







目录
1 台大李宏毅教授课程
1注意力机制
1.1 序列模型的输入和输出
- 输入有很多种形式,常见的模型的输入是一个向量,但是注意力机制的输入可以是一组向量。
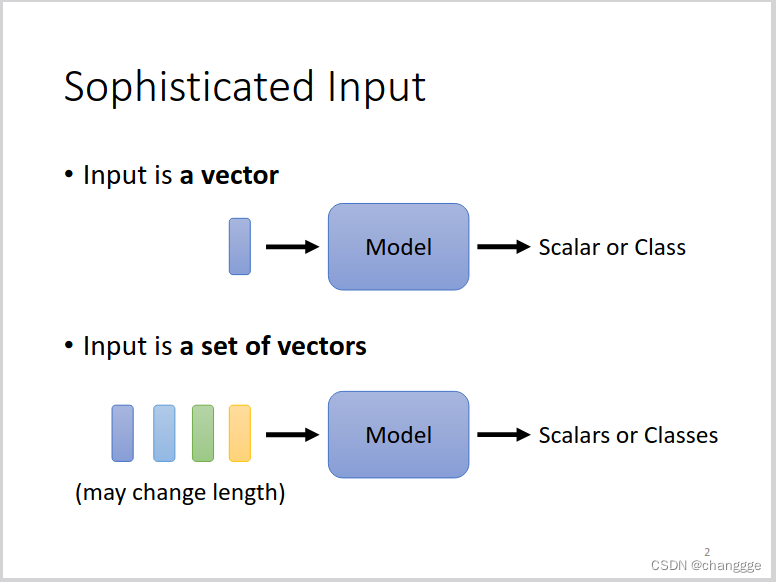
词汇等信息转化为向量可以通过one-hot编码或者word-enbedding等编码方式。声音、graph等也可以转化为向量作为注意力机制的输入。 - 输出也可以有多个形式。输出的个数与输入相同,也可以不同,也可以不同长度的输入向量只有一个输出。
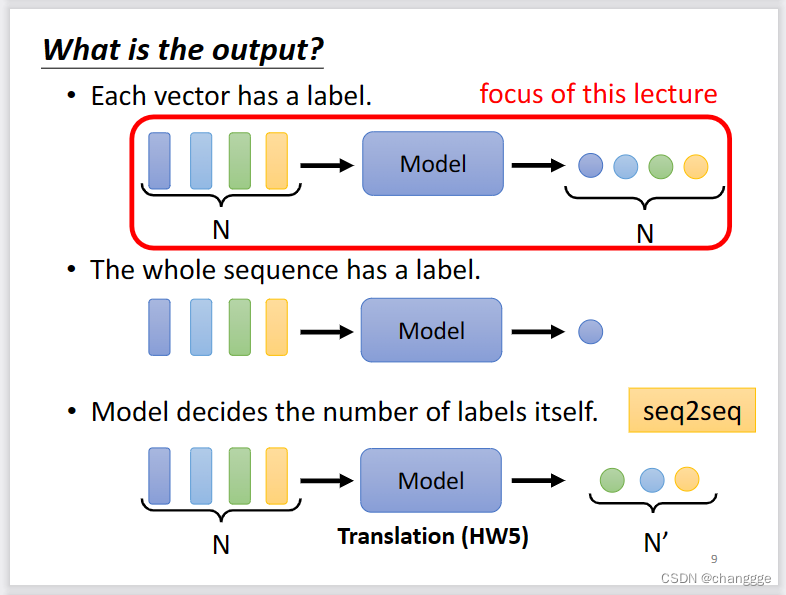
1.2 为什么需要self-attention
- 如下图,每个全连接网络输入多个向量,如果将window扩大到能够包含所有的输入,那么将会产生非常多的超参数。
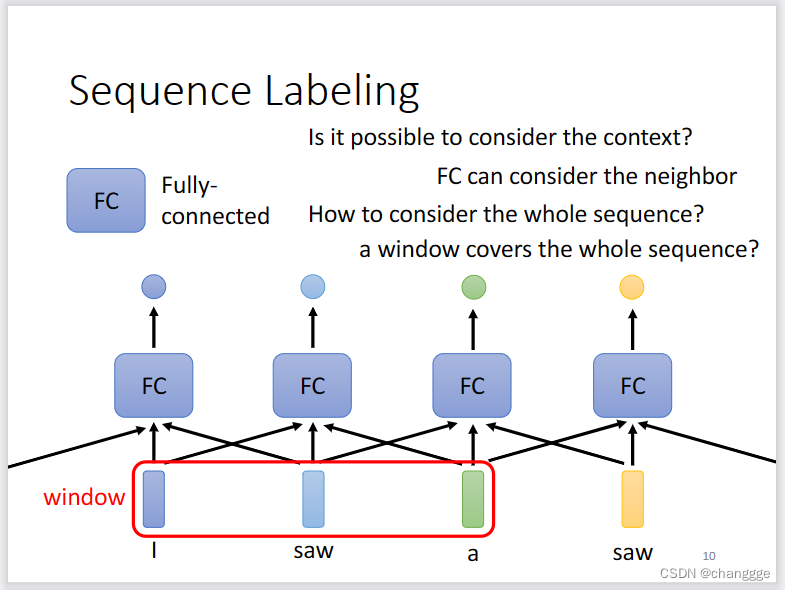
- 如果先将向量输入一个处理机制中进行统一处理,然后再输入到FC中,所以,就产生了self-attention。
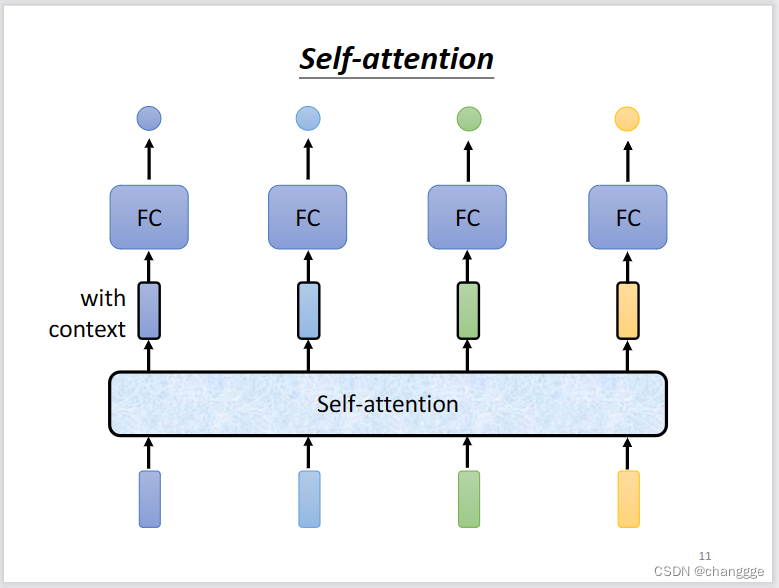
self-attention可以通过多次叠加得到更好的效果。
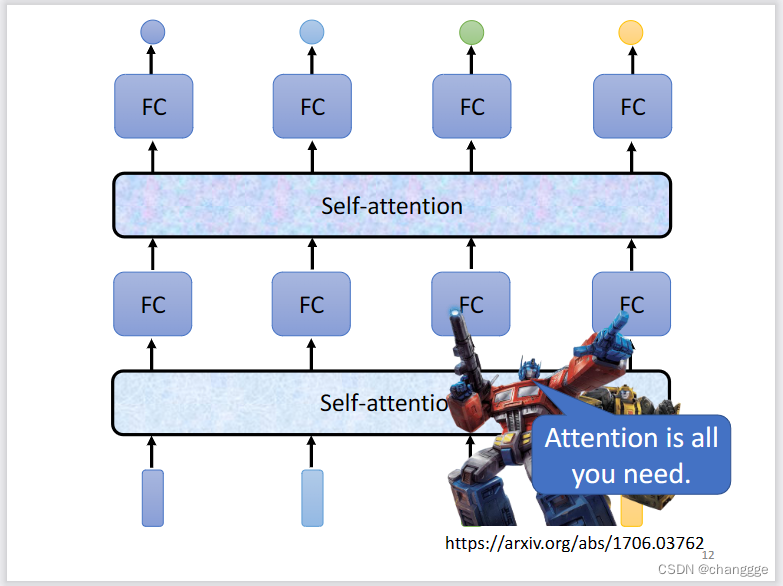
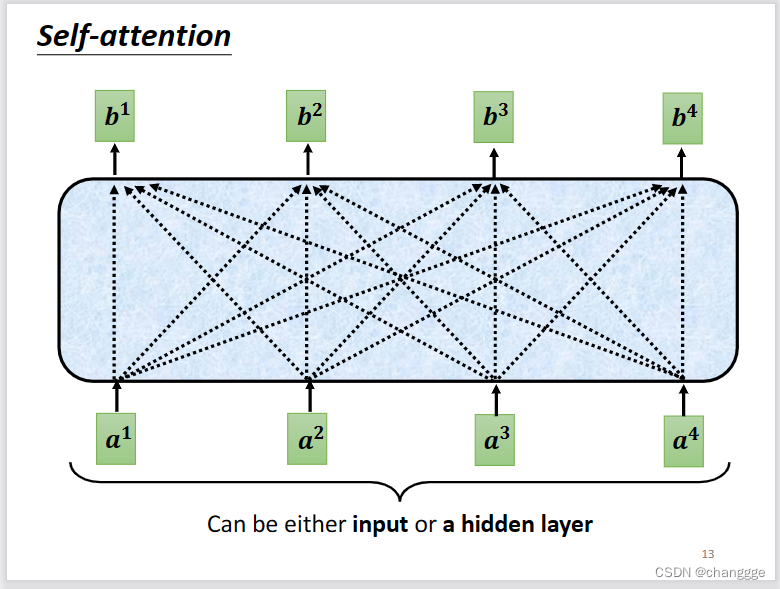
1.3 self-attention原理及计算方法
