







说明
系统:Ubuntu18.04-server
节点:
| 节点 | IP | 备注 |
|---|---|---|
| tmp1 | 172.19.79155 | master,hive |
| tmp2 | 172.19.79156 | slaves1 |
| tmp3 | 172.19.79157 | slaves2 |
软件包:
主机映射
sudo vim /etc/hosts
#127.0.1.1 tmp1
172.19.79.155 tmp1
172.19.79.156 tmp2
172.19.79.157 tmp3
ssh免密
test@tmp1:~$ ssh-keygen -t rsa
test@tmp1:~$ ssh-copy-id tmp1
test@tmp1:~$ ssh-copy-id tmp2
test@tmp1:~$ ssh-copy-id tmp3
Java安装
cd /home/test
tar -xf jdk-8u121-linux-x64.tar.gz
ln -s jdk1.8.0_121 jdk-1.8
# 配置环境变量,在profile文件最后添加java的环境变量
vim /etc/profile
export JAVA_HOME=/home/test/jdk-1.8
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
# source /etc/profile
# java -version
java version "1.8.0_121"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)
# 在其他两个节点上重复上述操作
hadoop安装
简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
HDFS,Hadoop Distributed File System,是一个分布式文件系统,用来存储 Hadoop 集群中所有存储节点上的文件,包含一个 NameNode 和大量 DataNode。NameNode,它在 HDFS 内部提供元数据服务,负责管理文件系统名称空间和控制外部客户机的访问,决定是否将文件映射到 DataNode 上。DataNode,它为 HDFS 提供存储块,响应来自 HDFS 客户机的读写请求。
MapReduce是一种编程模型,用于大规模数据集的并行运算。概念"Map(映射)“和"Reduce(归约)”,是它们的主要思想,即指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
环境变量配置
cd /home/test
tar -xf hadoop-2.7.2.tar.gz
ln -s hadoop-2.7.2 hadoop
配置环境变量,在profile文件最后添加hadoop的环境变量
vim /etc/profile
export HADOOP_HOME=/home/test/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin
source /etc/profile
# 配置文件主要在/home/test/hadoop/etc/hadoop下面
# cd /home/test/hadoop/etc/hadoop
# 把该文件<configuration>那块按如下修改
[root@master hadoop]# vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://tmp1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/test/hadoop/data</value>
</property>
</configuration>
# 配置文件中的/usr/local/data是用来存储临时文件的,所以该文件夹需要手动创建
mkdir /home/test/hadoop/data
##################################################
