







 本文详细介绍了Hadoop分布式文件系统(HDFS)、资源管理系统YARN和MapReduce计算框架。HDFS的核心特点是数据切块、多副本存储,确保高容错性。YARN负责资源调度,MapReduce则用于离线并行计算。文章还涵盖了HDFS的Python操作、环境搭建、shell命令使用以及MapReduce的工作原理。此外,讨论了Hadoop的优缺点、局限性和替代方案,如Spark和Hive。
本文详细介绍了Hadoop分布式文件系统(HDFS)、资源管理系统YARN和MapReduce计算框架。HDFS的核心特点是数据切块、多副本存储,确保高容错性。YARN负责资源调度,MapReduce则用于离线并行计算。文章还涵盖了HDFS的Python操作、环境搭建、shell命令使用以及MapReduce的工作原理。此外,讨论了Hadoop的优缺点、局限性和替代方案,如Spark和Hive。
Hadoop
概念
概念:开源、可靠(reliable)、可扩展(scalable) 分布式处理(储存、计算、统计、分析) 的文件系统基础框架
宗旨 : 使用简单编程模型 实现 计算机集群中大数据集 的 分布式处理(储存、计算、统计、分析)
作用:搭建大型数据仓库 或 PB级数据的存储 处理 分析 统计 等
- 可扩展性:可从单个服务器扩展到数千台,并且每台计算机都提供计算和存储,破解单台机器计算力和储存量不足的弊端
- 容错性: 不依靠硬件来提供高可用性(
high-availability),而是在应用层检测和处理故障,从而在计算机集群之上提供高可用服务
组成
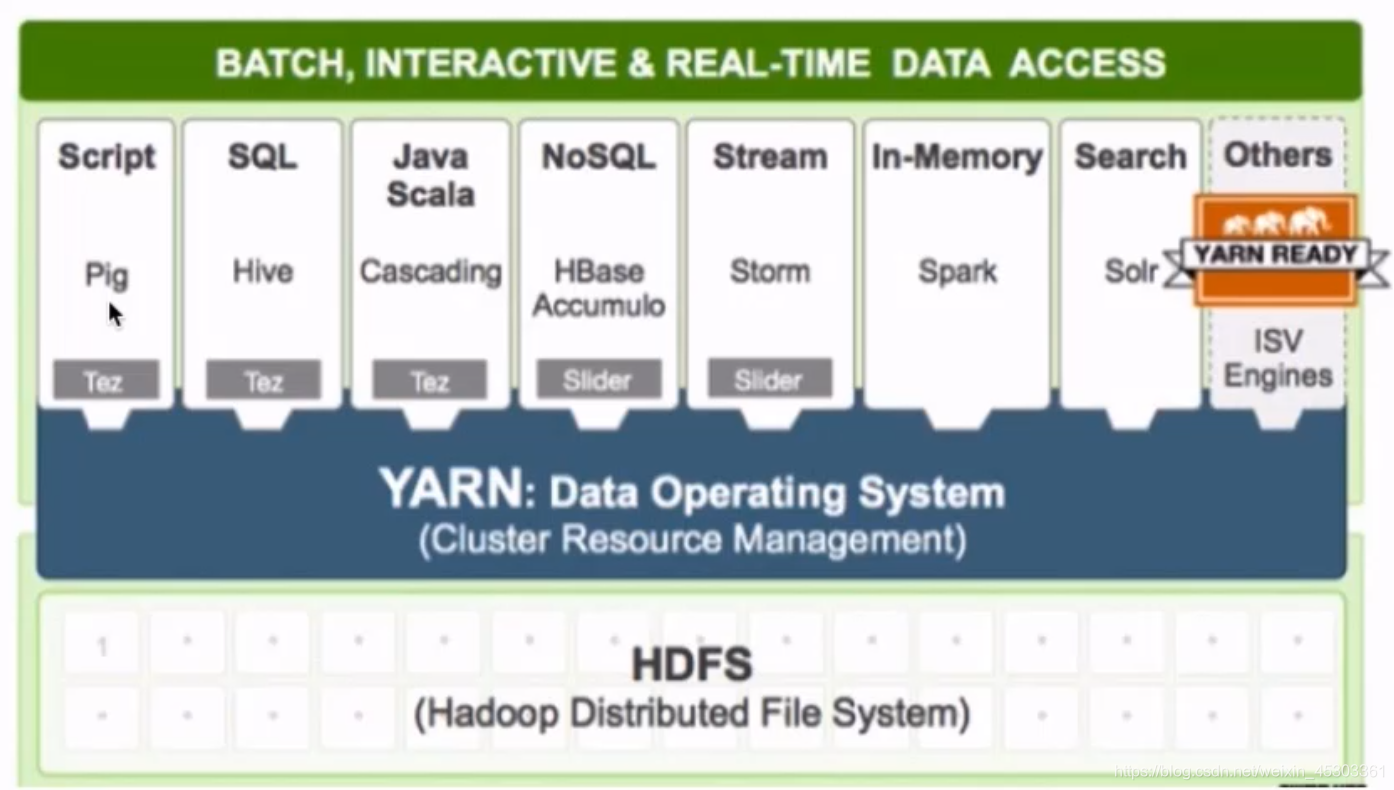
Hadoop主要分为三大核心部件:
HDFS:分布式文件系统。用于储存文件,源自于Google的GFS论文YARN:资源调度系统。负责整个集群资源的管理和调度MapReduce:分布式计算框架。 源于Google的MapReduce论文
Hadoop的框架最核心的设计就是:HDFS和MapReduce
HDFS:为海量的数据提供了存储MapReduce:为海量的数据提供了计算
HDFS 分布式文件存储系统
核心:数据切块(便于并行计算,益于负载均衡,单个块:128M)和多副本储存(防止数据丢失,保证容错)
HDFS采用master/slave架构。一个HDFS集群是由一个NameNode 简 NN 带 多个DataNodes 简 DN组成
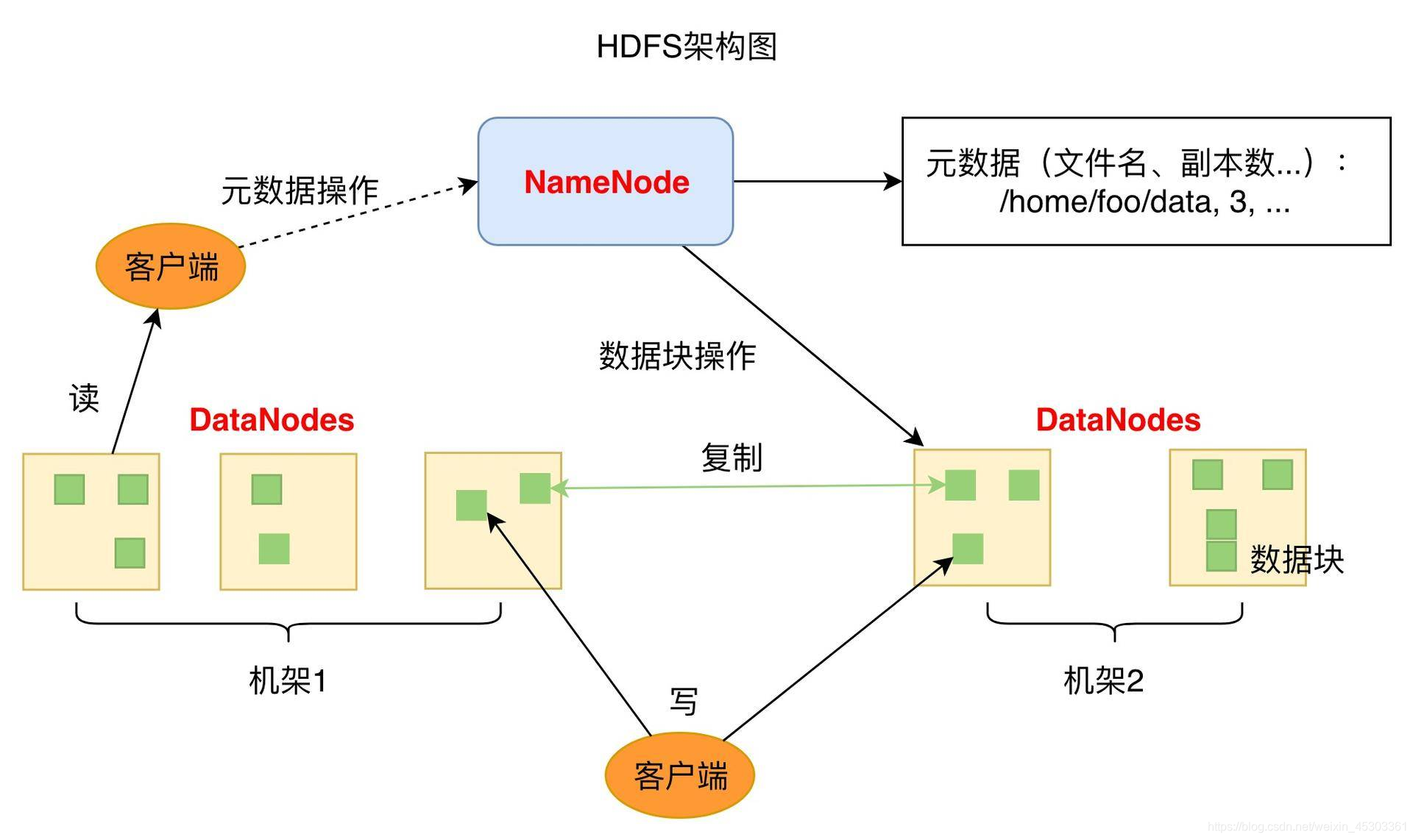
Namenode中心服务器- 负责 响应 客户端的请求
- 负责 管理 元数据 (
MetaData描述数据的数据,包括:文件的名称、副本系数、数据块存放的DN) - 负责 管理 数据块的复制,并监控