- 每个b都充分考虑了所有的a。
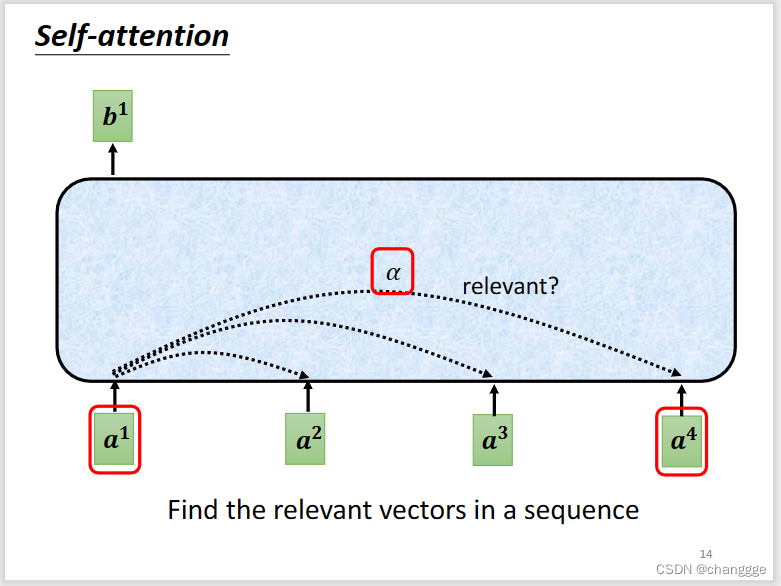
但是对于每一个b来说,并不是所有的a的相关性都相同,因此,需要先计算每个a与其它a之间的相关性alpha。比如计算a1与a4之间的相关性alpha。
如何计算α?有两种常用的方法:dot-product和additive。dot-product先将两个a与各自的特征矩阵相乘,然后做点积。
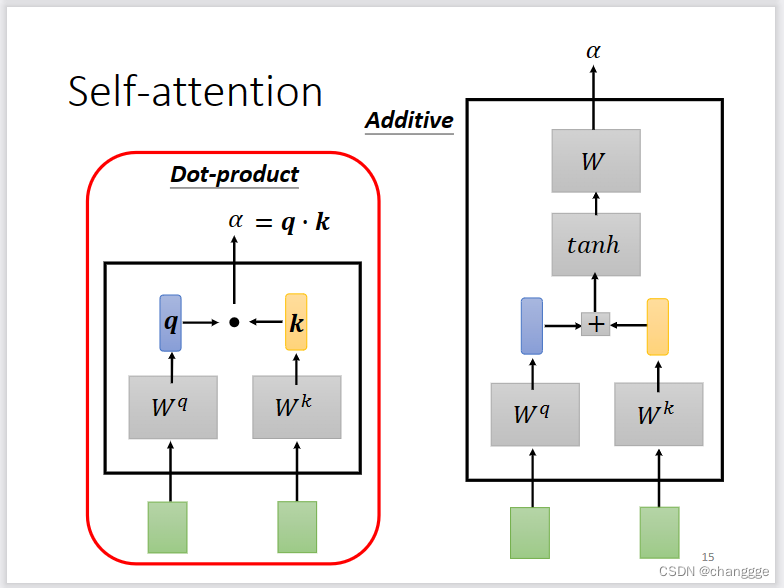
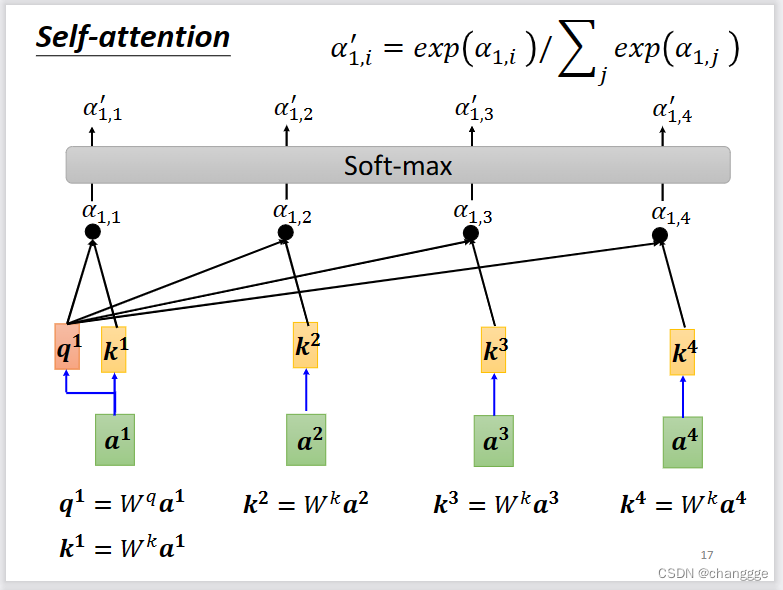
如何将α的计算方法应用到实际中呢?如下所示。以计算a1与其它a之间的相关性为例,a1会产生一个query:q1(向量),用做查询时的基础向量,然后每个a生成一个key:k(k是向量,a1也会生成k用于计算和自己的相关性),称为被查询相关性的向量。然后q1与每个a产生的k做dot-product产生各自的α,最后通过soft-max得到与a1与其它a的归一化相关性(alpha值是一个标量)。
然后,每个a通过与特定矩阵相乘得到value:v(向量),然后以各个a与a1的归一化相关性α作为权重,对v进行加权,最后得到a1的对应输出b1。
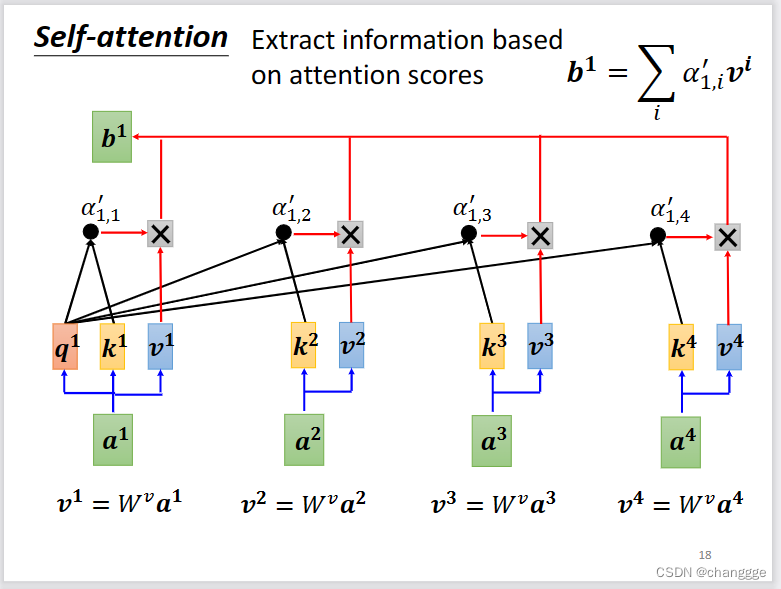
每个a对应的b的计算方式类似。
- self-attention的矩阵计算方法:
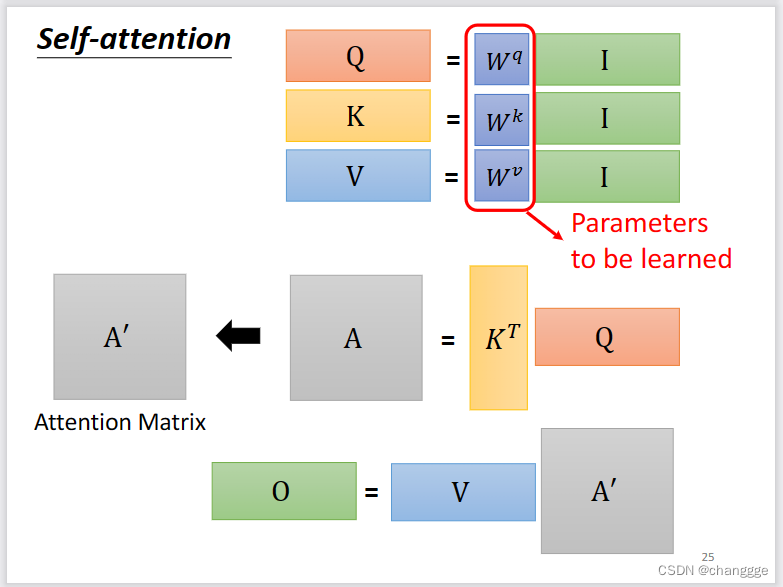