配置hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/home/test/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/test/hadoop/data/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin
#####################################################
# 先修改文件名字
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
###############################################3
vim yarn-site.xml
[root@master hadoop]# vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>tmp1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
##############################################
修改slaves文件
vim slaves
tmp2
tmp3
#######################################3
修改hadoop-env.sh文件
# 在“export JAVA_HOME=”那一行把java环境修改成自己的路径
vim hadoop-env.sh
export JAVA_HOME=/home/test/jdk-1.8
以上步骤在从2,3上执行一遍;
测试:
# 在主节点上启动,执行过程可能稍慢
# 先格式化
hdfs namenode -format
# 启动hdfs
cd /home/test/hadoop
sbin/start-dfs.sh
# 启动yarn
sbin/start-yarn.sh
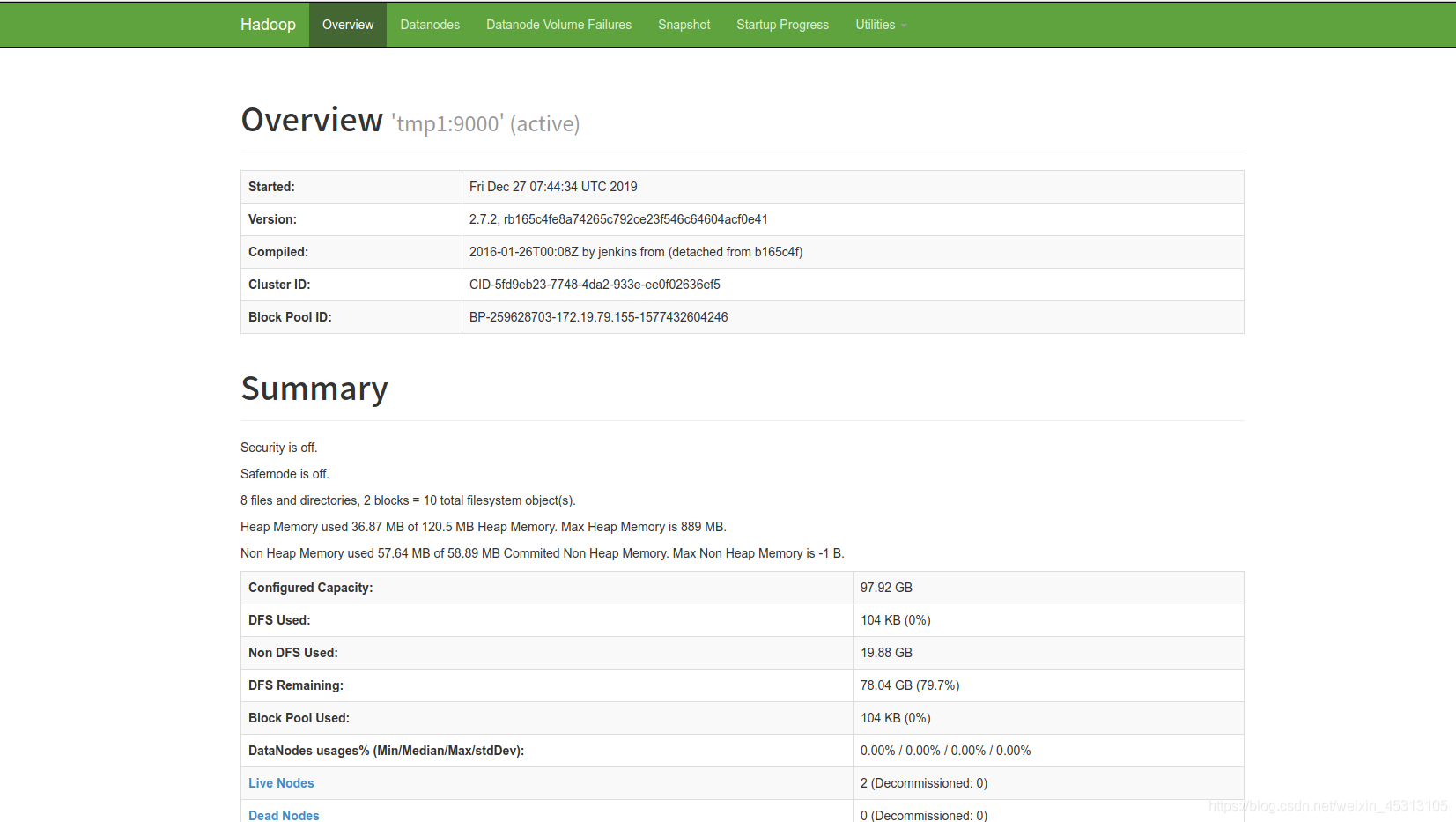
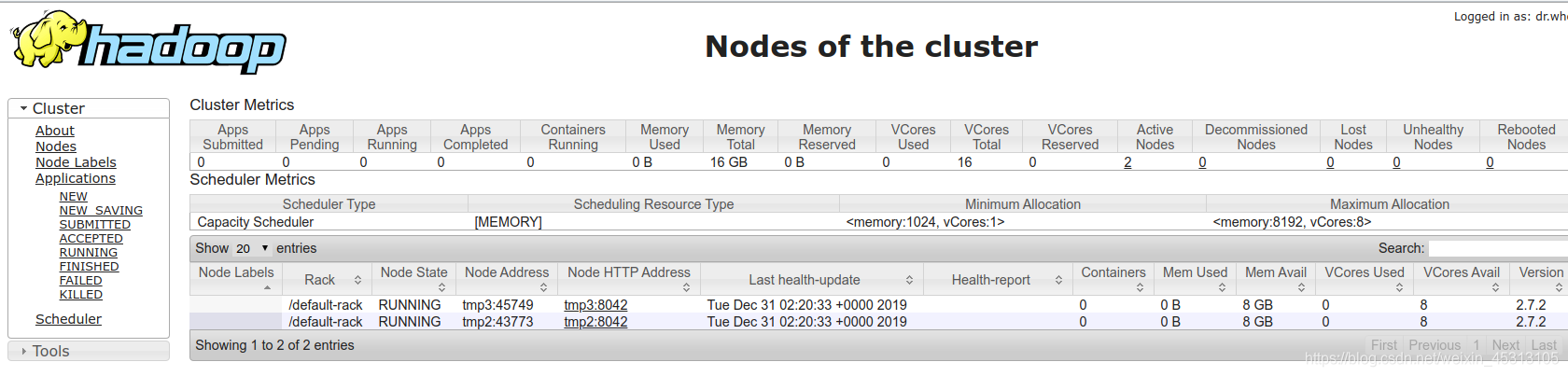
在浏览器上访问可视化页面:http://172.19.79.155:50070
hive 安装
简介
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过和SQL类似的HiveQL语言快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
Hive 没有专门的数据格式。所有Hive 的数据都存储在Hadoop兼容的文件系统(例如HDFS)中。Hive 在加载数据过程中不会对数据进行任何的修改,只是将数据移动到HDFS中Hive 设定的目录下,因此,Hive 不支持对数据的改写和添加,所有的数据都是在加载的时候确定的。
环境变量配置
#安装包解压等略
sudo vim /etc/profile
########hive###########
export HIVE_HOME=/home/test/apache-hive
export HIVE_CONF_DIR=/home/test/apache-hive/conf
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin
####################################3
#修改 hive-site.xml
#添加以下4个内容
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://172.19.79.155:3306/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=utf-8&useSSL=false</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
#########################################3
#修改hive-env.sh文件
mv hive-env.sh.template hive-env.sh
