






文章目录
一. 事务简介
1. 概念(关键词:一组操作)
数据库事务 指的是一组操作的集合,是一个不可分割的工作单位,可以由 1~n 条 sql语句 组成。
在同一个事务当中,这些操作最终要么全部执行成功,要么全部失败,不会存在部分成功的情况。
❗ 注意区分概念:
MySQL存在DDL(Data Definition Language)和DML(Data Manipulation Language)两种语句,前者用于定义数据库对象的结构,例如创建、修改或删除表、索引等,后者用于操作数据库中的数据,例如SELECT、INSERT、UPDATE、DELETE等。
而我们指的【事务】,是DML语句的组合,而非DDL。
举个例子:
👉 我们单独执行一条SQL语句,他会立即执行;其实该SQL会被当作一个独立的事务,该事务会立刻执行并且提交。
👉 如果单独运行一条DDL语句,它也会立即执行,但是MySQL不会把DDL当作一个事务去处理。
👉 所以,我们可以显式的使用BEGIN、COMMIT、ROLLBACK来控制一组DML语句,也就是一个事务,但是这其中必然不会包含DDL的成分。
2. 特性(ACID)
- 原子性(Atomicity):最小操作单元,全部成功 or 全部失败;
- 一致性(Consistency):事务完成时,必须使所有数据都保持一致状态,即从实际的业务逻辑上来说,最终结果是对的、是跟程序员的所期望的结果完全符合的;
- 隔离性(Isolation):DB提供隔离机制,保证事务在不受外部并发操作影响的独立环境下运行;
- 持久性(Durability):提交或回滚,对DB中数据的改变是永久的。
结合案例说明:
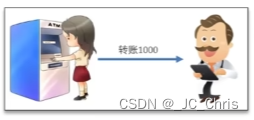
【事务:A向B转账1000元】=【操作1:A减1000元】+【操作2:B加1000元】
- 原子性:A减1000 和 B加1000 同成败;
- 一致性:转账事务的结果和预期一致;
- 隔离性:A向B转账的过程中,不能受外界因素的干扰;
- 持久性:转账后双方的余额情况要保存记录下来。
(原子性、一致性、持久性 比较好理解;针对隔离性则会有一系列的问题。)
接下来将介绍 隔离性“连环两问”:并发事务问题 + 隔离级别问题 。
二. 并发事务
并发事务将会带来一系列的问题,最常见的是以下三种:
| 问题 | 描述 |
|---|---|
| 脏读 | 一个事务读到另一个事务还没有提交的数据 |
| 不可重复读 | 一个事务先后读取同一条记录,但两次读取的数据不同 |
| 幻读 | 【读不到、插不进】 一个事务按照条件查询数据时,没有对应的数据行;但是在插入数据时,又发现这行数据已经存在,好像出现了“幻影”。 |
结合一些典型错误案例进行更好的理解。
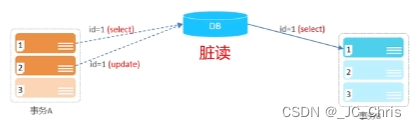
1. 脏读
事务A修改某data,但事务A未提交,随时可能回滚或再次修改data;但是此时事务B查询该data。若最后事务A回滚,事务B读到的就是脏数据。
2. 不可重复读
事务A中会读取data两次,但在两次读取之间,事务B修改了data并完成提交,事务A两次获取到的data是不同的。

3. 幻读
我们看下面这幅图,事务A的 第一、第三条SQL 都是读取同一个data,但是都未成功。这是为什么?按理说第三条SQL执行时DB内已经拥有data数据。