将a、q、k、v分别联结起来作为一个矩阵,然后根据原理抽象为矩阵之间的计算。
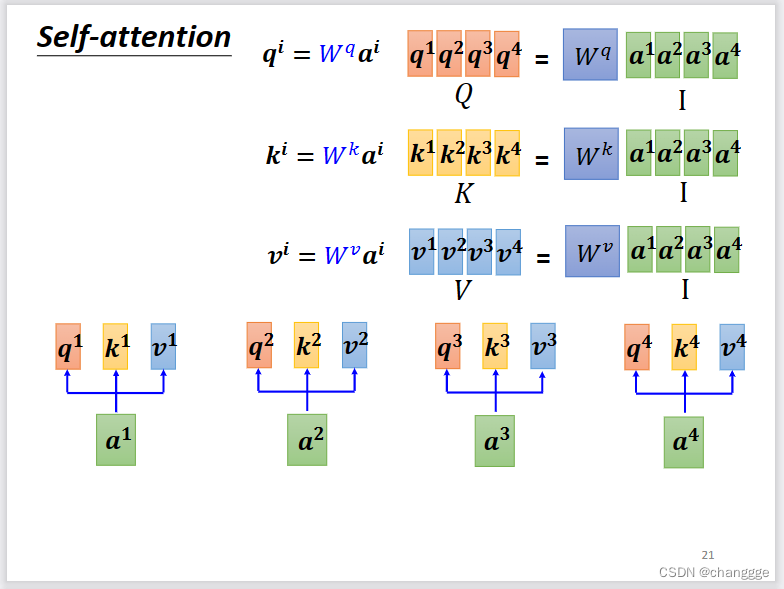
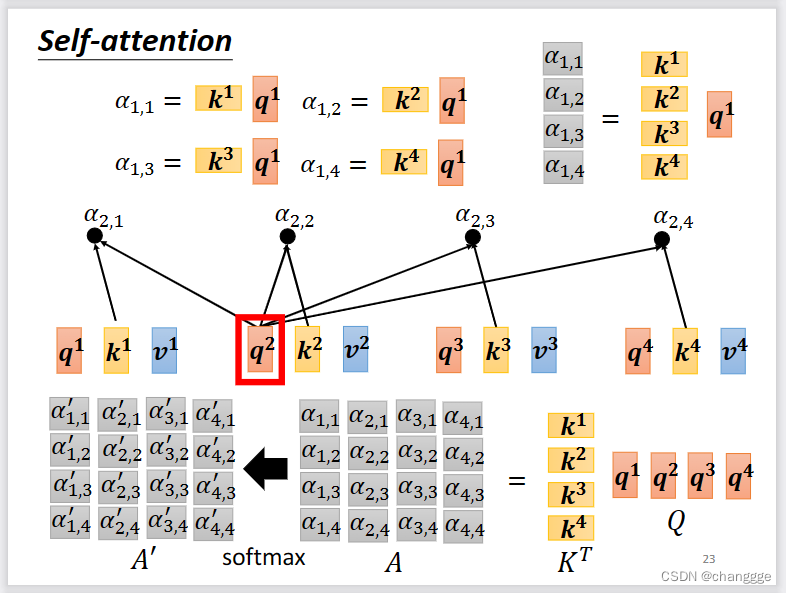
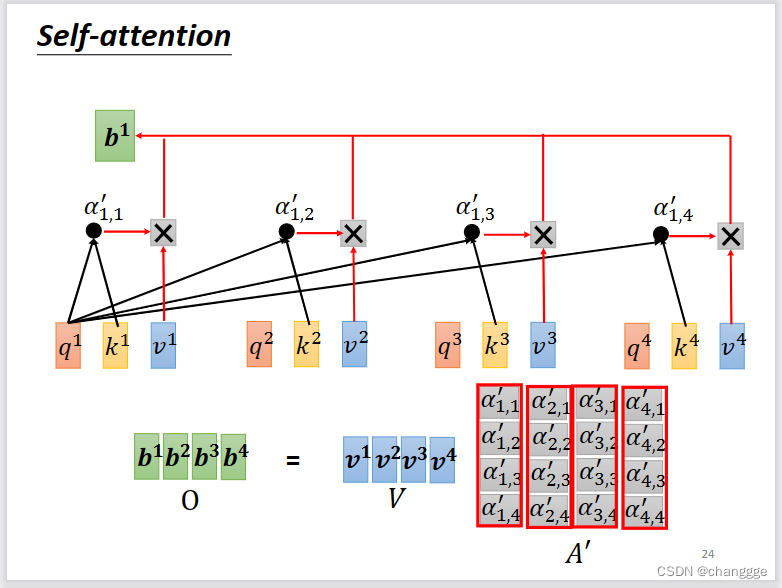
再进一步将向量抽象为矩阵,得到矩阵运算式。下图中能够通过梯度反向传播学习的参数只有三个W矩阵,而这三个矩阵会造成可调节的超参数量较少,从而限制self-attention的运用范围。
1.4 muti-head self-attention
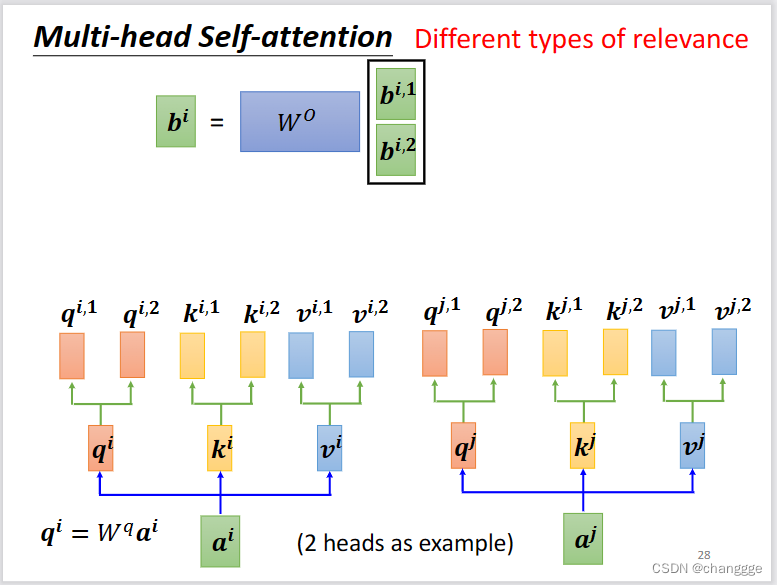
- 以2-head为例,将a乘以特定矩阵得到q、k、v之后,再将其分别乘以两个不同的矩阵,得到q11,q12。余下步骤与计算单头自注意力相似。
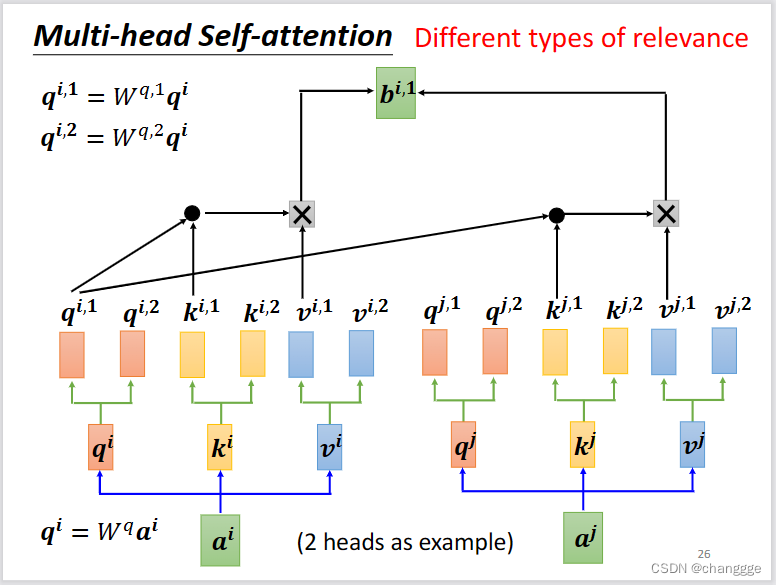
对a1计算得到b11、b12,再通过矩阵乘法得到最终的b1。
1.5 位置编码
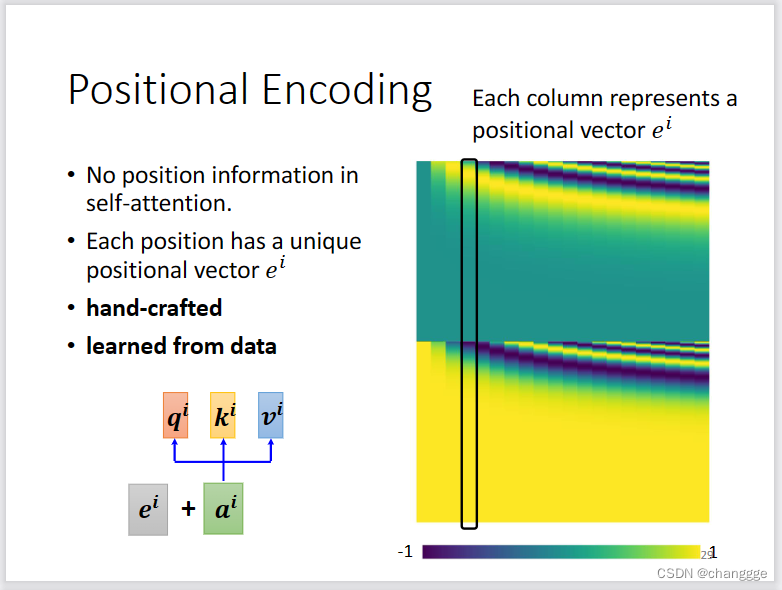
- 没有位置编码的self-attention对位置的感知不敏感,对向量之间的远近无概念。所以需要对每一个a添加一个位置向量,如果是手工设计的位置向量,可能会对性能产生影响,也可以通过学习的方式产生位置向量。
1.6 self-attention在图像上的应用