vim hive-env.sh
添加:
export JAVA_HOME=/home/test/jdk-1.8
export HIVE_CONF_DIR=/home/test/apache-hive/conf
export HADOOP_HOME=/home/test/hadoop
export HIVE_HOME=/home/test/apache-hive
########################################################
#将/home/test/mysql-connector-java.jar这个jar包拷到/home/test/hive/lib/下面
#######################################################
#安装并配置mysql-server(因为hive的元数据是存储在mysql里的)
sudo apt-get install mysql-server
sudo su
mysql
use mysql
select user,host, plugin from mysql.user;
Delete FROM user Where User='root' and Host='localhost';
grant all privileges on *. * to root@'%' identified by "123456";
###########################################################
#初始化:
schematool -dbType mysql -initSchema
###############################################################
#测试验证
##随便建立一个文件,写入一些内容,等下导到hive中去。
vim 1.txt
1,ggggg
2,ffffffff
3,发发发发
4,扰扰攘攘
5,456789
##进入hive
###创建users表,这个row format delimited fields terminated by ','代表我们等下导过来的文件中字段是以逗号“,”分割字段的
###所以我们上面users.txt不同字段中间有逗号
>create table users(id int, name string) row format delimited fields terminated by ',';
OK
Time taken: 7.29 seconds
###导数据
>load data local inpath '/home/test/apache-hive/1.txt' into table users;
Loading data to table default.users
OK
Time taken: 0.176 seconds
###查询
>select * from users;
hive报错
zookeeper安装
简介:
ZooKeeper是一个分布式的应用程序协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。其目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
那么Zookeeper能做什么事情呢?举个简单的例子:假设我们有20个搜索引擎的服务器(每个负责总索引中的一部分的搜索任务)和一个总服务器(负责向这20个搜索引擎的服务器发出搜索请求并合并结果集),一个备用的总服务器(负责当总服务器宕机时替换总服务器),一个web的cgi(向总服务器发出搜索请求)。搜索引擎的服务器中的15个服务器提供搜索服务,5个服务器正在生成索引。这20个搜索引擎的服务器经常要让正在提供搜索服务的服务器停止提供服务开始生成索引,或生成索引的服务器已经把索引生成完成可以提供搜索服务了。使用Zookeeper可以保证总服务器自动感知有多少提供搜索引擎的服务器并向这些服务器发出搜索请求,当总服务器宕机时自动启用备用的总服务器。
环境变量设置
cd /home/test
tar -xf zookeeper-3.4.6.tar.gz
