







说明:本文目的记录使用idea搭建springboot项目,orm使用JPA框架过程,以及JPA的基本使用。
搭建项目
1.新建项目
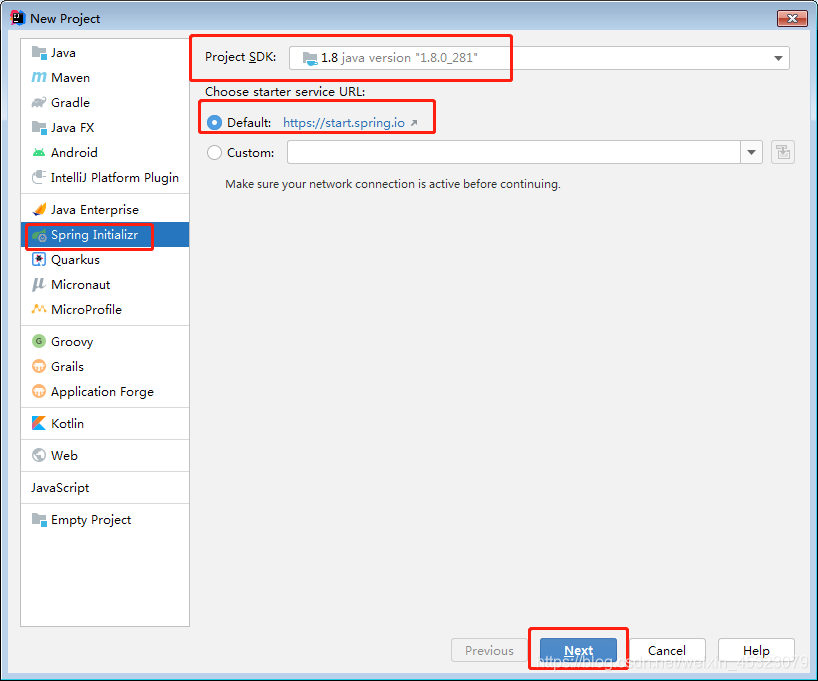
2.修改JDK版本号,包名,项目名等
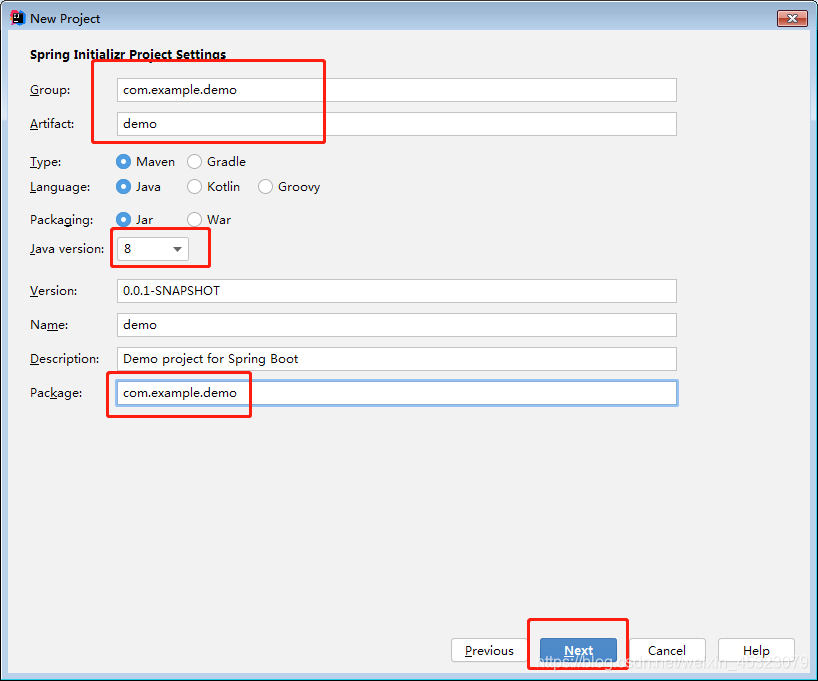
3.选择需要的依赖(lombok看个人喜不喜欢使用)

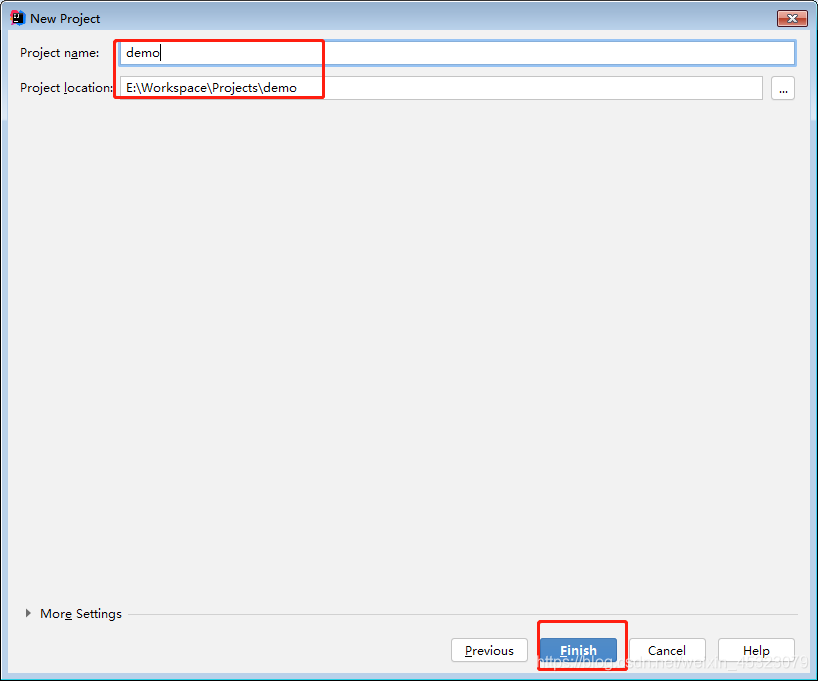
4.修改项目名和本地项目路径
5.新建完成后,项目结构和maven操作(maven最好是配置个人安装的maven,默认maven和本地仓库在C盘下)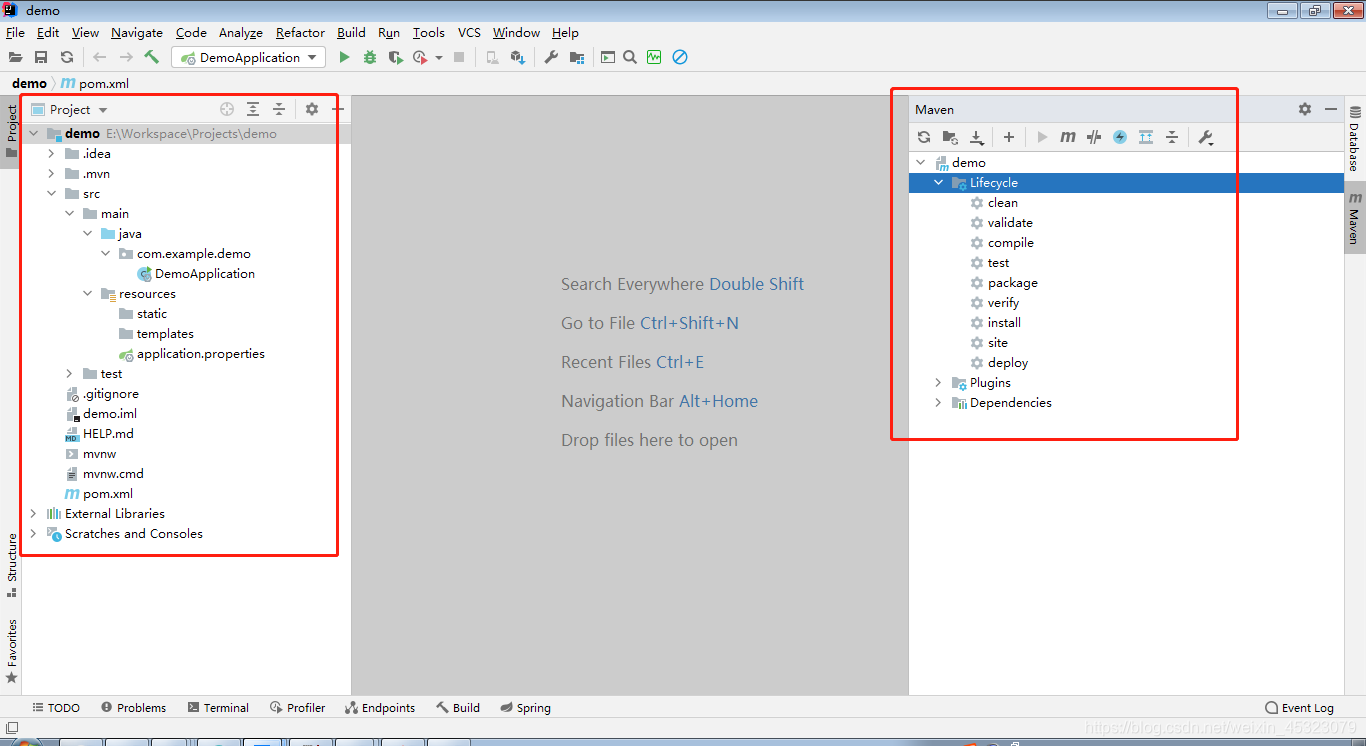
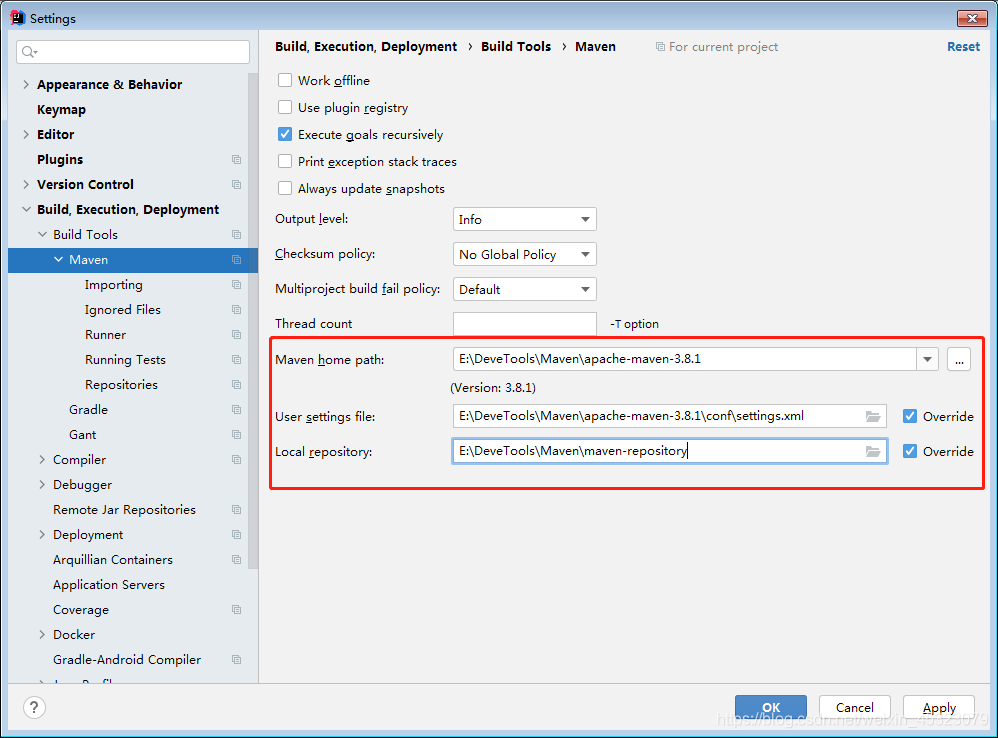
6.idea配置本地maven
7.idea配置数据库连接(目的是可以根据数据库生成实体类,dao接口)
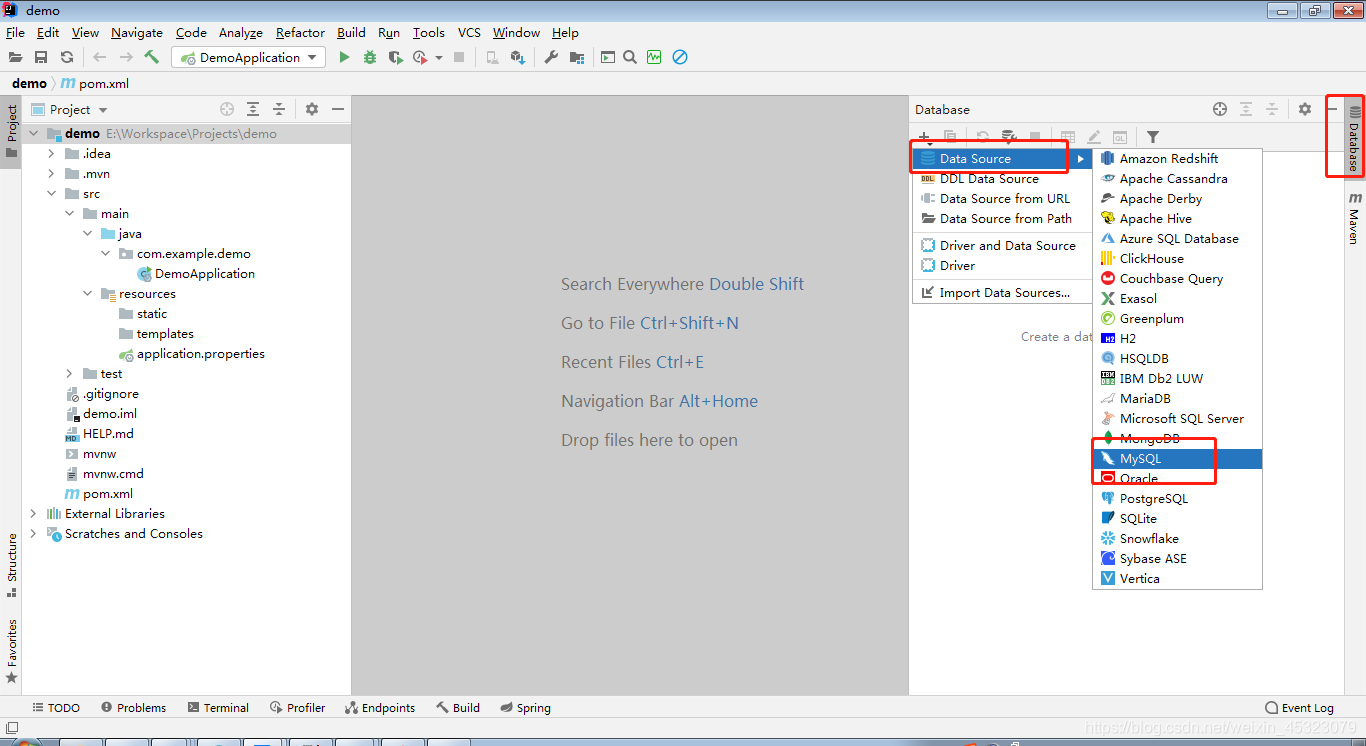
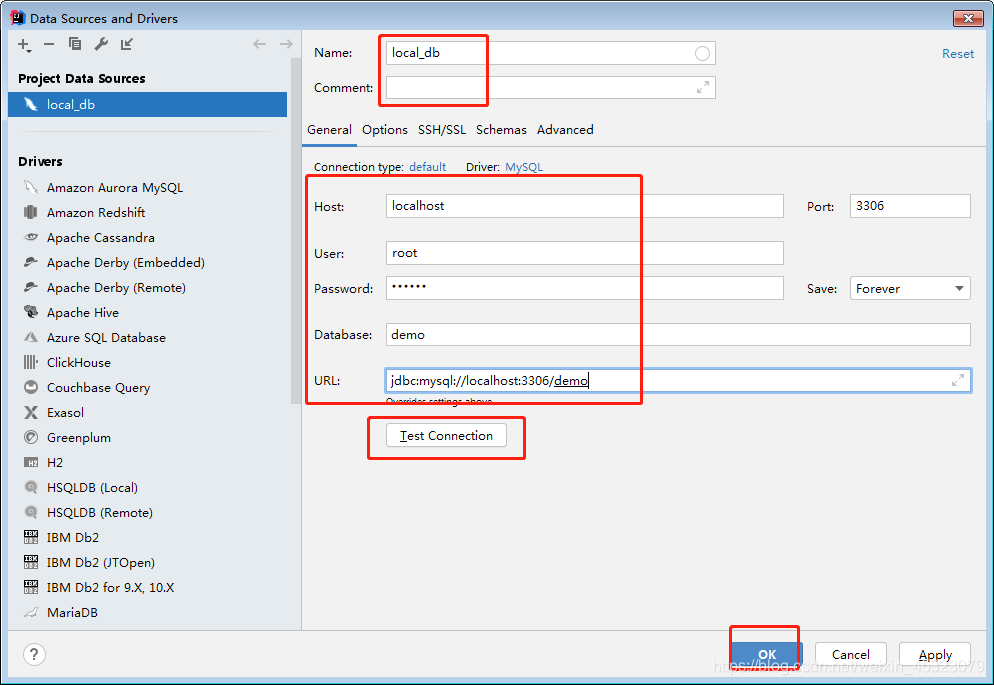
修改连接名称和描述,配置数据库用户名和密码,选择要连接的库名,点击测试连接,成功后确认即可。
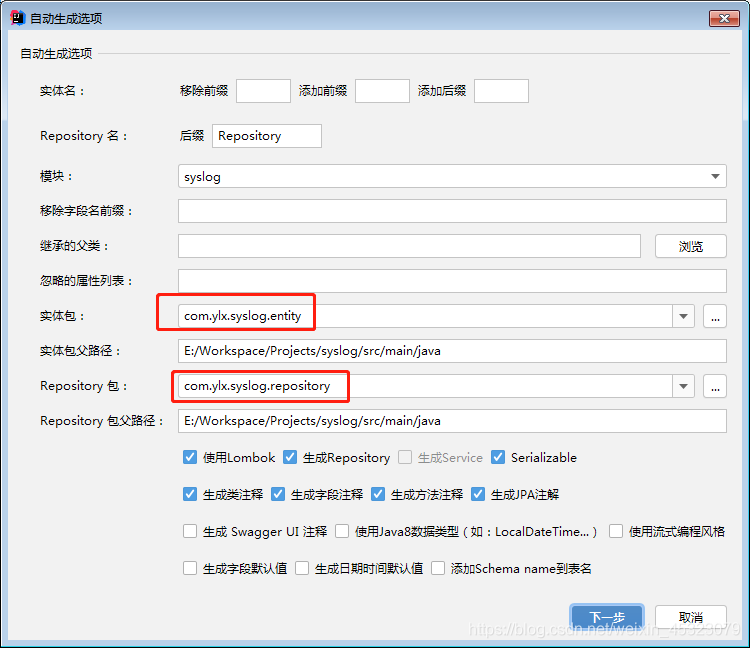
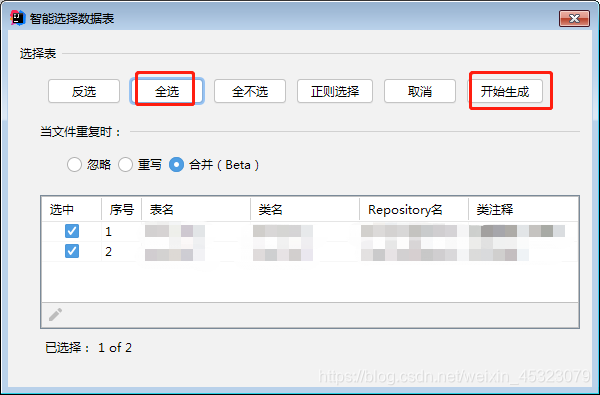
8.根据数据库表生成JPA实体和Repository(即dao)
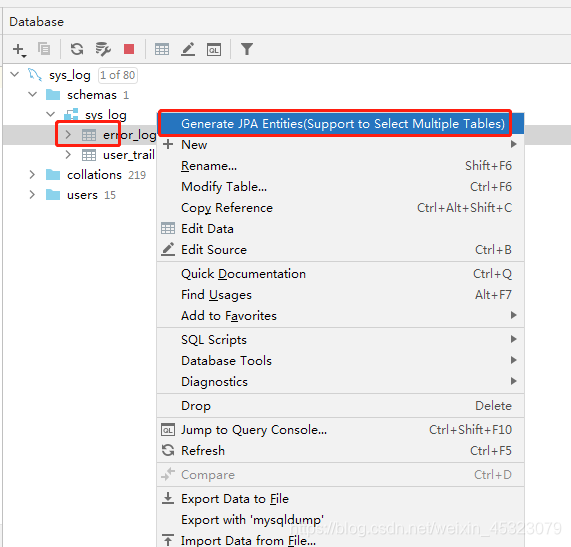