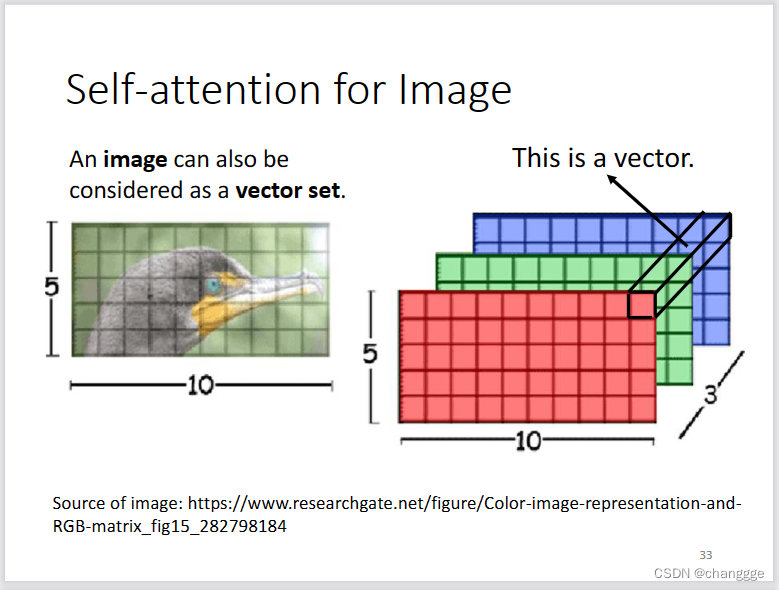
- 图像的每个像素点可以看作一个单独的向量,RGB图像的向量维度为3。
1.7 self-attention与CNN的区别
-
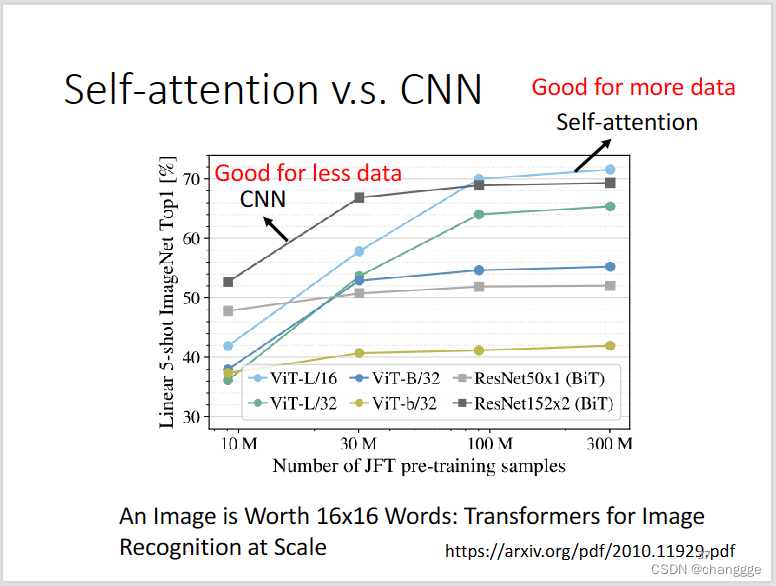
CNN的感受野与卷积核有关,是人为设定的;而self-attention的感受野是其自行学到的。

-
在数据量比较少的时候,CNN会更有优势,但是数据量比较充足的时候,self-attention会占优势。
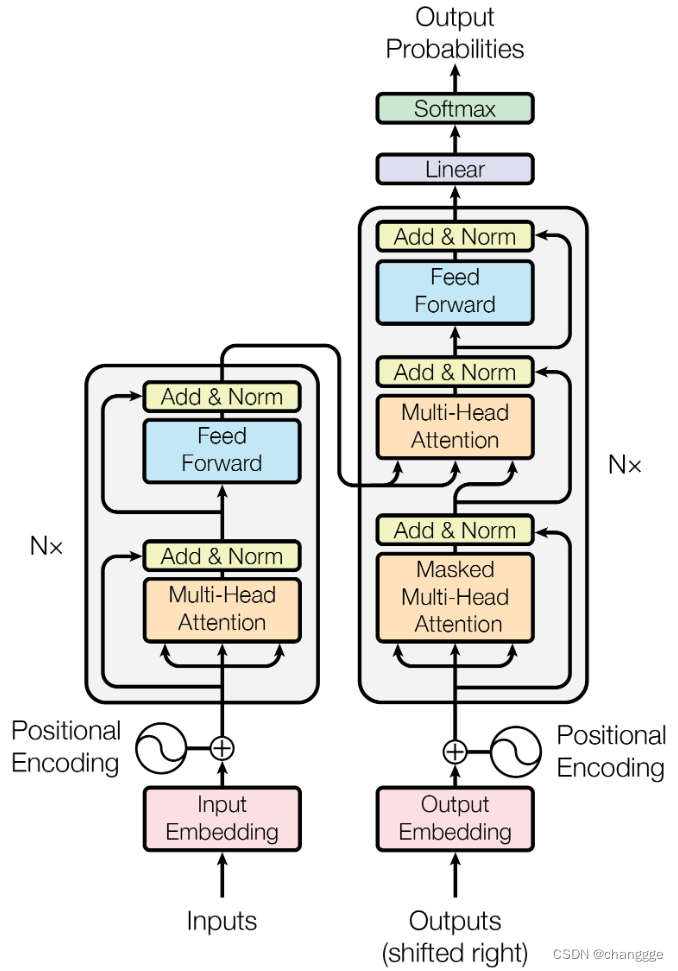
2 Transformer
2.1 Encoder
作用:输入一个seq,输出一个seq。相当于特征提取。
- Transformer需要一个encoder和一个decoder,encoder可以使用self-attention和RNN、CNN来代替。具体结构如下:
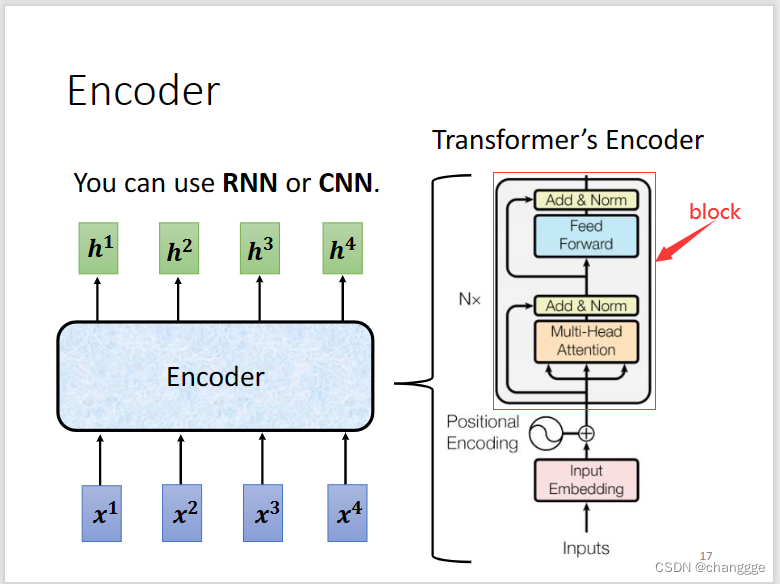
每一个Encoder由N个block叠加而成,block的结构如下,FC表示Free Forward。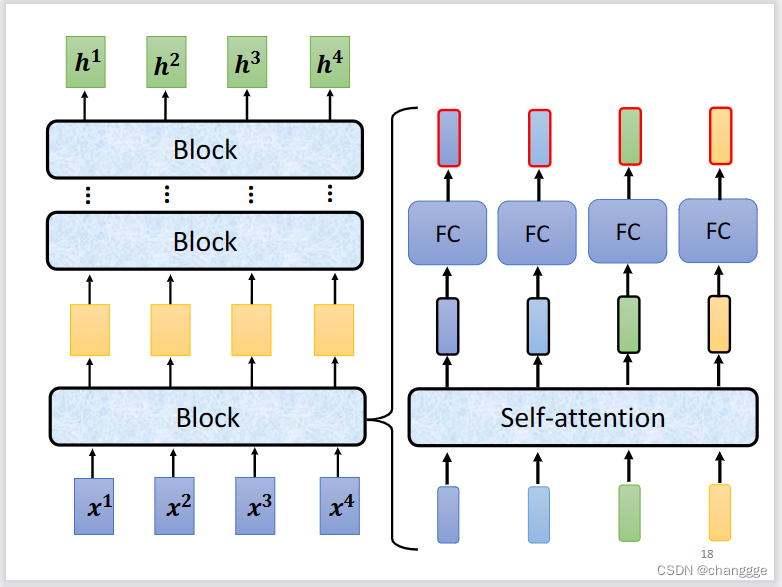
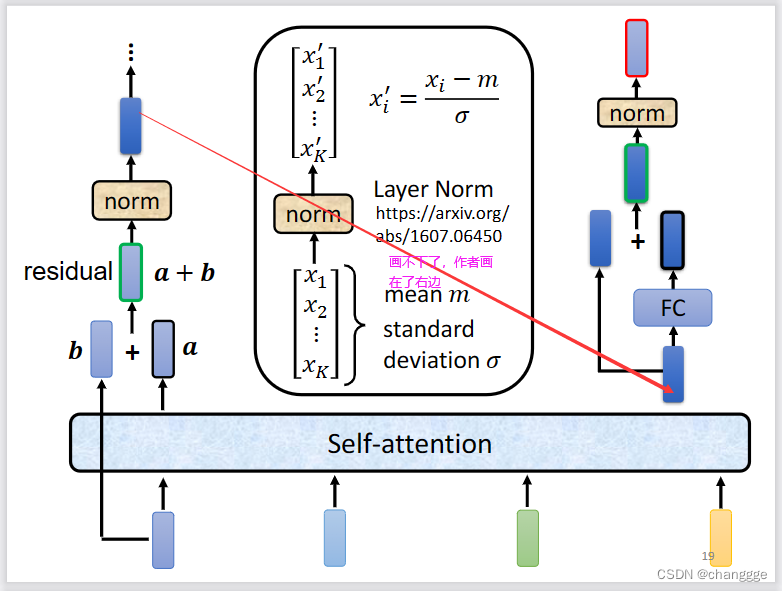
下图展示了更加完整的模型:
2.2 Decoder
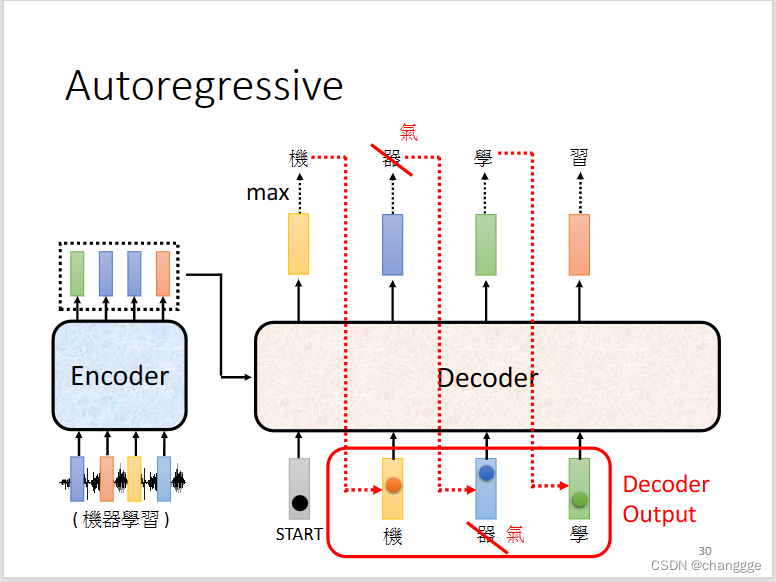