ln -s zookeeper-3.4.6 zookeeper
vim /etc/profile
export ZOOKEEPER_HOME=/home/test/zookeeper
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin
source /etc/profile
配置zoo.cfg文件
cd zookeeper/conf
mv zoo.cfg zoo.cfg_bak
mv zoo_sample.cfg zoo.cfg
cd ../
mkdir data
# 把 dataDir 那一行修改成自己的地址,在文件最后再添加三行server的配置,具体参考zoo.cfg_bak
[root@master conf]# vim zoo.cfg
dataDir=/home/test/zookeeper/data
server.0=tmp1:2888:3888
server.1=tmp2:2888:3888
server.2=tmp3:2888:3888
配置myid文件
cd ../data
echo 0 > myid
配置其他两个节点
cd ../../
scp -r zookeeper root@tmp2:`pwd`
scp -r zookeeper root@tmp3:`pwd`
ssh test@tmp2
#temp2配置zookeeper的环境变量(略)
echo 1 > /home/test/zookeeper/data/myid
ssh test@tmp3
#temp3配置zookeeper的环境变量(略)
echo 2 > /home/test/zookeeper/data/myid
测试
# 在三个节点上分别执行命令,启动服务: zkServer.sh start
# 在三个节点上分别执行命令,查看状态: zkServer.sh status
# 正确结果应该是:三个节点中其中一个是leader,另外两个是follower
# 在三个节点上分别执行命令: jps
# 检查三个节点是否都有QuromPeerMain进程
Kafka安装
简介:
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。Producer即生产者,向Kafka集群发送消息,在发送消息之前,会对消息进行分类,即主题(Topic),通过对消息指定主题可以将消息分类,消费者可以只关注自己需要的Topic中的消息。Consumer,即消费者,消费者通过与kafka集群建立长连接的方式,不断地从集群中拉取消息,然后可以对这些消息进行处理。
安装Scala
Kafka由Scala和Java编写,所以我们先需要安装配置Scala:
##三个节点都要安装##
tar -zxvf scala-2.11.8.tgz
ln -s scala-2.11.8 scala
##配置scala环境变量
export SCALA_HOME=/usr/local/scala/scala-2.11.8
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$SCALA_HOME/bin
source /etc/profile
scala -version
安装Kafka
tar -xf kafka_2.11-2.1.1.tgz
ln -s kafka_2.11-2.1.1 kafka
##配置kafka环境变量
export KAFKA_HOME=/home/test/kafka
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin:$SCALA_HOME/bin
source /etc/profile
# 修改server.properties文件,找到对应的位置,修改如下
vim kafka/config/server.properties
broker.id=0
listeners=PLAINTEXT://172.19.79.155:9092
advertised.listeners=PLAINTEXT://172.19.79.155:9092
