







 当源代码中找不到所需数据时,通过F12抓包工具定位数据包。在本例中,作者展示了如何处理首页无法直接抓取数据的情况,通过清除数据包并触发下一页加载来找到数据包。在确定URL和参数后,利用requests库编写代码,注意添加请求头防止防盗链。此外,文中提到对于此类问题,还可以使用selenium进行慢速但有效的抓取。
当源代码中找不到所需数据时,通过F12抓包工具定位数据包。在本例中,作者展示了如何处理首页无法直接抓取数据的情况,通过清除数据包并触发下一页加载来找到数据包。在确定URL和参数后,利用requests库编写代码,注意添加请求头防止防盗链。此外,文中提到对于此类问题,还可以使用selenium进行慢速但有效的抓取。
目录
一、思路
1.1输入网址,查看源代码
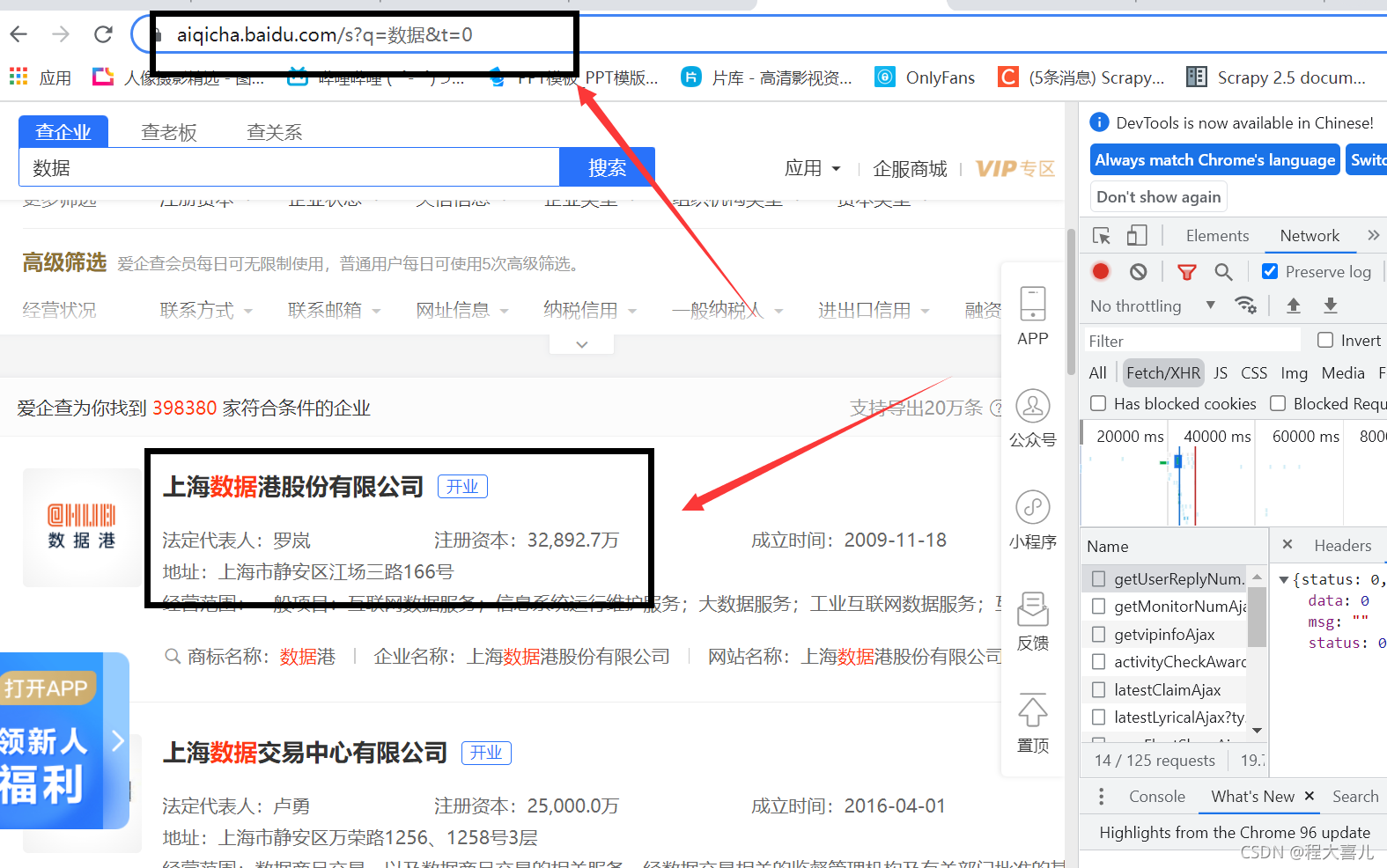
可以看到源代码中没有我们想要的数据,就需要考虑使用抓包工具,找到我们需要的数据包
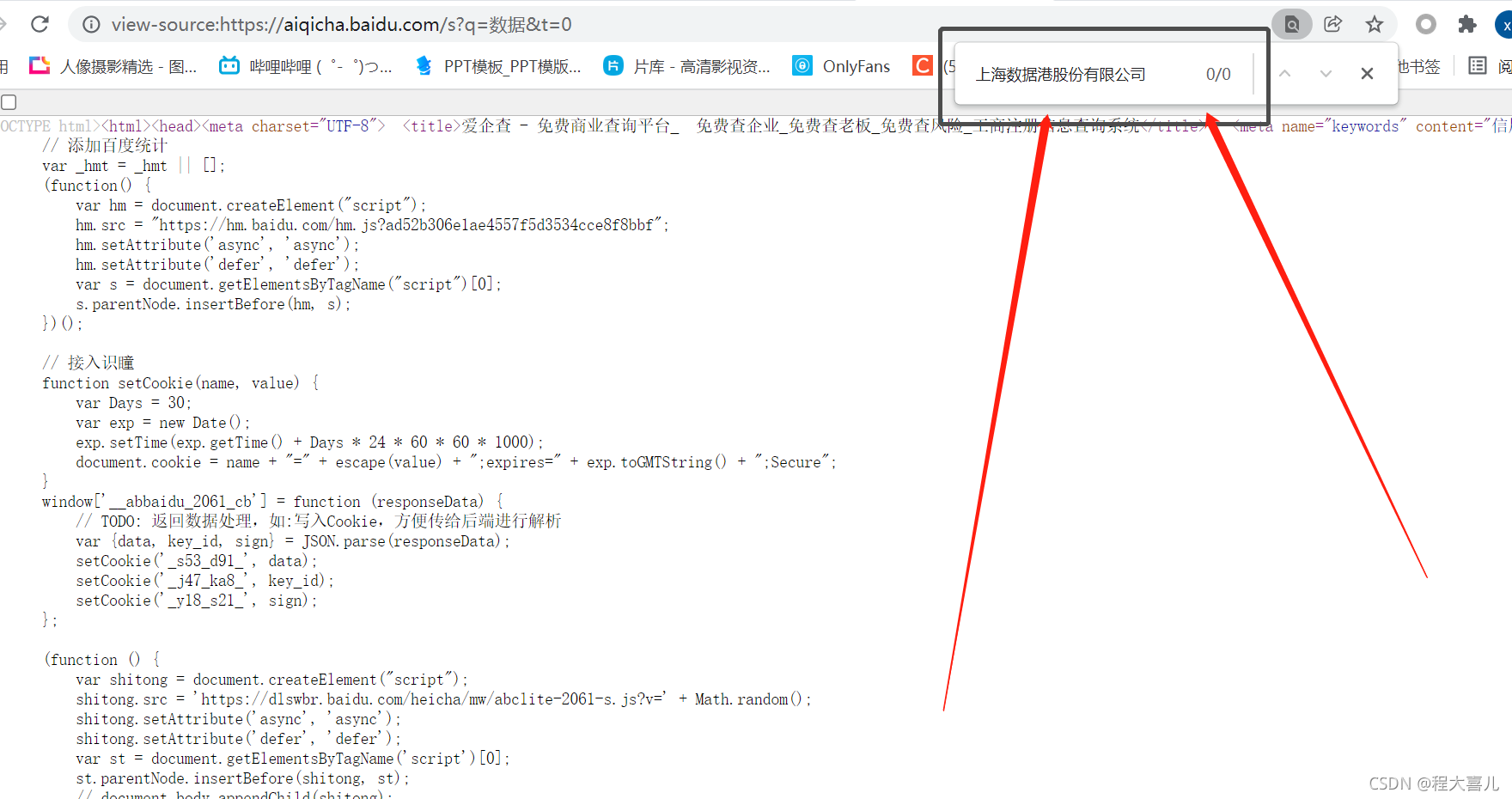
1.2 F12抓包,寻找数据包。
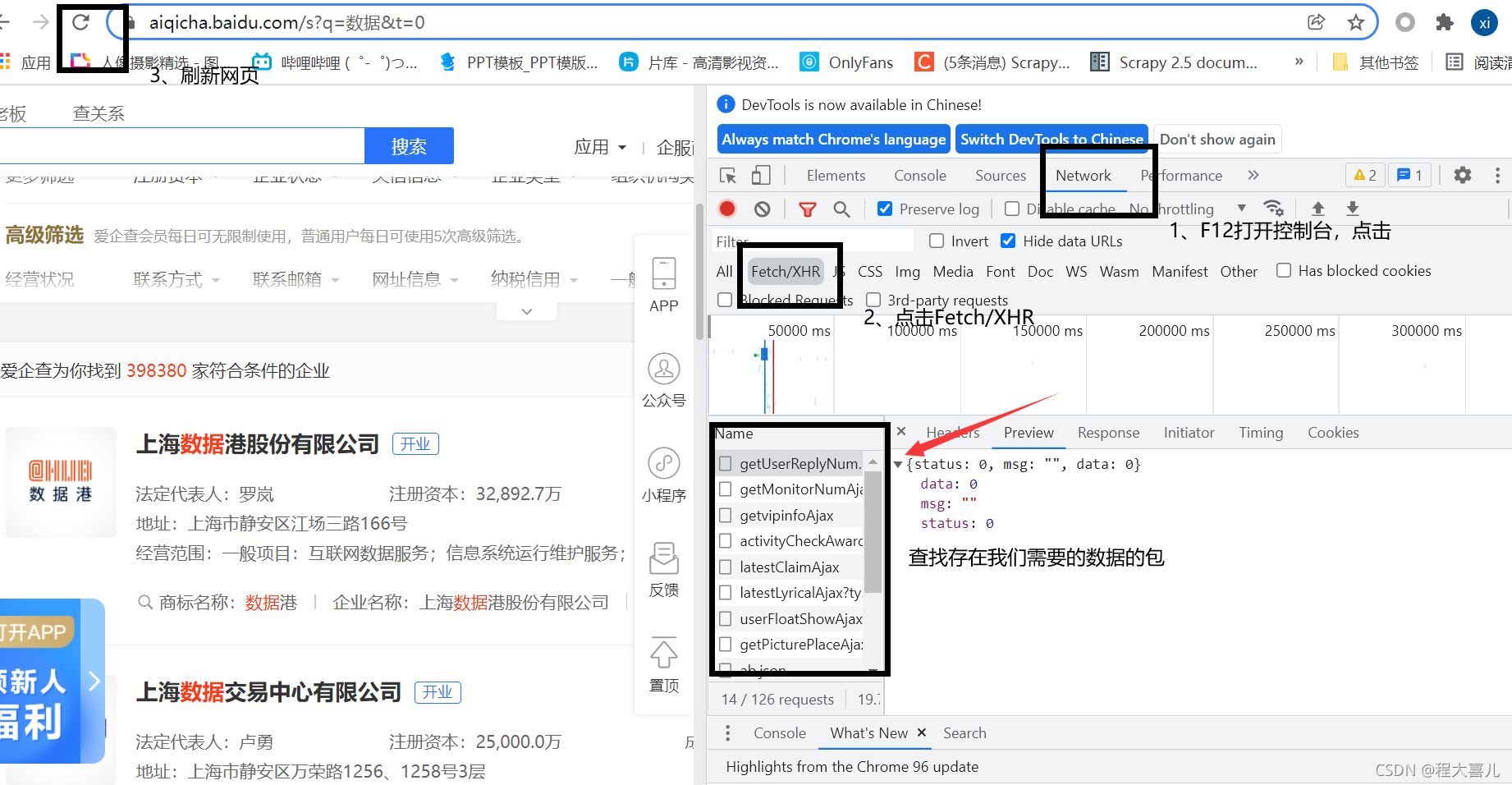
全部包都看了一遍,发现没有我们需要的包,那么数据跑哪去了呢?我尝试着,先清除数据包,然后点击下一页,果然,存在数据的包出现了,所以如果你也遇到过这种问题,不要急。
类似这种首页无法抓取的网页,
目录
可以看到源代码中没有我们想要的数据,就需要考虑使用抓包工具,找到我们需要的数据包
全部包都看了一遍,发现没有我们需要的包,那么数据跑哪去了呢?我尝试着,先清除数据包,然后点击下一页,果然,存在数据的包出现了,所以如果你也遇到过这种问题,不要急。
类似这种首页无法抓取的网页,
 7809
3万+
7809
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