以autoregressive为例介绍decoder。
-
decoder会接收encoder输出的信息,在得到START指令之后,开始对input进行decode处理,然后将第一个输出作为输入并结合input得到第二个输出,如此循环往复。
decoder的具体结构如下图:
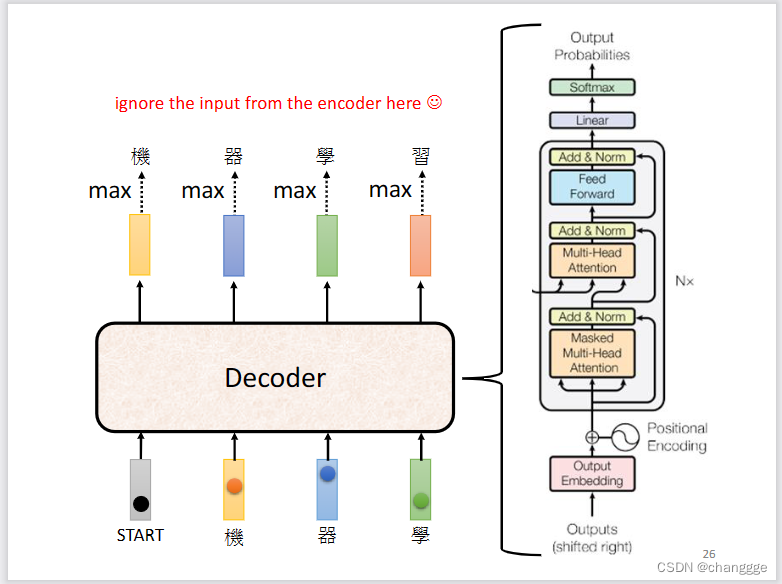
decoder需要自己学习输出的长度,但是需要给定输出的标志位才能使输出过程停止,此标志位为END: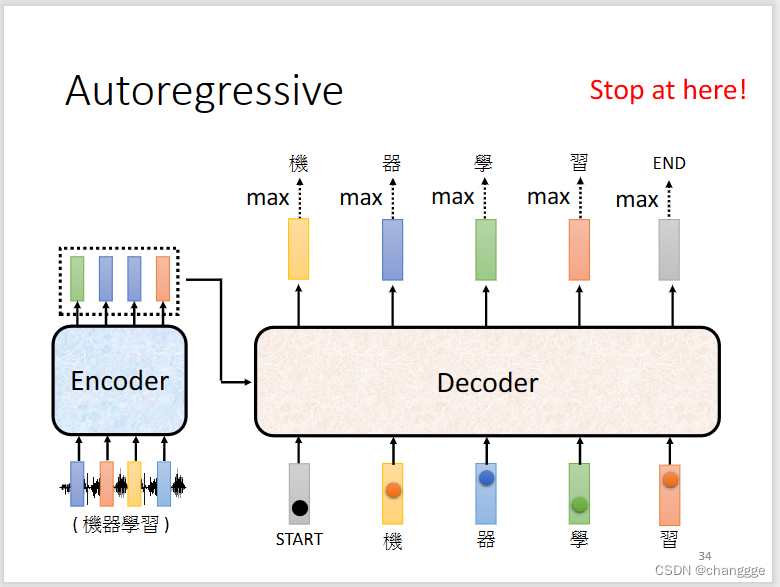
-
masked self-attention:在decoder中,当前位置的输出只考虑当前位置及以前的输入,而后面的输入不用考虑。
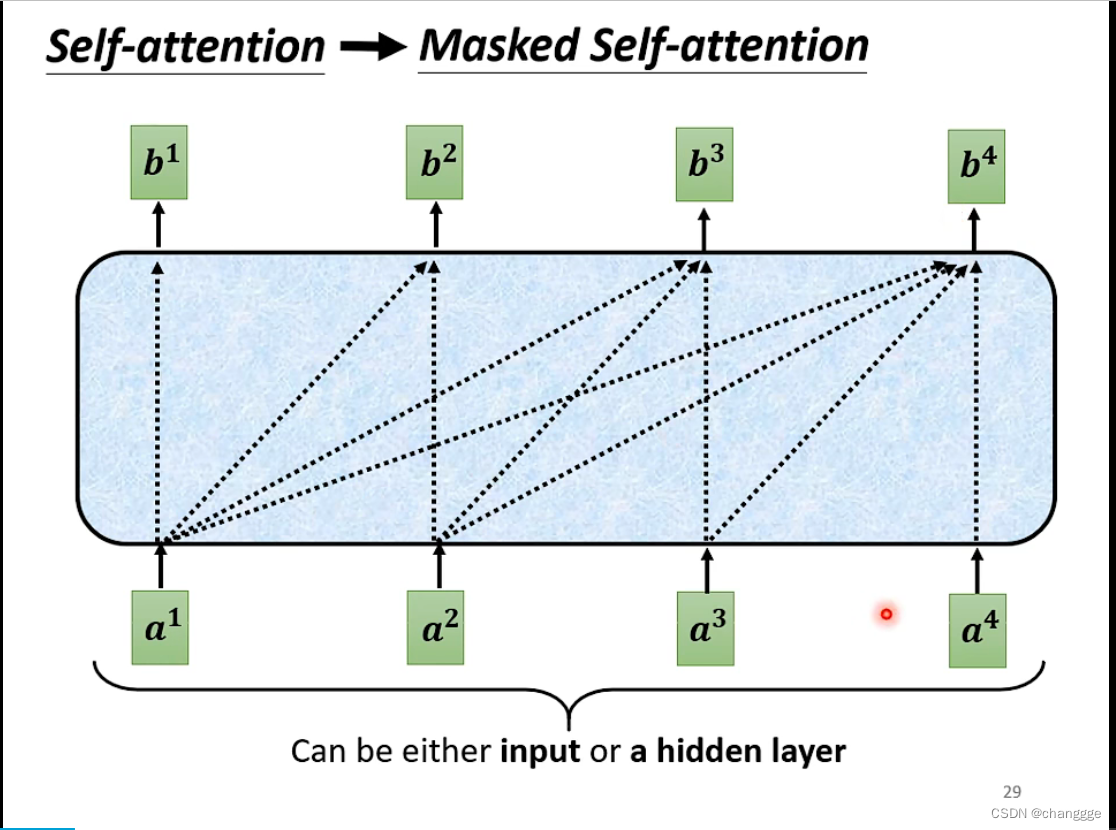
体现在计算上如下图所示:
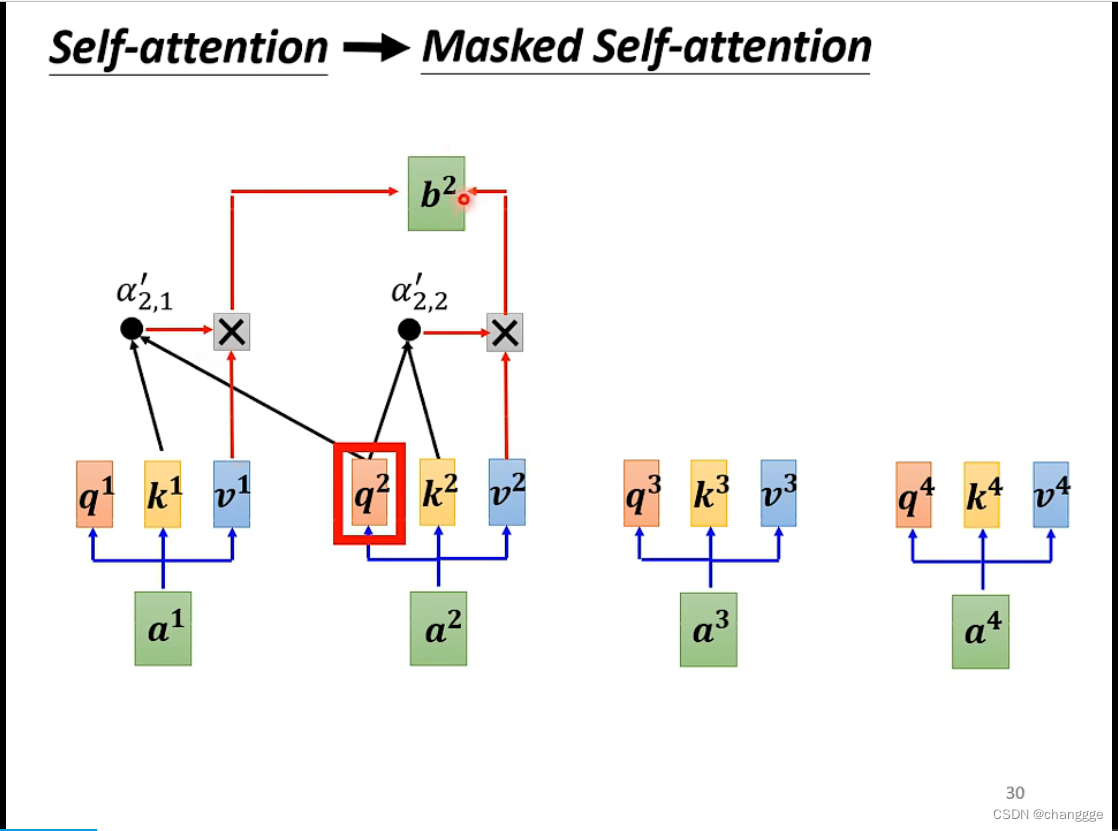
2.3 Encoder-Decoder
- 将encoder和decoder组合起来即为transformer的结构:
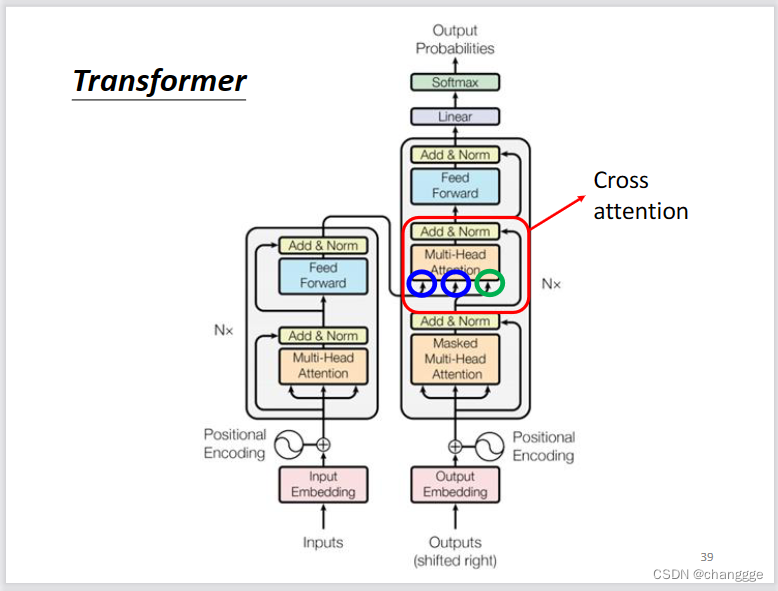
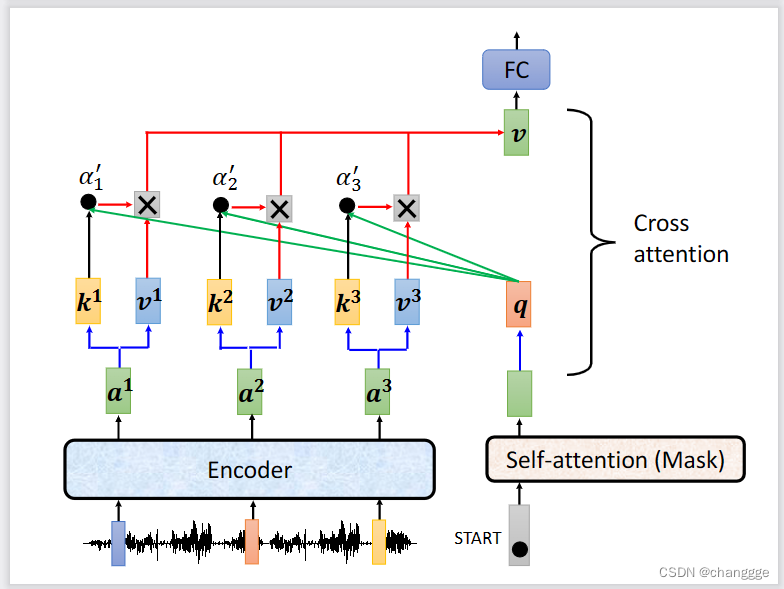
- cross-attention:使用encoder的输出作为k、v,然后decoder的输入作为q,因为q与k、v来自不同的地方,所以得名cross-attention。