zookeeper.connect=172.19.79.155:2181,172.19.79.156:2181,172.19.79.157:2181
##将文件复制到其余两节点
scp -r kafka test@tmp2:`pwd`
scp -r kafka test@tmp3:`pwd`
# 在另外两个节点上,对server.properties要有几处修改
# broker.id 分别修改成: 1 和 2
# listeners 在ip那里分别修改成子节点对应的,即 PLAINTEXT://172.19.79.156:9092 和 PLAINTEXT://172.19.79.157:9092
# advertised.listeners 也在ip那里分别修改成子节点对应的,即 PLAINTEXT://172.19.79.156:9092 和 PLAINTEXT://172.19.79.157:9092
# zookeeper.connect 不需要修改
# 另外两个节点配置kafka环境变量
测试
# 在三个节点都启动kafka
nohup kafka-server-start.sh /home/test/kafka/config/server.properties &
# 在主节点上创建主题TestTopic
kafka-topics.sh --zookeeper 172.19.79.155:2181,172.19.79.156:2181,172.19.79.157:2181 --topic TestTopic --replication-factor 1 --partitions 1 --create
# 在主节点上启动一个生产者
kafka-console-producer.sh --broker-list 172.19.79.155:9092,172.19.79.156:9092,172.19.79.157:9092 --topic TestTopic
# 在其他两个节点上分别创建消费者
kafka-console-consumer.sh --bootstrap-server 172.19.79.156:9092 --topic TestTopic --from-beginning
kafka-console-consumer.sh --bootstrap-server 172.19.79.157:9092 --topic TestTopic --from-beginning
# 在主节点生产者命令行那里随便输入一段话:
>hello
# 然后你就会发现在其他两个消费者节点那里也出现了这句话,即消费到了该数据
Flume安装
简介
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统),支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。
使用Flume,我们可以将从多个服务器中获取的数据迅速的移交给Hadoop中,可以高效率的将多个网站服务器中收集的日志信息存入HDFS/HBase中。
Flume环境变量配置
tar -xf apache-flume-1.9.0-bin.tar.gz
ln -s apache-flume-1.9.0-bin flume
## 环境变量
export FLUME_HOME=/homet/test/flume
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin:$SCALA_HOME/bin:$FLUME_HOME/bin
source /etc/profile
修改flume-conf.properties文件
cd /homet/test/flume/conf
mv flume-conf.properties.template flume-conf.properties
# 在文件最后加上下面的内容
# vim flume-conf.properties
#agent1表示代理名称
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
#配置source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/home/test/flume/logs