DataNode健康状况 (周期性地接收 每个Datanode发送的心跳信号和块状态报告(Blockreport), 10分钟没有收到DataNode报告,则认为Datanode死掉了)
Datanode节点- 负责管理自身节点上的数据存储
- 数据以文件的形式存储,一个文件其实被分成一个或多个数据块,这些块存储在一组
Datanode上 Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制Datanode负责执行Namenode发来的文件系统名字空间操作(打开、关闭、重命名文件或目录)- 要定期向
NN发送心跳信息,汇报本身及其所有的block信息,健康状况
HDFS优缺点:
- 优点
- 高容错性
- 数据自动保存多个副本。通过增加副本的形式,提高容错性
- 某一个副本丢失以后,它可以自动恢复,由
HDFS内部机制实现
- 适合批处理
- 它是通过移动计算而不是移动数据
- 它会把数据位置暴露给计算框架
- 适合大数据处理
- 处理数据达到 GB、TB、甚至PB级别的数据
- 能够处理百万规模以上的文件数量,数量相当之大
- 能够处理10K节点的规模
- 流式文件访问
- 一次写入,多次读取。文件一旦写入不能修改,只能追加
- 它能保证数据的一致性
- 可构建在廉价机器上
- 它通过多副本机制,提高可靠性
- 它提供了容错和恢复机制。比如某一个副本丢失,可以通过其它副本来恢复
- 高容错性
- 缺点
- 不适合低延时数据访问
- 比如毫秒级的来存储数据,它做不到
- 它适合高吞吐率的场景,就是在某一时间内写入大量的数据
- 无法高效的对大量小文件进行存储
- 存储大量小文件(这里的小文件是指小于HDFS系统的Block大小的文件(默认64M))的话,它会占用
NameNode大量的内存来存储文件、目录和块信息。这样是不可取的,因为NameNode的内存总是有限的 - 小文件存储的寻道时间会超过读取时间,它违反了HDFS的设计目标
- 存储大量小文件(这里的小文件是指小于HDFS系统的Block大小的文件(默认64M))的话,它会占用
- 并发写入、文件随机修改
- 一个文件只能有一个写,不允许多个线程同时写
- 仅支持数据
append(追加),不支持文件的随机修改
- 不适合低延时数据访问
HDFS环境搭建
卸载自带的java
查看已经安装的java
rpm -qa | grep java
java-1.6.0-openjdk-1.6.0.0-1.50.1.11.5.el6_3.i686
java-1.7.0-openjdk-1.7.0.9-2.3.4.1.el6_3.i686
删除openjdk版本
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.50.1.11.5.el6_3.i686