注意力机制的数学表示
以一张
H
×
W
H\times W
H×W大小的特征图
X
^
∈
R
H
×
W
×
D
\hat{X}\in \mathbb{R}^{ H\times W\times D}
X^∈RH×W×D为例进行说明, D表示特征的通道维度。如果将二维特征图拉伸为一维向量表示,即
X
∈
R
H
W
×
D
X\in \mathbb{R}^{HW\times D}
X∈RHW×D,令
N
=
H
W
N=HW
N=HW,那么X可以表示为N个D维向量组成的二维向量。即
X
∈
R
N
×
D
X\in \mathbb{R}^{N\times D}
X∈RN×D。注意力机制的Q,K,V均来自可学习参数矩阵与输入X的矩阵运算,即
Q
=
X
W
Q
∈
R
N
×
D
Q
K
K
=
X
W
K
∈
R
N
×
D
Q
K
V
=
X
W
V
∈
R
N
×
D
V
Q=XW_{Q}\in \mathbb{R}^{N \times D_{QK}}\\ K=XW_{K}\in \mathbb{R}^{N\times D_{QK}}\\ V=XW_{V}\in \mathbb{R}^{N \times D_{V}}
Q=XWQ∈RN×DQKK=XWK∈RN×DQKV=XWV∈RN×DV
其中,
W
Q
,
W
K
∈
R
D
×
D
Q
K
W_{Q},W_{K}\in \mathbb{R}^{D\times D_{QK}}
WQ,WK∈RD×DQK,
