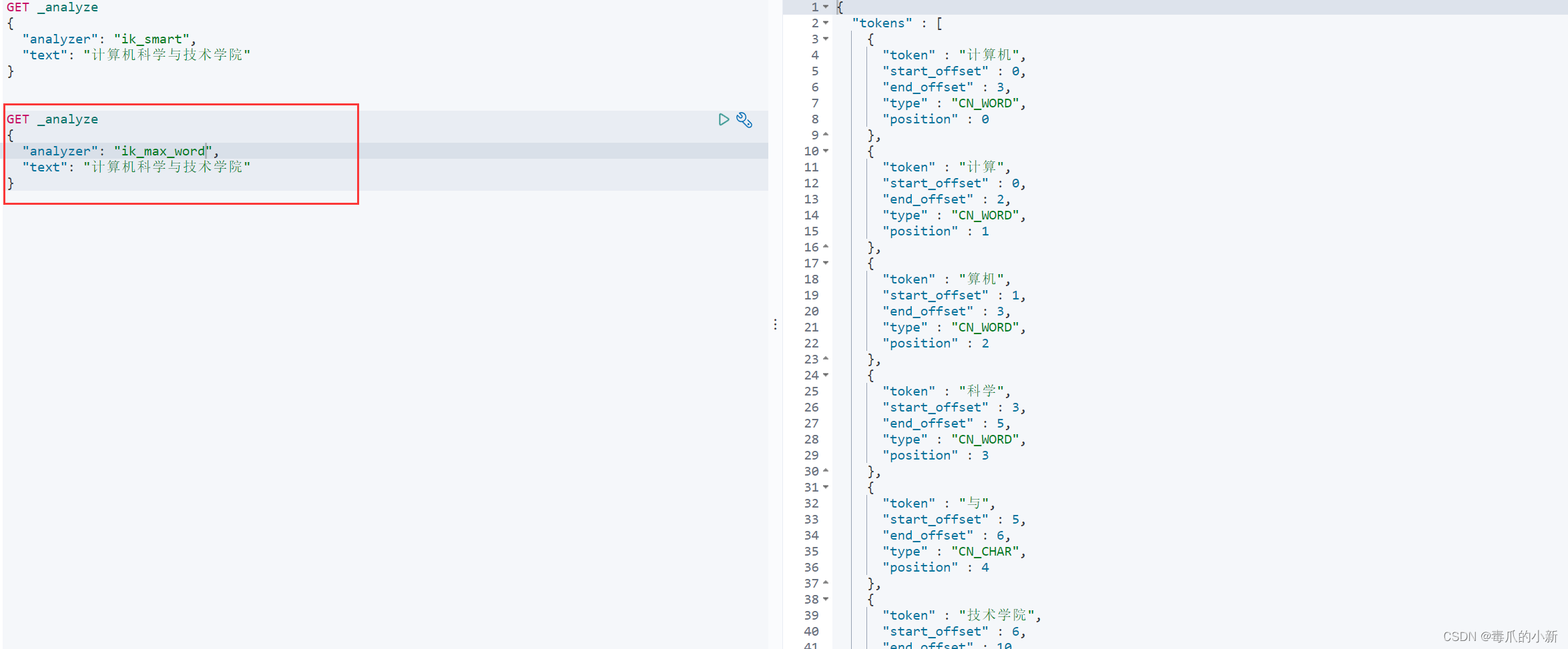
ik_max_word:最细致划分,列举所有的可能
GET _analyze
{
"analyzer": "ik_max_word",
"text": "计算机科学与技术学院"
}
4.2 Rest 调用
利用rest风格,可以在创建索引时指定分词器
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age":{
"type": "long"
},
"desc":{
"type": "text"
"analyzer":"ik_max_word",
}
}
}
}
4.3 SpringBoot 调用
也可以在SpringBoot中指定分词器,前提是记得导入相关es依赖
//创建使用ik分词器的索引
void createIndexWithIK() throws IOException {
//1、创建索引请求(这里千万要注意,创建的索引都要求小写)
CreateIndexRequest request = new CreateIndexRequest("test_index");
XContentBuilder mappingBuilder = XContentFactory.jsonBuilder();
mappingBuilder.startObject();
{
mappingBuilder.startObject("properties");
{
// 定义age属性
mappingBuilder.startObject("age");
{
mappingBuilder.field("type", "integer");
}
mappingBuilder.endObject();
// 定义name属性
mappingBuilder.startObject("name");
{
// 使用keyword类型,不进行分词
mappingBuilder.field("type", "keyword");
}
mappingBuilder.endObject();
// 定义desc属性
mappingBuilder.startObject("desc");
{
mappingBuilder.field("type", "text");
mappingBuilder.field("analyzer", "ik_max_word"); // 设置使用 IK 分词器
}
mappingBuilder.endObject();
}
mappingBuilder.endObject();
}
mappingBuilder.endObject();
// 2、将映射添加到索引请求中
request.mapping(mappingBuilder);
//3、客户端执行请求(使用默认的请求参数),获得请求后的响应
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
}
查看索引是否创建成功
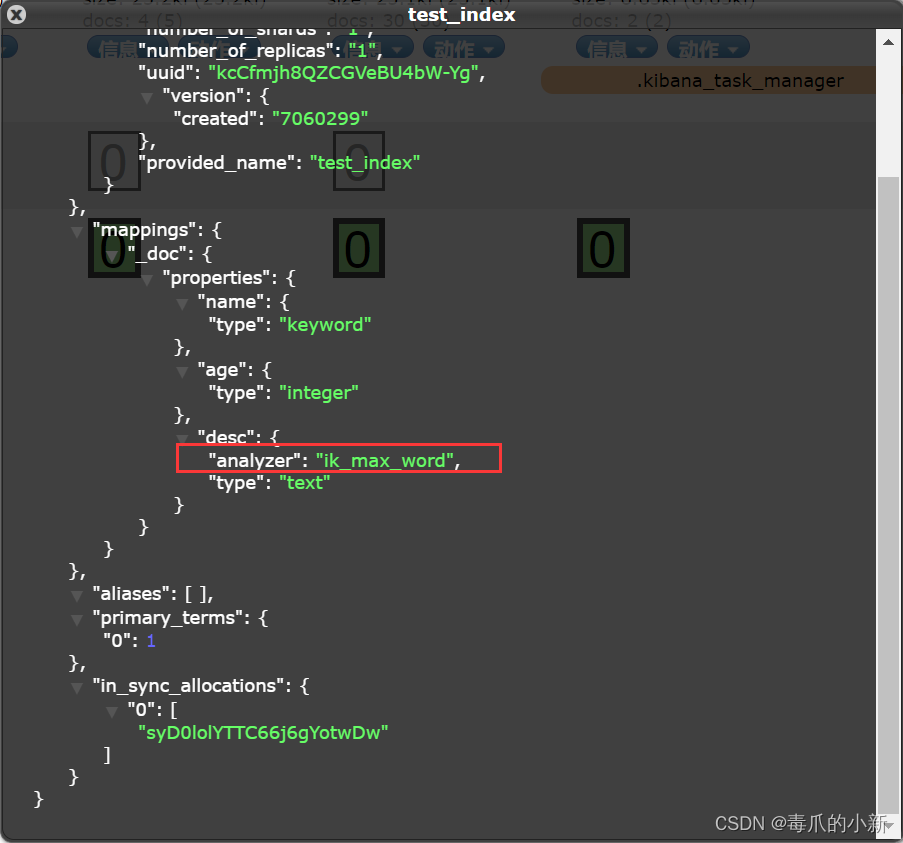















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