选择生成的实体和repository所在的包,点击下一步选择要生成的表,生成即可。
JPA 基本使用
1.生成的repository 已经继承了 JpaRepository<T, ID>, JpaSpecificationExecutor
JpaRepository<T, ID> 中的T为定义好的实体类类型,ID为该实体类的主键类型,JpaSpecificationExecutor 中的泛型T也一样,例:
# 实体
@Data
public class User {
Integer id;
String userName;
Integer age;
}
@Repository
public interface UserRepository extends JpaRepository<User, Integer>, JpaSpecificationExecutor<User> {
}
JpaRepository 接口中定义了绝大部分crud api 以供使用,如果想自定义sql或进行一些封装也可以在Repository 中自定义。
如果有分页需求,Repository 可以直接继承 JpaSpecificationExecutor 接口。
@Service
public class UserServiceImpl implements UserService{
@Autowired
UserRepository userRepository; // 用户信息相关操作
// 根据用户id查询用户信息
public Optional<User > findUserById(Integer userId){
return userRepository.findById(userId);
}
}
@Controller
public class UserController {
@Autowired
UserService userService; // 用户信息相关操作
public Object findUserById(@RequestParam Integer id){
Map<String, Object> resultMap = new HashMap<>();
Optional<User > opt = userService.findUserById(id);
if (opt.isPresent()){
resultMap.put("code","1");
resultMap.put("msg","获取成功");
resultMap.put("data",opt.get());
}else {
resultMap.put("code","-1");
resultMap.put("msg","id错误");
}
return resultMap;
}
}
JPA 查询根据主键查询是对结果做了封装,Optional 可以使用isPrsent() 方法来判断是否有满足条件的数据,有的话使用get()方法即可获取T对象。
2.条件查询和分页查询
# 根据用户姓名和年龄 分页获取用户信息集合
@Service
public UserServiceImpl implements UserService {
@Autowired
UserRepository userRepository; // 用户信息相关操作