W
V
∈
R
D
×
D
V
W_{V}\in \mathbb{R}^{D\times D_{V}}
WV∈RD×DV为可学习参数矩阵,由模型自行确定。
D
Q
K
D_{QK}
DQK和
D
V
D_{V}
DV的大小在一定程度上决定了模型的复杂度,它们决定输入可以映射为何种维度大小的向量。注意力权重可表示如下
W
i
g
h
t
=
s
o
f
t
m
a
x
(
Q
K
T
D
Q
K
)
∈
R
N
×
N
Wight=softmax(\frac{QK^{T}}{\sqrt{D_{QK}}})\in \mathbb{R}^{N\times N}
Wight=softmax(DQKQKT)∈RN×N
注意力可表示为
A
t
t
n
=
W
e
i
g
h
t
×
V
∈
R
N
×
D
V
Attn=Weight\times V\in \mathbb{R}^{N\times D_{V}}
Attn=Weight×V∈RN×DV
为了确保注意力能够迭代运算并且突出输入的特征表示,汲取出值得关注的部分,输入和输出应该保持相同的维度,即
D
=
D
V
D=D_{V}
D=DV。
为了提高模型的建模能力,多头注意力的表现优于单头。多头注意力机制可以表示为
M
u
l
t
i
H
e
a
d
(
Q
,
K
,
V
)
=
C
o
n
c
a
t
(
h
e
a
d
1
,
⋯
,
h
e
a
d
h
)
W
O
,
h
e
a
d
i
=
A
t
t
n
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
MultiHead(Q,K,V)=Concat(head_{1},\cdots ,head_{h})W^{O},\\ head_{i}=Attn(QW_{i}^{Q},KW_{i}^{K},VW_{i}^{V})
MultiHead(Q,K,V)=Concat(head1,⋯,headh)WO,headi=Attn(QWiQ,KWiK,VWiV)
其中,
W
i
Q
,
W
i
K
∈
R
D
Q
K
×
d
k
W_{i}^{Q},W_{i}^{K}\in \mathbb{R}^{D_{QK}\times d_{k}}
WiQ,WiK∈RDQK×dk,
W
i
V
∈
R
D
V
×
d
v
W_{i}^{V}\in \mathbb{R}^{D_{V}\times d_{v}}
WiV∈RDV×dv,
W
O
∈
R
h
d
v
×
d
k
W^{O}\in \mathbb{R}^{hd_{v}\times d_{k}}
WO∈Rhdv×dk。此外,h表示头数,
D
Q
K
=
D
V
D_{QK}=D_{V}
DQK=DV,
d
k
=
d
v
=
D
Q
K
h
d_{k}=d_{v}=\frac{D_{QK}}{h}
dk=dv=hDQK。















 279
279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