这是因为该案例已经解决了【不可重复读】的问题,即:在一个事务中,对DB内同一个数据的读取结果强制保持了一致。
① 事务A的SQL1 率先查询某个data,但此时DB中还没有data;并且由于已经解决了“不可重复读”问题,此时事务A将默认DB中绝对不存在data!
② 事务B的SQL1 紧接着就插入了data,并完成提交。
③ 事务A的SQL2 继续执行,但是恰好这也是一条插入data的语句;显然,当事务B提交后,DB中的data就已经确定下来了,事务A的SQL2 违反唯一约束,必定是插不进去的。
④ 事务A的SQL3 随即再次查询data,但 【可重复读】 告诉 “事务A”:对同一个data的读取结果必须一致! 所以结果依旧保持与 事务A的SQL1 一样:读不到!
4. 总结与方案
分析了经典错误案例之后,我们用大白话简单总结以下,加深印象:
- 脏读:A读到B 没确认 的数据,B会随时 “反悔 / 变卦” ;
- 不可重复读:A想获取data × 2次,结果data 中间被B改掉,A获取的data 前后不一致;
- 幻读:由于B的抢先插入,导致A “读不出、插不进”。
小剧场:【事务A:供货商1】【DB:商店】【事务B:供货商2】
A:DB,有没有货?
DB:没有。(A确认了DB无货状态)
B:DB,我进货给你!(成功)
A:DB,我进货给你!(失败)
A:DB没货,DB也不收货…出幻觉了?
👉 对于A来说,既确认了DB没货(读不出),有无法给DB进货(插不进)。
要解决三大并发事务问题,就要对事物进行隔离,设置合理的MySQL 事务隔离级别。
三. 隔离级别
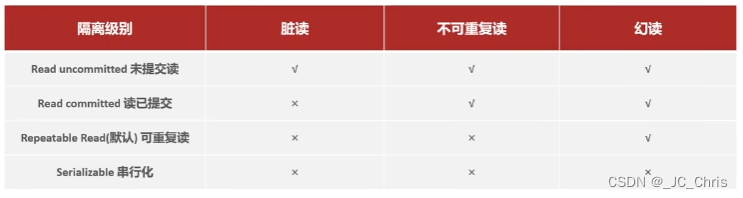
在上表中,越靠下则隔离级别越高,数据越安全,能够处理的并发事务问题越多;但是性能也会越弱。
所以,为了兼顾安全与性能,我们通常会保持MySQL 默认 的事务隔离级别:可重复读 Repeatable Read(RR)。个别情况也会斟酌使用 读已提交 Read Committed(RC)。
四. redo log 与 undo log
1. 背景
为了减少磁盘IO,加快处理速度,计算机都是把磁盘中经常增删改查的数据读取到缓存池(Buffer Pool)当中进行处理的;若缓存池中没有,才从磁盘中调取。

但是如果服务器宕机,缓存池中的数据就无法持久化到磁盘,导致数据丢失。
2. redo log(宕机恢复)
redo log,又称 “重做日志” ,记录事务提交时数据页的物理修改,用来实现事务的持久性,即用于 崩溃恢复 。
【redo log】=【redo log buffer:内存中】+【redo log file:磁盘中】
当事务提交后,redo log buffer 会把所有修改信息立即存储到 redo log file 中;如果发生错误,则通过磁盘中的 redo log file 进行数据恢复。
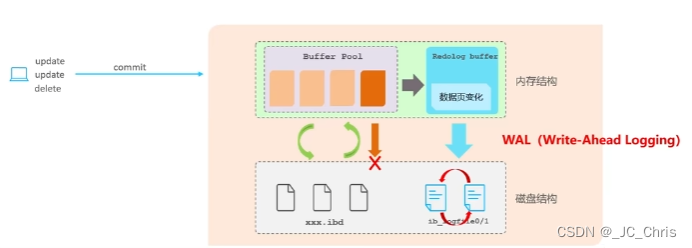
考虑一个问题:为什么当 Buffer Pool 发生变化后,不选择直接同步到磁盘?
① 因为事务的操作是多样的(增删改查),从Buffer Pool直接同步磁盘使用的是 随机的磁盘IO,效率会非常低;
② 通过 redo log buffer 同步 redo log file 是 顺序的磁盘IO,只需要不停追加日志文件即可,效率非常高。
所以看似效果相同,但是效率差距非常大。
3. undo log(事务回滚)
undo log,又称 “回滚日志” ,记录数据被修改前的信息,用于事务回滚与MVCC。
① undo log 是逻辑日志,要从逻辑层面理解设计。例如:当事务执行了一条 delete 语句时,undo log 中就会追加一条对应 相反的 insert 记录;执行了一条update 时,undo log 会追加一条 相反的 update 记录。
② redo log 是 物理日志,不停的记录数据页的物理变化即可。
当执行rollback时,就可以从 undo log 中的逻辑记录读取到相应的内容,并进行回滚。
undo log 有效的实现 事务的一致性和原子性。
4. 拓展:MySQL三大日志
MySQL的三大日志:binlog、redo log、undo log。
前文已经详细的介绍了 redo log 和 undo log 的原理与作用。
我们可以回顾一下,在【面试资料】Redis篇 之 双写一致…中提到过的知识点:在 双写一致性 的 弱一致(异步通知) 解决方案当中,【基于MQ】和【基于阿里的Canal】都是非常流行的解决方式;其中Canal就是通过获取MySQL的binlog文件,来达到监听DB数据变化的效果。
在一个 “读写分离、主从同步” 的数据库当中,三大日志分别有自己的作用:
- redo log:宕机恢复,保证事务【持久性】
- undo log:事务回滚,保证事务【原子性、一致性】
- binlog:主从复制,保证数据【一致性】
更多有关 binlog 以及 MySQL主从同步 的内容,请关注后续的【面试资料】MySQL篇。
👉 欢迎阅读【面试资料】MySQL篇 之 主从同步原理















 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









