






文章目录
一、安装elasticsearch+kibana
首先确保docker运行正常
- 创建挂在目录
mkdir -p docker-data/elasticsearch/config mkdir -p docker-data/elasticsearch/data mkdir -p docker-data/elasticsearch/logs mkdir -p docker-data/elasticsearch/plugins mkdir -p docker-data/kibana/config chmod 777 docker-data/elasticsearch/data chmod 777 docker-data/elasticsearch/logs chmod 777 docker-data/elasticsearch/plugins - 创建配置文件
elasticsearch.ymlvi /docker-data/elasticsearch/config/elasticsearch.yml vi /docker-data/kibana/config/kibana.yml
kibana.ymlcluster.name: "docker-cluster" network.host: 0.0.0.0 http.cors.allow-origin: "*" http.cors.enabled: true http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type xpack.security.enabled: trueserver.host: "0.0.0.0" server.shutdownTimeout: "5s" # 设置ip地址 elasticsearch.hosts: [ "http://ip:9200" ] monitoring.ui.container.elasticsearch.enabled: true i18n.locale: "zh-CN" elasticsearch.username: "kibana" #设置密码 elasticsearch.password: "123456" - 创建docker-compose.yml 目录随便都可以
docker-compose.ymlversion: '3.8' services: # 定义 Elasticsearch 和 Kibana 服务 elasticsearch: container_name: elasticsearch image: elasticsearch:8.7.1 ports: - 9200:9200 # 将宿主机的 9200 端口映射到容器的 9200 端口,用于访问 Elasticsearch HTTP API - 9300:9300 # 将宿主机的 9300 端口映射到容器的 9300 端口,用于 Elasticsearch 节点之间的通信 restart: 'no' environment: - discovery.type=single-node # 设置 Elasticsearch 的发现类型为单节点 - ES_JAVA_OPTS=-Xms1024m -Xmx1024m # 设置 Elasticsearch 的 Java 虚拟机选项,分配 256MB 堆内存 volumes: - /docker-data/elasticsearch/logs:/usr/share/elasticsearch/logs # 挂载日志目录 - /docker-data/elasticsearch/data:/usr/share/elasticsearch/data # 挂载数据目录 - /docker-data/elasticsearch/plugins:/usr/share/elasticsearch/plugins # 挂载插件目录 - /docker-data/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml # 挂载配置文件 #Kibana服务 kibana: container_name: kibana restart: 'no' image: kibana:8.7.1 ports: - 5601:5601 # 将宿主机的 5601 端口映射到容器的 5601 端口,用于访问 Kibana Web 界面 depends_on: - elasticsearch # 定义依赖关系,表示 Kibana 服务依赖于 Elasticsearch 服务 volumes: - /docker-data/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml # 挂载配置 - 进入docker-compose.yml 目录中 执行docker-compose up -d
cd /docker-data/elasticsearch_kibana docker-compose up -d - 运行完成 查看容器是否正常运行
docker ps
二、操作语句
1. 插入语句
# 插入数据到user表中,name = "张三" company="lingli" id=3
# post可以重复写入,如果id存在就更新
POST user/_doc/3
{
"name":"张三",
"company":"lingli",
"age":18
}
#只能插入一次 如果id存在报错
POST user/_create/3
{
"name":"张三",
"company":"lingli",
"age":18
}
# PUT 和 POST 类似,不存在就插入,存在就更新
PUT user/_doc/3
{
"name":"张三",
"company":"lingli",
"age":18
}
2. 更新语句
# 单独更新,更新操作如果值没有改变的话不会修改version 和 seq_no
# 这条操作并不会对数据进行修改
POST user/_update/3
{
"doc": {
"name":"张三",
"company":"lingli",
"age":18
}
}
3. 删除语句
# 删除语句可以删除单条数据 也可以删除整个表
# 删除id = 3 的数据
DELETE user/3
# 删除整个user表
DELETE user
4. 批量操作 添加,更新,删除
# 批量操作
# 这里的user表明可以在url中指明,也可以在语句中指明
POST user/_bulk
# 新增
{"create": {"_index": "user", "_type": "docs", "_id": 1}}
{"name": "lin", "company":"jd"}
{"create": {"_index": "user", "_type": "docs", "_id": 2}}
{"name": "dearlin", "company":"ali"}
# 存在更新 不存在 新增
{"index":{ "_index": "user", "_id": "1" }}
{"name": "test", "company":"ali"}
# 更新
{"update":{ "_index": "user", "_id": "1" }}
{"name": "test", "company":"ali"}
# 删除
{"delete": {"_index": "user", "_type": "docs", "_id": "1" }}
5. 查询语句
5.1 Match Query(匹配查询)
#Match Query(匹配查询)
GET user/_search
{
"query": {
"match": {
"name": "张三"
}
}
}
5.2 Term Query(精确查询)
精确查询比较坑,这里你查询张三是查询不到的,因为做了分词处理 只能查询张 or 三
GET /user/_search
{
"query": {
"term": {
"name": "三"
}
}
}
5.3 Range 范围查询
年龄区间为 10- 20
GET user/_search
{
"query": {
"range": {
"age": {
"gte": 10,
"lte": 20
}
}
}
}
5.4 Bool Query(布尔查询)
布尔查询相当于mysql的and 如 name = ‘张三’ and age = 18 and company = ‘jd’ 查询较为复杂的内容时可以用到
must 类似于 name = ‘张三’ and age = 18 and company = ‘jd’
not must 类似于 name != ‘张三’ and age != 18 and company != ‘jd’
should 类似于 name = ‘张三’ or age = 18 or company = ‘jd’
GET user/_search
{
"query": {
"bool": {
"must": [
{"match": {"name": "张三"}},
{"match": {"age": 18}},
{"match": {"company": "jd"}}
],
"must_not": [{}],
"should": [{}]
}
}
}
5.5 Fuzzy Query(模糊查询)
GET user/_search
{
"query": {
"fuzzy": {
"name": {
"value": "张四",
"fuzziness": 2 #编辑距离,通过算法计算 编辑距离也就是通过几次编辑可以到正确的词
}
}
}
}
6. 查询分页
查询分页是通过 from size 字段控制
GET user/_search
{
"query": {
"match_all": {}
},
"from": 0, #对应mysql offset
"size": 20 # 对应mysql limit
}
三、IK 分词器
下载安装ik分词器
- 下载地址
- 下载好后解压到 docker-data/elasticsearch/plugins 修改文件夹名称为ik