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.9-2.3.4.1.el6_3.i686
jdk和hadoop解压安装
解压:tar -zxvf 压缩包名字 -C ~/安装路径
配置环境变量
vi ~/.bash_profile
export JAVA_HOME=/root/bigdata/jdk
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/root/bigdata/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
保存退出后
执行:source ~/.bash_profile
进入到解压后的hadoop目录 修改配置文件
-
配置文件作用
core-site.xml 指定hdfs的访问方式 hdfs-site.xml 指定namenode 和 datanode 的数据存储位置 mapred-site.xml 配置mapreduce yarn-site.xml 配置yarn-
修改
hadoop-env.shcd etc/hadoop vi hadoop-env.sh #找到下面内容添加java home export_JAVA_HOME=/root/bigdata/jdk -
修改
core-site.xml在configuration节点中添加<configuration> <property> <name>hadoop.tmp.dir</name> # hadoop临时文件存储位置 <value>file:/root/临时文件存储路径/tmp</value> </property> <property> <name>fs.defaultFS</name> # hadoop 默认IP和端口 <value>hdfs://IP地址:9000</value> </property> </configuration> -
修改
hdfs-site.xml在configuration节点中添加<property> <name>dfs.namenode.name.dir</name> # NameNode存储位置 <value>/root/NameNode存储路径/name</value> </property> <property> <name>dfs.datanode.data.dir</name> # DataNode存储位置 <value>/root/DataNode存储路径/data</value> </property> <
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1346
1346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