public Page<User> findUserByCondition(GetUserRequest getUser){
Integer pageNum = 1;
Integer pageSize = 20;
if (getUser.getPageNum() != null && getUser.getPageNum() > 1){
pageNum = getUser.getPageNum();
}
// 组装分页
if (getUser.getPageSize() != null && getUser.getPageSize() != 0){
pageSize = getUser.getPageSize();
}
// 排序(按年龄倒序排序)
Sort sort = Sort.of(Sort.Direction.DESC, "age");
Pageable pageable = PageRequest.of(pageNum - 1, pageSize, sort);
Specification<GetUserRequest> confusion = new Specification<GetUserRequest>() {
// 组装筛选条件
@Override
public Predicate toPredicate(Root<User> root, CriteriaQuery<?> criteriaQuery,
CriteriaBuilder criteriaBuilder) {
List<Predicate> predicateList = new ArrayList<>();
// 姓名
if (getUser.getUserName() != null && !"".equals(getUserTrail.getUserName())) {
predicateList.add(criteriaBuilder.equal(root.get("userName"), getUser.getUserName()));
}
// 年龄
if (getUser.getAge != 0) {
predicateList.add(criteriaBuilder.equal(root.get("age"), getUser.geAge()));
}
// 用户id in
Path<Object> id = root.get("id");
CriteriaBuilder.In in = criteriaBuilder.in(id);
for (Integer userId: userIdList) {
in.value(userId);
}
predicateList.add(criteriaBuilder.and(in));
return criteriaBuilder.and(predicateList.toArray(new Predicate[predicateList.size()]));
}
};
return userRepository.findAll(confusion, pageable);
}
}
GetUserRequest 为自定义的请求参数,封装了用户姓名和年龄以及分页需要的参数。
# 封装了获取用户信息的请求参数
@Data
public class GetUserRequest {
String userName;
Integer age;
Integer pageNum;
Integer pageSize;
}
3.排序
- 在实现分页时,把排序规则放入PageRequest 的构造方法中。适合字段较少且排序规则一样的情况。
// 根据时间戳倒序 排序
Sort sort = Sort.by(Sort.Direction.DESC, "timestamp");
Pageable pageable = PageRequest.of(pageNum - 1,pageSize, sort);
- 多个字段排序规则不同时,使用Order 自定义每个字段的排序规则
Sort.Order nameOrder = new Sort.Order(Sort.Direction.DESC,"name");
Sort.Order ageOrder = new Sort.Order(Sort.Direction.ASC,"age");
List<Sort.Order> orderList = new ArrayList<>();
orderList.add(nameOrder);
orderList.add(ageOrder);
Sort sort = Sort.by(orderList);
Pageable pageable = PageRequest.of(pageNum - 1,pageSize, sort);
还有其他JPA API没有介绍到,可以自行在项目中查看api和源码。
以上代码绝大部分是临时手敲的,如果有错误的地方,还望大家指出。














 4265
4265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