- 重启es
docker restart elasticsearch
- 进入docker容器,查看是否安装成功
docker exec -it elasticsearch /bin/bash
cd bin
elasticsearch-plugin list

ik分词器安装成功
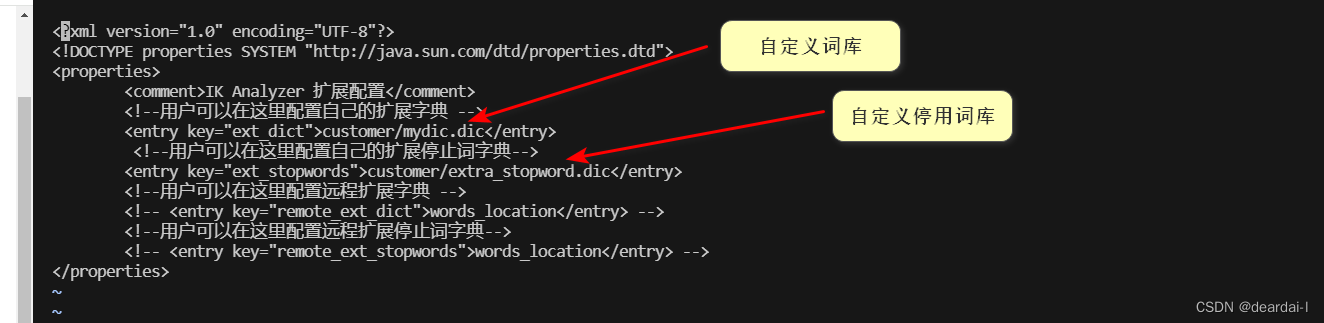
修改ik分词器的自定义词库
- 进入config目录 创建自定义词库文件 写入自定义词语 写入停用词库
cd /docker-data/elasticsearch/plugins/ik/config/
mkdir customer
cd customer
vi mydic.dic # 写入自定义词语并保存
vi my_stopword.dic # 写入停用词库
- 更新配置到配置文件
cd /docker-data/elasticsearch/plugins/ik
vi IKAnalyzer.cfg.xml # 修改配置文件地址
使用ik分词器
- 演示
# ik_smart 细粒度分词模式
GET _analyze
{
"analyzer": "ik_smart",
"text":"北京大学是中国最好的高等学府之一"
}
# kibana 演示结果
{
"tokens": [
{
"token": "北京大学",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 0
},
{
"token": "中国",
"start_offset": 5,
"end_offset": 7,
"type": "CN_WORD",
"position": 1
},
{
"token": "最好",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 2
},
{
"token": "高等学府",
"start_offset": 10,
"end_offset": 14,
"type": "CN_WORD",
"position": 3
},
{
"token": "之一",
"start_offset": 14,
"end_offset": 16,
"type": "CN_WORD",
"position": 4
}
]
}
# ik_max_word 智能分词模式
GET _analyze
{
"analyzer": "ik_max_word",
"text":"北京大学是中国最好的高等学府之一"
}
# kibana 演示结果
{
"tokens": [
{
"token": "北京大学",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 0
},
{
"token": "北京大",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 1
},
{
"token": "北京",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 2
},
{
"token": "大学",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "中国",
"start_offset": 5,
"end_offset": 7,
"type": "CN_WORD",
"position": 4
},
{
"token": "最好",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 5
},
{
"token": "高等学府",
"start_offset": 10,
"end_offset": 14,
"type": "CN_WORD",
"position": 6
},
{
"token": "高等",
"start_offset": 10,
"end_offset": 12,
"type": "CN_WORD",
"position": 7
},
{
"token": "学府",
"start_offset": 12,
"end_offset": 14,
"type": "CN_WORD",
"position": 8
},
{
"token": "之一",
"start_offset": 14,
"end_offset": 16,
"type": "CN_WORD",
"position": 9
},
{
"token": "一",
"start_offset": 15,
"end_offset": 16,
"type": "TYPE_CNUM",
"position": 10
}
]
}
可以看出两种分词分词的效果不同
- 创建索引 指定分词器
# user 索引已经占用 这里我们使用user_test
PUT user_test
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_max_word", #设置字段保存分词
"search_analyzer": "ik_max_word" #设置自断搜索分词
}
}
}
}
总结
以上为elasticsearch+ik分词器的使用,感谢观看,加油

















 347
347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