agent1.sources.source1.channels=channel1
agent1.sources.source1.fileHeader = false
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = timestamp
#配置channel1
agent1.channels.channel1.type=file
agent1.channels.channel1.checkpointDir=/home/test/flume/logs_tmp_cp
agent1.channels.channel1.dataDirs=/home/test/flume/logs_tmp
#配置sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://tmp1:9000/logs
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=1
agent1.sinks.sink1.channel=channel1
agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d
# 我们看到上面的配置文件中代理 agent1.sources.source1.spoolDir 监听的文件是/home/test/flume/logs,所以我们要手动创建一下
# cd ../..
# mkdir logs
# 上面的配置文件中 agent1.sinks.sink1.hdfs.path=hdfs://tmp1:9000/logs下,即将监听到的/home/test/flume/logs下的文件自动上传到hdfs的/logs下,所以我们要手动创建hdfs下的目录
# hdfs dfs -mkdir /logs
测试
#启动服务
flume-ng agent -n agent1 -c conf -f /usr/local/flume/conf/flume-conf.properties -Dflume.root.logger=DEBUG,console
# 先看下hdfs的logs目录下,目前什么都没有
# hdfs dfs -ls -R /
#vim /home/test/flume/log/flume_test.txt
123456
ggggg
hello
啊发发发
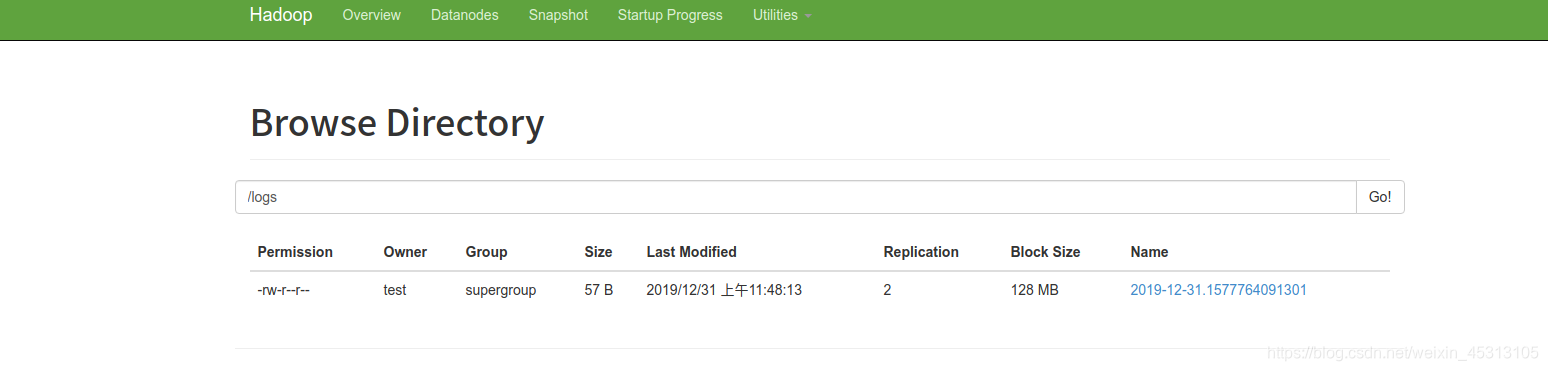
#然后我们发现hdfs的logs下自动上传了我们刚刚创建的文件
hdfs dfs -ls -R /
hdfs dfs -cat /logs/2019-12-30.1448242551358
Hbase安装
简介
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统。Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。
环境配置
tar -zxvf hbase-2.1.1-bin.tar.gz
ln -s hbase-2.1.1-bin hbase
#环境配置
export HBASE_HOME=/home/test/hbase
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin:$SCALA_HOME/bin:$FLUME_HOME/bin:$HBASE_HOME/bin
source /etc/profile
修改hbase-env.sh文件
cd hbase/conf
vim hbase-env.sh
export JAVA_HOME=/home/test/jdk1.8.0_191
export HBASE_LOG_DIR=${HBASE_HOME}/logs
export HBASE_MANAGES_ZK=false
修改hbase-site.xml 文件
vim hbase-site.xml
[root@master conf]# vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://tmp1:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>tmp1,tmp2,tmp3</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/test/zookeeper/data</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/test/hbase/data/tmp</value>
</property>
<property>
<name>hbase.master</name>
<value>hdfs://tmp1:60000</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<name>hbase.regionserver.info.port</name>
<value>16030</value>
</property>
</configuration>
修改regionservers文件
vim regionservers
tmp1
tmp2
tmp3
### 其他两个子节点的配置
cd ../.../
scp -r hbase root@tmp2:`pwd`
scp -r hbase root@tmp3:`pwd`
# 别忘在另外两个节点也要在/etc/profile下配置环境变量并source一下使生效!
# 在所有节点上都手动创建/home/test/hbase/data/tmp目录,也就是上面配置文件中hbase.tmp.dir属性的值,用来保存临时文件的。
测试:
# 注意:测试Hbase之前,zookeeper和hadoop需要提前启动起来
cd hbase/
bin/start-hbase.sh
jps
# 正确结果:主节点上显示:HMaster / 子节点上显示:HRegionServer
在主机浏览器上访问:http://172.19.79.155:16010
Spark安装
简介
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,是类似于Hadoop MapReduce的通用并行框架。Spark拥有Hadoop MapReduce所具有的优点,但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。Spark实际上是对Hadoop的一种补充,可以很好的在Hadoop 文件系统中并行运行。
环境配置
tar -xf spark-2.4.0-bin-hadoop2.7.tgz
ln -s spark-2.4.0-bin-hadoop2.7 spark
配置环境变量
export SPARK_HOME=/home/test/spark
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin:$SCALA_HOME/bin:$FLUME_HOME/bin:$HBASE_HOME/bin:$SPARK_HOME/bin
source /etc/profile
修改spark-env.sh文件
cd spark/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
export JAVA_HOME=/home/test/java/jdk1.8.0_191
export SCALA_HOME=/home/test/scala
export HADOOP_HOME=/home/test/hadoop
export HADOOP_CONF_DIR=/home/test/hadoop/etc/hadoop
修改slaves文件
mv slaves.template slaves
vim slaves
tmp1
tmp2
tmp3
在其余两个子节点上操作,配置节点之间的免密
scp -r hbase root@tmp2:`pwd`
scp -r hbase root@tmp3:`pwd`
注意:两个节点也要在/etc/profile下配置环境变量并source一下使生效
启动
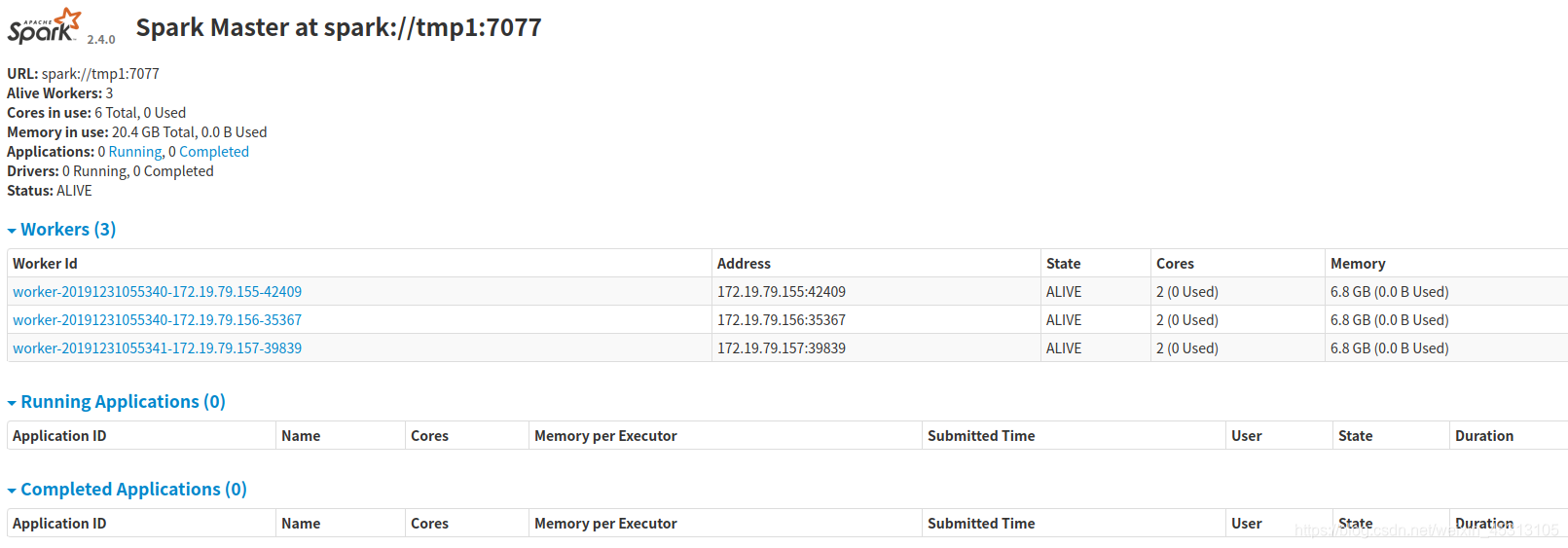
cd /ome/test/sapck/sbin && start-all.sh

















 1419
1419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









